


注意
转到末尾 下载完整的示例代码。
使用 Ax 进行多目标 NAS#
创建于:2022年8月19日 | 最后更新:2024年7月31日 | 最后验证:2024年11月05日
作者: David Eriksson, Max Balandat,以及 Meta 的自适应实验团队。
在本教程中,我们将展示如何使用 Ax 在流行的 MNIST 数据集上为一个简单的神经网络模型运行多目标神经架构搜索 (NAS)。虽然底层方法通常用于更复杂的模型和更大的数据集,但我们选择了一个可在笔记本电脑上轻松端到端运行,耗时不到 20 分钟的教程。
在许多 NAS 应用中,多个关注的目标之间存在天然的权衡。例如,在设备上部署模型时,我们可能希望最大化模型性能(例如,准确率),同时最小化功率消耗、推理延迟或模型大小等竞争指标,以满足部署约束。通常,我们可以通过接受略微降低的模型性能来大幅降低计算需求或预测延迟。有效探索这些权衡的原则性方法是可扩展和可持续 AI 的关键推动因素,并在 Meta 取得了许多成功的应用——例如,参见我们关于自然语言理解模型的 案例研究。
在我们的示例中,我们将调整两个隐藏层的宽度、学习率、dropout 概率、批量大小以及训练 epoch 的数量。目标是权衡性能(验证集上的准确率)和模型大小(模型参数的数量)。
本教程使用了以下 PyTorch 库
PyTorch Lightning(指定模型和训练循环)
TorchX(用于远程/异步运行训练作业)
BoTorch(驱动 Ax 算法的贝叶斯优化库)
定义 TorchX 应用#
我们的目标是优化 mnist_train_nas.py 中定义的 PyTorch Lightning 训练作业。为了使用 TorchX 实现这一目标,我们编写了一个辅助函数,该函数接受训练作业的架构和超参数的值,并创建一个具有适当设置的 TorchX AppDef。
from pathlib import Path
import torchx
from torchx import specs
from torchx.components import utils
def trainer(
log_path: str,
hidden_size_1: int,
hidden_size_2: int,
learning_rate: float,
epochs: int,
dropout: float,
batch_size: int,
trial_idx: int = -1,
) -> specs.AppDef:
# define the log path so we can pass it to the TorchX ``AppDef``
if trial_idx >= 0:
log_path = Path(log_path).joinpath(str(trial_idx)).absolute().as_posix()
return utils.python(
# command line arguments to the training script
"--log_path",
log_path,
"--hidden_size_1",
str(hidden_size_1),
"--hidden_size_2",
str(hidden_size_2),
"--learning_rate",
str(learning_rate),
"--epochs",
str(epochs),
"--dropout",
str(dropout),
"--batch_size",
str(batch_size),
# other config options
name="trainer",
script="mnist_train_nas.py",
image=torchx.version.TORCHX_IMAGE,
)
设置 Runner#
Ax 的 Runner 抽象允许编写各种后端接口。Ax 已内置 TorchX 的 Runner,因此我们只需对其进行配置。在本教程中,我们在本地以完全异步的方式运行作业。
要在集群上启动它们,您可以改用不同的 TorchX 调度程序并相应地调整配置。例如,如果您有一个 Kubernetes 集群,只需将调度程序从 local_cwd 更改为 kubernetes)。
import tempfile
from ax.runners.torchx import TorchXRunner
# Make a temporary dir to log our results into
log_dir = tempfile.mkdtemp()
ax_runner = TorchXRunner(
tracker_base="/tmp/",
component=trainer,
# NOTE: To launch this job on a cluster instead of locally you can
# specify a different scheduler and adjust arguments appropriately.
scheduler="local_cwd",
component_const_params={"log_path": log_dir},
cfg={},
)
设置 SearchSpace#
首先,我们定义搜索空间。Ax 支持整数和浮点数类型的范围参数,以及可以具有非数值类型(如字符串)的选择参数。我们将把隐藏层大小、学习率、dropout 和 epoch 数量作为范围参数进行调整,并将批量大小作为有序选择参数进行调整,以强制其为 2 的幂。
from ax.core import (
ChoiceParameter,
ParameterType,
RangeParameter,
SearchSpace,
)
