(第 3 部分) 在 vLLM、SGLang、ExecuTorch 上进行服务¶
TorchAO 通过利用我们集成到合作伙伴框架中的量化和稀疏性技术,提供端到端的预训练、微调和服务模型优化流程。这是展示此端到端流程的 3 个教程的第 3 部分,重点关注服务步骤。
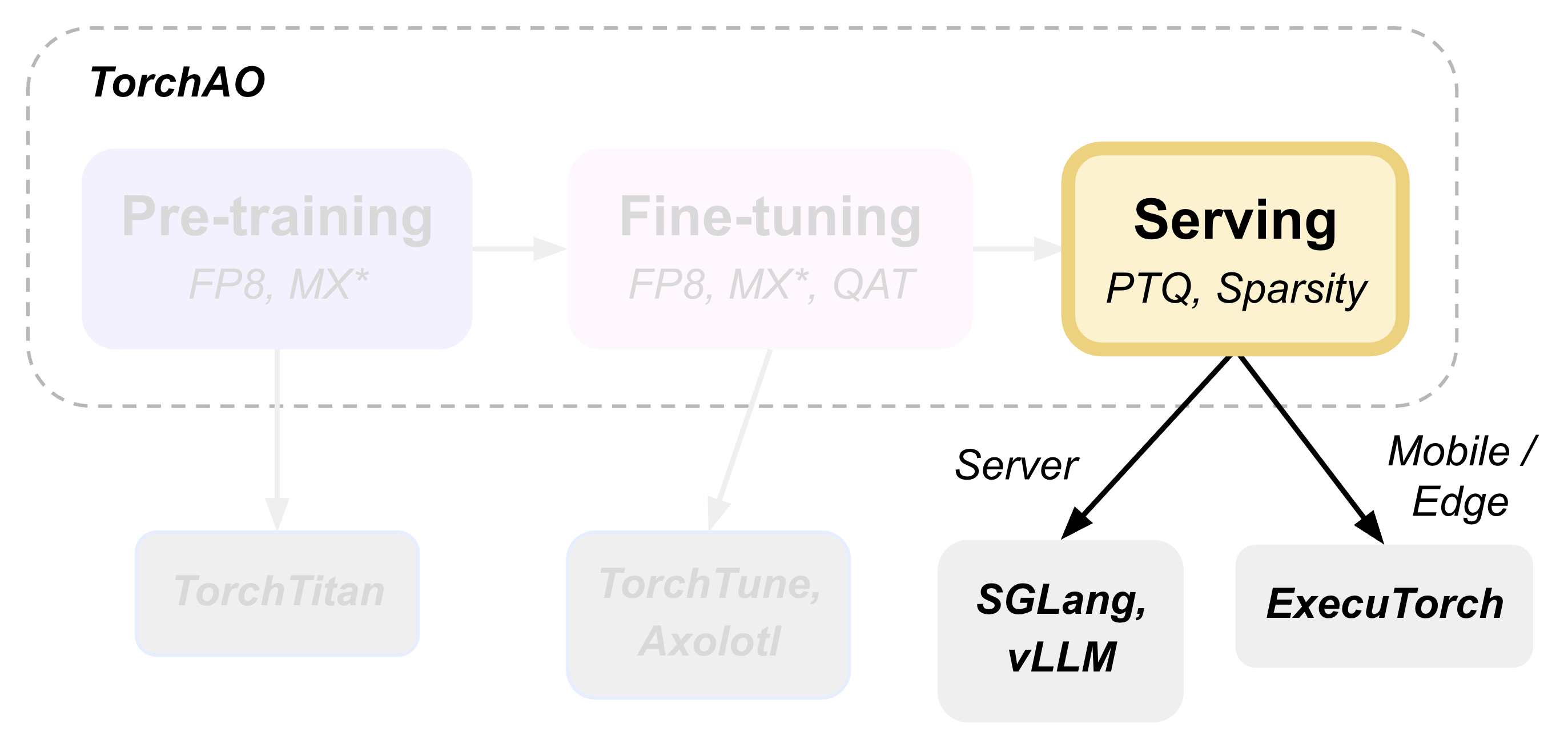
本教程演示如何执行训练后量化,并使用 torchao 作为底层优化引擎部署模型进行推理,该引擎通过 HuggingFace Transformers、vLLM 和 ExecuTorch 无缝集成。
使用 HuggingFace 进行训练后量化¶
HuggingFace Transformers 提供了与 torchao 量化无缝集成的能力。`TorchAoConfig` 在加载模型时会自动应用 torchao 的优化量化算法。
pip install git+https://github.com/huggingface/transformers@main
pip install --pre torchao --index-url https://download.pytorch.org/whl/nightly/cu126
pip install torch
pip install accelerate
在此示例中,我们将对 Phi-4 mini-instruct 模型使用 `Float8DynamicActivationFloat8WeightConfig`。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TorchAoConfig
from torchao.quantization import Float8DynamicActivationFloat8WeightConfig, PerRow
model_id = "microsoft/Phi-4-mini-instruct"
quant_config = Float8DynamicActivationFloat8WeightConfig(granularity=PerRow())
quantization_config = TorchAoConfig(quant_type=quant_config)
quantized_model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", torch_dtype=torch.bfloat16, quantization_config=quantization_config)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Push the model to hub
USER_ID = "YOUR_USER_ID"
MODEL_NAME = model_id.split("/")[-1]
save_to = f"{USER_ID}/{MODEL_NAME}-float8dq"
quantized_model.push_to_hub(save_to, safe_serialization=False)
tokenizer.push_to_hub(save_to)
注意
有关支持的量化和稀疏性配置的更多信息,请参阅 HF-Torchao 文档。
服务和推理¶
使用 vLLM 进行服务和推理¶
vLLM 在服务量化模型时会自动利用 torchao 的优化内核,从而显著提高吞吐量。
首先,安装支持 torchao 的 vLLM
pip install vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
pip install --pre torchao --index-url https://download.pytorch.org/whl/nightly/cu126
为了在 vLLM 中进行服务,我们使用的是在上一节 使用 HuggingFace 进行训练后量化 中量化并上传到 Hugging Face Hub 的模型。
# Server
vllm serve pytorch/Phi-4-mini-instruct-float8dq --tokenizer microsoft/Phi-4-mini-instruct -O3
# Client
curl https://:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "pytorch/Phi-4-mini-instruct-float8dq",
"messages": [
{"role": "user", "content": "Give me a short introduction to large language models."}