parameters = [
# NOTE: In a real-world setting, hidden_size_1 and hidden_size_2
# should probably be powers of 2, but in our simple example this
# would mean that ``num_params`` can't take on that many values, which
# in turn makes the Pareto frontier look pretty weird.
RangeParameter(
name="hidden_size_1",
lower=16,
upper=128,
parameter_type=ParameterType.INT,
log_scale=True,
),
RangeParameter(
name="hidden_size_2",
lower=16,
upper=128,
parameter_type=ParameterType.INT,
log_scale=True,
),
RangeParameter(
name="learning_rate",
lower=1e-4,
upper=1e-2,
parameter_type=ParameterType.FLOAT,
log_scale=True,
),
RangeParameter(
name="epochs",
lower=1,
upper=4,
parameter_type=ParameterType.INT,
),
RangeParameter(
name="dropout",
lower=0.0,
upper=0.5,
parameter_type=ParameterType.FLOAT,
),
ChoiceParameter( # NOTE: ``ChoiceParameters`` don't require log-scale
name="batch_size",
values=[32, 64, 128, 256],
parameter_type=ParameterType.INT,
is_ordered=True,
sort_values=True,
),
]
search_space = SearchSpace(
parameters=parameters,
# NOTE: In practice, it may make sense to add a constraint
# hidden_size_2 <= hidden_size_1
parameter_constraints=[],
)
设置 Metrics#
Ax 有一个 Metric 的概念,它定义了结果的属性以及如何获取这些结果的观察值。这允许例如编码数据如何从某些分布式执行后端获取并在传递给 Ax 之前进行后处理。
在本教程中,我们将使用 多目标优化,目标是最大化验证准确率并最小化模型参数数量。后者代表模型延迟的简单代理,对于小型 ML 模型来说,准确估算延迟很困难(在实际应用中,我们会在设备上运行模型时对延迟进行基准测试)。
在我们的示例中,TorchX 将在本地以完全异步的方式运行训练作业,并将结果写入基于 trial 索引的 log_dir(请参阅上面的 trainer() 函数)。我们将定义一个了解该日志目录的 metric 类。通过继承 TensorboardCurveMetric,我们可以免费获得读取和解析 TensorBoard 日志的逻辑。
from ax.metrics.tensorboard import TensorboardMetric
from tensorboard.backend.event_processing import plugin_event_multiplexer as event_multiplexer
class MyTensorboardMetric(TensorboardMetric):
# NOTE: We need to tell the new TensorBoard metric how to get the id /
# file handle for the TensorBoard logs from a trial. In this case
# our convention is to just save a separate file per trial in
# the prespecified log dir.
def _get_event_multiplexer_for_trial(self, trial):
mul = event_multiplexer.EventMultiplexer(max_reload_threads=20)
mul.AddRunsFromDirectory(Path(log_dir).joinpath(str(trial.index)).as_posix(), None)
mul.Reload()
return mul
# This indicates whether the metric is queryable while the trial is
# still running. We don't use this in the current tutorial, but Ax
# utilizes this to implement trial-level early-stopping functionality.
@classmethod
def is_available_while_running(cls):
return False
现在我们可以实例化准确率和模型参数数量的 metrics。这里的 curve_name 是 TensorBoard 日志中 metric 的名称,而 name 是 Ax 内部使用的 metric 名称。我们还指定了 lower_is_better 来指示两个 metric 的有利方向。
val_acc = MyTensorboardMetric(
name="val_acc",
tag="val_acc",
lower_is_better=False,
)
model_num_params = MyTensorboardMetric(
name="num_params",
tag="num_params",
lower_is_better=True,
)
设置 OptimizationConfig#
告诉 Ax 应该优化什么的机制是 OptimizationConfig。这里我们使用 MultiObjectiveOptimizationConfig,因为我们将进行多目标优化。
此外,Ax 支持通过指定目标阈值来对不同 metric 进行约束,这些阈值界定了我们希望探索的结果空间区域。对于这个例子,我们将约束验证准确率至少为 0.94(94%),模型参数数量最多为 80,000。
from ax.core import MultiObjective, Objective, ObjectiveThreshold
from ax.core.optimization_config import MultiObjectiveOptimizationConfig
opt_config = MultiObjectiveOptimizationConfig(
objective=MultiObjective(
objectives=[
Objective(metric=val_acc, minimize=False),
Objective(metric=model_num_params, minimize=True),
],
),
objective_thresholds=[
ObjectiveThreshold(metric=val_acc, bound=0.94, relative=False),
ObjectiveThreshold(metric=model_num_params, bound=80_000, relative=False),
],
)
创建 Ax Experiment#
在 Ax 中,Experiment 对象是存储问题设置所有信息的对象。
from ax.core import Experiment
experiment = Experiment(
name="torchx_mnist",
search_space=search_space,
optimization_config=opt_config,
runner=ax_runner,
)
选择 Generation Strategy#
a GenerationStrategy 是我们希望执行优化的抽象表示。虽然可以自定义(如果您想这样做,请参阅 本教程),但在大多数情况下,Ax 可以根据搜索空间、优化配置以及我们想要运行的总 trial 数自动确定合适的策略。
通常,Ax 选择在开始基于模型的贝叶斯优化策略之前评估一些随机配置。
total_trials = 48 # total evaluation budget
from ax.modelbridge.dispatch_utils import choose_generation_strategy
gs = choose_generation_strategy(
search_space=experiment.search_space,
optimization_config=experiment.optimization_config,
num_trials=total_trials,
)
[INFO 10-15 19:13:00] ax.modelbridge.dispatch_utils: Using Models.BOTORCH_MODULAR since there is at least one ordered parameter and there are no unordered categorical parameters.
[INFO 10-15 19:13:00] ax.modelbridge.dispatch_utils: Calculating the number of remaining initialization trials based on num_initialization_trials=None max_initialization_trials=None num_tunable_parameters=6 num_trials=48 use_batch_trials=False
[INFO 10-15 19:13:00] ax.modelbridge.dispatch_utils: calculated num_initialization_trials=9
[INFO 10-15 19:13:00] ax.modelbridge.dispatch_utils: num_completed_initialization_trials=0 num_remaining_initialization_trials=9
[INFO 10-15 19:13:00] ax.modelbridge.dispatch_utils: `verbose`, `disable_progbar`, and `jit_compile` are not yet supported when using `choose_generation_strategy` with ModularBoTorchModel, dropping these arguments.
[INFO 10-15 19:13:00] ax.modelbridge.dispatch_utils: Using Bayesian Optimization generation strategy: GenerationStrategy(name='Sobol+BoTorch', steps=[Sobol for 9 trials, BoTorch for subsequent trials]). Iterations after 9 will take longer to generate due to model-fitting.
配置 Scheduler#
The Scheduler acts as the loop control for the optimization. It communicates with the backend to launch trials, check their status, and retrieve results. In the case of this tutorial, it is simply reading and parsing the locally saved logs. In a remote execution setting, it would call APIs. The following illustration from the Ax Scheduler tutorial summarizes how the Scheduler interacts with external systems used to run trial evaluations
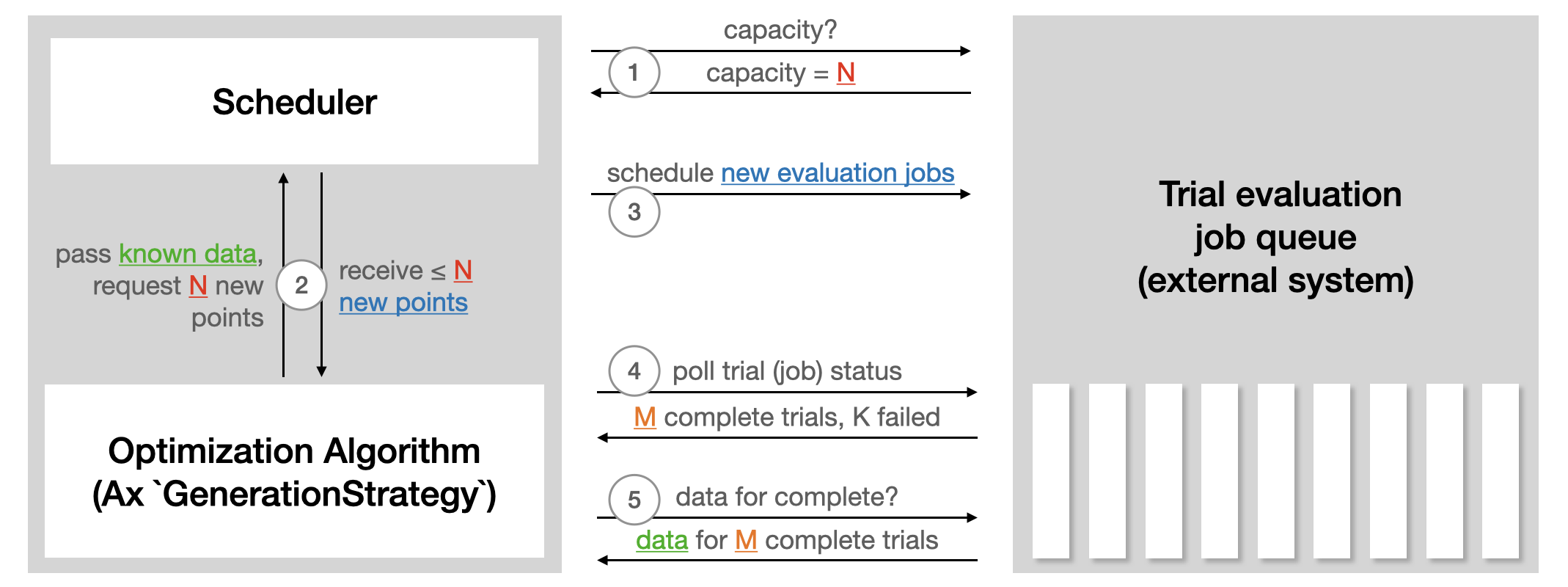
The Scheduler requires the Experiment and the GenerationStrategy. A set of options can be passed in via SchedulerOptions. Here, we configure the number of total evaluations as well as max_pending_trials, the maximum number of trials that should run concurrently. In our local setting, this is the number of training jobs running as individual processes, while in a remote execution setting, this would be the number of machines you want to use in parallel.
from ax.service.scheduler import Scheduler, SchedulerOptions
scheduler = Scheduler(
experiment=experiment,
generation_strategy=gs,
options=SchedulerOptions(
total_trials=total_trials, max_pending_trials=4
),
)
[WARNING 10-15 19:13:00] ax.service.utils.with_db_settings_base: Ax currently requires a sqlalchemy version below 2.0. This will be addressed in a future release. Disabling SQL storage in Ax for now, if you would like to use SQL storage please install Ax with mysql extras via `pip install ax-platform[mysql]`.
[INFO 10-15 19:13:00] Scheduler: `Scheduler` requires experiment to have immutable search space and optimization config. Setting property immutable_search_space_and_opt_config to `True` on experiment.
运行优化#
现在一切都已配置好,我们可以让 Ax 以全自动的方式运行优化。Scheduler 会定期检查所有当前正在运行的 trial 的状态日志,如果一个 trial 完成,Scheduler 就会在 Experiment 上更新其状态,并获取贝叶斯优化算法所需的观察值。
scheduler.run_all_trials()
[INFO 10-15 19:13:00] Scheduler: Fetching data for newly completed trials: [].
/usr/local/lib/python3.10/dist-packages/ax/modelbridge/cross_validation.py:463: UserWarning:
Encountered exception in computing model fit quality: RandomModelBridge does not support prediction.
[INFO 10-15 19:13:00] Scheduler: Running trials [0]...
/usr/local/lib/python3.10/dist-packages/ax/modelbridge/cross_validation.py:463: UserWarning:
Encountered exception in computing model fit quality: RandomModelBridge does not support prediction.
[INFO 10-15 19:13:01] Scheduler: Running trials [1]...
/usr/local/lib/python3.10/dist-packages/ax/modelbridge/cross_validation.py:463: UserWarning:
Encountered exception in computing model fit quality: RandomModelBridge does not support prediction.
[INFO 10-15 19:13:02] Scheduler: Running trials [2]...
/usr/local/lib/python3.10/dist-packages/ax/modelbridge/cross_validation.py:463: UserWarning:
Encountered exception in computing model fit quality: RandomModelBridge does not support prediction.
[INFO 10-15 19:13:03] Scheduler: Running trials [3]...
[INFO 10-15 19:13:04] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:13:04] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 4).
[INFO 10-15 19:13:05] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:13:05] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 4).
[INFO 10-15 19:13:07] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:13:07] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 4).
[INFO 10-15 19:13:09] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:13:09] Scheduler: Retrieved FAILED trials: [0].
/usr/local/lib/python3.10/dist-packages/ax/modelbridge/cross_validation.py:463: UserWarning:
Encountered exception in computing model fit quality: RandomModelBridge does not support prediction.
[INFO 10-15 19:13:09] Scheduler: Running trials [4]...
[INFO 10-15 19:13:10] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:13:10] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 4).
[INFO 10-15 19:13:11] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:13:11] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 4).
[INFO 10-15 19:13:13] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:13:13] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 4).
[INFO 10-15 19:13:15] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:13:15] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 4).
[INFO 10-15 19:13:18] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:13:18] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 4).
[INFO 10-15 19:13:23] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:13:23] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 4).
[INFO 10-15 19:13:31] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:13:31] Scheduler: Waiting for completed trials (for 11 sec, currently running trials: 4).
[INFO 10-15 19:13:42] Scheduler: Fetching data for newly completed trials: [2].
[INFO 10-15 19:13:42] Scheduler: Retrieved COMPLETED trials: [2].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/modelbridge/cross_validation.py:463: UserWarning:
Encountered exception in computing model fit quality: RandomModelBridge does not support prediction.
[INFO 10-15 19:13:42] Scheduler: Running trials [5]...
[INFO 10-15 19:13:43] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:13:43] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 4).
[INFO 10-15 19:13:44] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:13:44] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 4).
[INFO 10-15 19:13:46] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:13:46] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 4).
[INFO 10-15 19:13:48] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:13:48] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 4).
[INFO 10-15 19:13:52] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:13:52] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 4).
[INFO 10-15 19:13:57] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:13:57] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 4).
[INFO 10-15 19:14:04] Scheduler: Fetching data for newly completed trials: 3 - 4.
[INFO 10-15 19:14:04] Scheduler: Retrieved COMPLETED trials: 3 - 4.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/modelbridge/cross_validation.py:463: UserWarning:
Encountered exception in computing model fit quality: RandomModelBridge does not support prediction.
[INFO 10-15 19:14:04] Scheduler: Running trials [6]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/modelbridge/cross_validation.py:463: UserWarning:
Encountered exception in computing model fit quality: RandomModelBridge does not support prediction.
[INFO 10-15 19:14:05] Scheduler: Running trials [7]...
[INFO 10-15 19:14:06] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:14:06] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 4).
[INFO 10-15 19:14:07] Scheduler: Fetching data for newly completed trials: [1].
[INFO 10-15 19:14:07] Scheduler: Retrieved COMPLETED trials: [1].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/modelbridge/cross_validation.py:463: UserWarning:
Encountered exception in computing model fit quality: RandomModelBridge does not support prediction.
[INFO 10-15 19:14:07] Scheduler: Running trials [8]...
[INFO 10-15 19:14:08] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:14:08] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 4).
[INFO 10-15 19:14:09] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:14:09] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 4).
[INFO 10-15 19:14:11] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:14:11] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 4).
[INFO 10-15 19:14:13] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:14:13] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 4).
[INFO 10-15 19:14:17] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:14:17] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 4).
[INFO 10-15 19:14:22] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:14:22] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 4).
[INFO 10-15 19:14:29] Scheduler: Fetching data for newly completed trials: [5, 7].
[INFO 10-15 19:14:29] Scheduler: Retrieved COMPLETED trials: [5, 7].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/modelbridge/cross_validation.py:463: UserWarning:
Encountered exception in computing model fit quality: RandomModelBridge does not support prediction.
[INFO 10-15 19:14:29] Scheduler: Running trials [9]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:14:33] Scheduler: Running trials [10]...
[INFO 10-15 19:14:34] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:14:34] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 4).
[INFO 10-15 19:14:35] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:14:35] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 4).
[INFO 10-15 19:14:36] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:14:36] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 4).
[INFO 10-15 19:14:38] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:14:38] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 4).
[INFO 10-15 19:14:42] Scheduler: Fetching data for newly completed trials: [8].
[INFO 10-15 19:14:42] Scheduler: Retrieved COMPLETED trials: [8].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:14:45] Scheduler: Running trials [11]...
[INFO 10-15 19:14:46] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:14:46] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 4).
[INFO 10-15 19:14:47] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:14:47] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 4).
[INFO 10-15 19:14:49] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:14:49] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 4).
[INFO 10-15 19:14:51] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:14:51] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 4).
[INFO 10-15 19:14:54] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:14:54] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 4).
[INFO 10-15 19:14:59] Scheduler: Fetching data for newly completed trials: [6].
[INFO 10-15 19:14:59] Scheduler: Retrieved COMPLETED trials: [6].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:15:03] Scheduler: Running trials [12]...
[INFO 10-15 19:15:04] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:15:04] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 4).
[INFO 10-15 19:15:05] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:15:05] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 4).
[INFO 10-15 19:15:06] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:15:06] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 4).
[INFO 10-15 19:15:09] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:15:09] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 4).
[INFO 10-15 19:15:12] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:15:12] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 4).
[INFO 10-15 19:15:17] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:15:17] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 4).
[INFO 10-15 19:15:25] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:15:25] Scheduler: Waiting for completed trials (for 11 sec, currently running trials: 4).
[INFO 10-15 19:15:36] Scheduler: Fetching data for newly completed trials: 9 - 10.
[INFO 10-15 19:15:36] Scheduler: Retrieved COMPLETED trials: 9 - 10.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:15:40] Scheduler: Running trials [13]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:15:43] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:15:43] Scheduler: Fetching data for newly completed trials: [11].
[INFO 10-15 19:15:43] Scheduler: Retrieved COMPLETED trials: [11].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:15:48] Scheduler: Running trials [14]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:15:51] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:15:51] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:15:51] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 10-15 19:15:52] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:15:52] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 10-15 19:15:53] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:15:53] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 10-15 19:15:56] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:15:56] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 10-15 19:15:59] Scheduler: Fetching data for newly completed trials: [12].
[INFO 10-15 19:15:59] Scheduler: Retrieved COMPLETED trials: [12].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:16:05] Scheduler: Running trials [15]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:16:10] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:16:10] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:16:10] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 10-15 19:16:11] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:16:11] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 10-15 19:16:13] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:16:13] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 10-15 19:16:15] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:16:15] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 10-15 19:16:18] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:16:18] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 10-15 19:16:23] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:16:23] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 3).
[INFO 10-15 19:16:31] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:16:31] Scheduler: Waiting for completed trials (for 11 sec, currently running trials: 3).
[INFO 10-15 19:16:42] Scheduler: Fetching data for newly completed trials: 13 - 14.
[INFO 10-15 19:16:42] Scheduler: Retrieved COMPLETED trials: 13 - 14.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:16:48] Scheduler: Running trials [16]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:16:55] Scheduler: Running trials [17]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:16:59] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:16:59] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:16:59] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 10-15 19:17:00] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:17:00] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 10-15 19:17:01] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:17:01] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 10-15 19:17:04] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:17:04] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 10-15 19:17:07] Scheduler: Fetching data for newly completed trials: [15].
[INFO 10-15 19:17:07] Scheduler: Retrieved COMPLETED trials: [15].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:17:13] Scheduler: Running trials [18]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:17:17] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:17:17] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:17:17] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 10-15 19:17:18] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:17:18] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 10-15 19:17:20] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:17:20] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 10-15 19:17:22] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:17:22] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 10-15 19:17:26] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:17:26] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 10-15 19:17:31] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:17:31] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 3).
[INFO 10-15 19:17:38] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:17:38] Scheduler: Waiting for completed trials (for 11 sec, currently running trials: 3).
[INFO 10-15 19:17:50] Scheduler: Fetching data for newly completed trials: 16 - 17.
[INFO 10-15 19:17:50] Scheduler: Retrieved COMPLETED trials: 16 - 17.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:17:59] Scheduler: Running trials [19]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:18:09] Scheduler: Running trials [20]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:18:14] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:18:14] Scheduler: Fetching data for newly completed trials: [18].
[INFO 10-15 19:18:14] Scheduler: Retrieved COMPLETED trials: [18].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:18:23] Scheduler: Running trials [21]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:18:30] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:18:30] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:18:30] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 10-15 19:18:31] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:18:31] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 10-15 19:18:32] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:18:32] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 10-15 19:18:35] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:18:35] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 10-15 19:18:38] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:18:38] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 10-15 19:18:43] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:18:43] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 3).
[INFO 10-15 19:18:51] Scheduler: Fetching data for newly completed trials: [21].
[INFO 10-15 19:18:51] Scheduler: Retrieved COMPLETED trials: [21].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:19:03] Scheduler: Running trials [22]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:19:11] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:19:11] Scheduler: Fetching data for newly completed trials: [19].
[INFO 10-15 19:19:11] Scheduler: Retrieved COMPLETED trials: [19].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:19:19] Scheduler: Running trials [23]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:19:24] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:19:24] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:19:24] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 10-15 19:19:25] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:19:25] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 10-15 19:19:26] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:19:26] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 10-15 19:19:29] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:19:29] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 10-15 19:19:32] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:19:32] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 10-15 19:19:37] Scheduler: Fetching data for newly completed trials: [20].
[INFO 10-15 19:19:37] Scheduler: Retrieved COMPLETED trials: [20].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:19:50] Scheduler: Running trials [24]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:19:54] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:19:54] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:19:54] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 10-15 19:19:55] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:19:55] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 10-15 19:19:56] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:19:56] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 10-15 19:19:58] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:19:58] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 10-15 19:20:02] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:20:02] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 10-15 19:20:07] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:20:07] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 3).
[INFO 10-15 19:20:14] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:20:14] Scheduler: Waiting for completed trials (for 11 sec, currently running trials: 3).
[INFO 10-15 19:20:26] Scheduler: Fetching data for newly completed trials: [23].
[INFO 10-15 19:20:26] Scheduler: Retrieved COMPLETED trials: [23].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:20:37] Scheduler: Running trials [25]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:20:45] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:20:45] Scheduler: Fetching data for newly completed trials: [22].
[INFO 10-15 19:20:45] Scheduler: Retrieved COMPLETED trials: [22].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:21:00] Scheduler: Running trials [26]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:21:05] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:21:05] Scheduler: Fetching data for newly completed trials: [24].
[INFO 10-15 19:21:05] Scheduler: Retrieved COMPLETED trials: [24].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:21:18] Scheduler: Running trials [27]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:21:25] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:21:25] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:21:25] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 10-15 19:21:26] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:21:26] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 10-15 19:21:27] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:21:27] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 10-15 19:21:29] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:21:29] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 10-15 19:21:33] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:21:33] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 10-15 19:21:38] Scheduler: Fetching data for newly completed trials: [25].
[INFO 10-15 19:21:38] Scheduler: Retrieved COMPLETED trials: [25].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:21:47] Scheduler: Running trials [28]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:21:52] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:21:52] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:21:52] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 10-15 19:21:53] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:21:53] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 10-15 19:21:55] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:21:55] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 10-15 19:21:57] Scheduler: Fetching data for newly completed trials: [26].
[INFO 10-15 19:21:57] Scheduler: Retrieved COMPLETED trials: [26].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:22:10] Scheduler: Running trials [29]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:22:19] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:22:19] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:22:19] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 10-15 19:22:20] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:22:20] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 10-15 19:22:21] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:22:21] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 10-15 19:22:24] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:22:24] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 10-15 19:22:27] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:22:27] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 10-15 19:22:32] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:22:32] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 3).
[INFO 10-15 19:22:40] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:22:40] Scheduler: Waiting for completed trials (for 11 sec, currently running trials: 3).
[INFO 10-15 19:22:51] Scheduler: Fetching data for newly completed trials: 27 - 28.
[INFO 10-15 19:22:51] Scheduler: Retrieved COMPLETED trials: 27 - 28.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:22:59] Scheduler: Running trials [30]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:23:09] Scheduler: Running trials [31]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:23:13] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:23:13] Scheduler: Fetching data for newly completed trials: [29].
[INFO 10-15 19:23:13] Scheduler: Retrieved COMPLETED trials: [29].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:23:24] Scheduler: Running trials [32]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:23:31] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:23:31] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:23:31] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 10-15 19:23:32] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:23:32] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 10-15 19:23:34] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:23:34] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 10-15 19:23:36] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:23:36] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 10-15 19:23:39] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:23:39] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 10-15 19:23:44] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:23:44] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 3).
[INFO 10-15 19:23:52] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:23:52] Scheduler: Waiting for completed trials (for 11 sec, currently running trials: 3).
[INFO 10-15 19:24:03] Scheduler: Fetching data for newly completed trials: [30].
[INFO 10-15 19:24:03] Scheduler: Retrieved COMPLETED trials: [30].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:24:18] Scheduler: Running trials [33]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:24:28] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:24:28] Scheduler: Fetching data for newly completed trials: [31].
[INFO 10-15 19:24:28] Scheduler: Retrieved COMPLETED trials: [31].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:24:42] Scheduler: Running trials [34]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:24:51] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:24:51] Scheduler: Fetching data for newly completed trials: 32 - 33.
[INFO 10-15 19:24:52] Scheduler: Retrieved COMPLETED trials: 32 - 33.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:25:02] Scheduler: Running trials [35]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:25:16] Scheduler: Running trials [36]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:25:24] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:25:24] Scheduler: Fetching data for newly completed trials: [34].
[INFO 10-15 19:25:24] Scheduler: Retrieved COMPLETED trials: [34].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:25:45] Scheduler: Running trials [37]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:26:00] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:26:00] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:26:00] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 10-15 19:26:01] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:26:01] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 10-15 19:26:02] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:26:02] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 10-15 19:26:04] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:26:04] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 10-15 19:26:08] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:26:08] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 10-15 19:26:13] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:26:13] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 3).
[INFO 10-15 19:26:21] Scheduler: Fetching data for newly completed trials: 35 - 36.
[INFO 10-15 19:26:21] Scheduler: Retrieved COMPLETED trials: 35 - 36.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:26:34] Scheduler: Running trials [38]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:26:48] Scheduler: Running trials [39]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:26:57] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:26:57] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:26:57] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 10-15 19:26:58] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:26:58] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 10-15 19:27:00] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:27:00] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 10-15 19:27:02] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:27:02] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 10-15 19:27:05] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:27:05] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 10-15 19:27:11] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:27:11] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 3).
[INFO 10-15 19:27:18] Scheduler: Fetching data for newly completed trials: [37].
[INFO 10-15 19:27:18] Scheduler: Retrieved COMPLETED trials: [37].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:27:33] Scheduler: Running trials [40]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:27:44] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:27:44] Scheduler: Fetching data for newly completed trials: [38].
[INFO 10-15 19:27:44] Scheduler: Retrieved COMPLETED trials: [38].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:27:54] Scheduler: Running trials [41]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:28:00] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:28:00] Scheduler: Fetching data for newly completed trials: [39].
[INFO 10-15 19:28:00] Scheduler: Retrieved COMPLETED trials: [39].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:28:15] Scheduler: Running trials [42]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:28:24] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:28:24] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:28:24] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 10-15 19:28:25] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:28:25] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 10-15 19:28:26] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:28:26] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 10-15 19:28:29] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:28:29] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 10-15 19:28:32] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:28:32] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 10-15 19:28:37] Scheduler: Fetching data for newly completed trials: [40].
[INFO 10-15 19:28:37] Scheduler: Retrieved COMPLETED trials: [40].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:28:47] Scheduler: Running trials [43]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:28:54] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:28:54] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:28:54] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 10-15 19:28:55] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:28:55] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 10-15 19:28:57] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:28:57] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 10-15 19:28:59] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:28:59] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 10-15 19:29:03] Scheduler: Fetching data for newly completed trials: [41].
[INFO 10-15 19:29:03] Scheduler: Retrieved COMPLETED trials: [41].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/linear_operator/utils/cholesky.py:40: NumericalWarning:
A not p.d., added jitter of 1.0e-08 to the diagonal
[INFO 10-15 19:29:14] Scheduler: Running trials [44]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:29:22] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:29:22] Scheduler: Fetching data for newly completed trials: [42].
[INFO 10-15 19:29:22] Scheduler: Retrieved COMPLETED trials: [42].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:29:34] Scheduler: Running trials [45]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:29:44] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:29:44] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:29:44] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 10-15 19:29:45] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:29:45] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 10-15 19:29:46] Scheduler: Fetching data for newly completed trials: [43].
[INFO 10-15 19:29:46] Scheduler: Retrieved COMPLETED trials: [43].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:30:00] Scheduler: Running trials [46]...
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:30:09] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 10-15 19:30:09] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:30:09] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 10-15 19:30:10] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:30:10] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 10-15 19:30:12] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:30:12] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 10-15 19:30:14] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:30:14] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 10-15 19:30:17] Scheduler: Fetching data for newly completed trials: [44].
[INFO 10-15 19:30:17] Scheduler: Retrieved COMPLETED trials: [44].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:30:28] Scheduler: Running trials [47]...
[INFO 10-15 19:30:29] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:30:29] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 10-15 19:30:30] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:30:30] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 10-15 19:30:31] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:30:31] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 10-15 19:30:33] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:30:33] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 10-15 19:30:37] Scheduler: Fetching data for newly completed trials: [45].
[INFO 10-15 19:30:37] Scheduler: Retrieved COMPLETED trials: [45].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:30:37] Scheduler: Done submitting trials, waiting for remaining 2 running trials...
[INFO 10-15 19:30:37] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:30:37] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 2).
[INFO 10-15 19:30:38] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:30:38] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 2).
[INFO 10-15 19:30:39] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:30:39] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 2).
[INFO 10-15 19:30:42] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:30:42] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 2).
[INFO 10-15 19:30:45] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:30:45] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 2).
[INFO 10-15 19:30:50] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:30:50] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 2).
[INFO 10-15 19:30:58] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:30:58] Scheduler: Waiting for completed trials (for 11 sec, currently running trials: 2).
[INFO 10-15 19:31:09] Scheduler: Fetching data for newly completed trials: [46].
[INFO 10-15 19:31:09] Scheduler: Retrieved COMPLETED trials: [46].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 10-15 19:31:09] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:31:09] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 1).
[INFO 10-15 19:31:10] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:31:10] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 1).
[INFO 10-15 19:31:12] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:31:12] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 1).
[INFO 10-15 19:31:14] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:31:14] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 1).
[INFO 10-15 19:31:17] Scheduler: Fetching data for newly completed trials: [].
[INFO 10-15 19:31:17] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 1).
[INFO 10-15 19:31:22] Scheduler: Fetching data for newly completed trials: [47].
[INFO 10-15 19:31:22] Scheduler: Retrieved COMPLETED trials: [47].
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
OptimizationResult()
评估结果#
我们现在可以使用 Ax 包含的辅助函数和可视化来检查优化的结果。
首先,我们生成一个包含实验结果摘要的数据框。此数据框中的每一行对应一个 trial(即,一个已运行的训练作业),并包含有关 trial 状态、已评估的参数配置以及观察到的 metric 值的信息。这提供了一种轻松进行优化健全性检查的方法。
from ax.service.utils.report_utils import exp_to_df
df = exp_to_df(experiment)
df.head(10)
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[WARNING 10-15 19:31:22] ax.service.utils.report_utils: Column reason missing for all trials. Not appending column.
我们还可以可视化验证准确率和模型参数数量之间的权衡的 Pareto 前沿。
提示
Ax 使用 Plotly 生成交互式图表,允许您进行缩放、裁剪或悬停等操作,以查看图表组件的详细信息。尝试一下,如果您想了解更多信息,请查看 可视化教程)。
最终优化结果如图所示,其中颜色对应于每个 trial 的迭代次数。我们看到我们的方法能够成功地探索权衡,并找到了具有高验证准确率的大模型以及具有相对较低验证准确率的小模型。
from ax.service.utils.report_utils import _pareto_frontier_scatter_2d_plotly
_pareto_frontier_scatter_2d_plotly(experiment)
/usr/local/lib/python3.10/dist-packages/ax/core/map_data.py:195: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[WARNING 10-15 19:31:22] ax.service.utils.report_utils: Column reason missing for all trials. Not appending column.
为了更好地理解我们的代理模型对黑盒目标的学习情况,我们可以查看留一法交叉验证结果。由于我们的模型是高斯过程,它们不仅提供点预测,还提供关于这些预测的不确定性估计。一个好的模型意味着预测的均值(图中的点)接近 45 度线,并且置信区间以预期的频率覆盖 45 度线(这里我们使用 95% 的置信区间,因此我们期望它们有 95% 的时间包含真实观察值)。
如下图所示,模型大小(num_params)metric 比验证准确率(val_acc)metric 更容易建模。
from ax.modelbridge.cross_validation import compute_diagnostics, cross_validate
from ax.plot.diagnostic import interact_cross_validation_plotly
from ax.utils.notebook.plotting import init_notebook_plotting, render
cv = cross_validate(model=gs.model) # The surrogate model is stored on the ``GenerationStrategy``
compute_diagnostics(cv)
interact_cross_validation_plotly(cv)
我们还可以制作等高线图,以更好地了解不同的目标如何依赖于两个输入参数。在下面的图中,我们显示了模型预测的验证准确率作为两个隐藏层大小的函数。随着隐藏层大小的增加,验证准确率明显增加。
from ax.plot.contour import interact_contour_plotly
interact_contour_plotly(model=gs.model, metric_name="val_acc")
类似地,我们在下面的图中显示了模型参数数量作为隐藏层大小的函数,并看到它也随着隐藏层大小的增加而增加(对 hidden_size_1 的依赖性要大得多)。
interact_contour_plotly(model=gs.model, metric_name="num_params")
致谢#
我们感谢 TorchX 团队(特别是 Kiuk Chung 和 Tristan Rice)在将 TorchX 与 Ax 集成方面提供的帮助。
脚本总运行时间: (18 分钟 37.444 秒)