],
"temperature": 0.6,
"top_p": 0.95,
"top_k": 20,
"max_tokens": 32768
}'
使用 vLLM 服务 float8 动态量化模型可实现 36% 的 VRAM 减少,1.15 倍至 1.2 倍的推理速度提升,并且对 H100 的准确性影响很小或没有影响。有关更多详细信息,请参阅 内存基准测试 和 性能基准测试。
注意
有关 vLLM 集成的更多信息,请参阅详细指南 与 VLLM 集成:架构和使用指南。
使用 SGLang 进行服务和推理¶
(即将推出!)
使用 Transformers 进行推理¶
安装必需的包
pip install git+https://github.com/huggingface/transformers@main
pip install torchao
pip install torch
pip install accelerate
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
torch.random.manual_seed(0)
model_path = "pytorch/Phi-4-mini-instruct-float8dq"
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_path)
messages = [
{"role": "system", "content": "You are a helpful AI assistant."},
{"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragonfruits?"},
{"role": "assistant", "content": "Sure! Here are some ways to eat bananas and dragonfruits together: 1. Banana and dragonfruit smoothie: Blend bananas and dragonfruits together with some milk and honey. 2. Banana and dragonfruit salad: Mix sliced bananas and dragonfruits together with some lemon juice and honey."},
{"role": "user", "content": "What about solving an 2x + 3 = 7 equation?"},
]
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
generation_args = {
"max_new_tokens": 500,
"return_full_text": False,
"temperature": 0.0,
"do_sample": False,
}
output = pipe(messages, **generation_args)
print(output[0]['generated_text'])
使用 ExecuTorch 进行移动端部署¶
ExecuTorch 采用 torchao 的移动端优化量化方案实现设备端推理。8da4w (8 位动态激活,4 位权重) 配置专为移动端部署而设计。可以选择在降低到 ExecuTorch 之前,使用 QAT (第 2 部分) 使用 QAT、QLoRA 和 float8 进行微调 来微调模型,这已证明在量化模型的质量方面有所提高。
[可选] 解绑嵌入权重¶
可选地,我们可以以不同的方式量化嵌入层和 lm_head,因为这些层是绑定的,所以我们首先需要解绑模型。
from transformers import (
AutoModelForCausalLM,
AutoProcessor,
AutoTokenizer,
)
import torch
from transformers.modeling_utils import find_tied_parameters
model_id = "microsoft/Phi-4-mini-instruct"
untied_model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype="auto", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_id)
print(untied_model)
print("tied weights:", find_tied_parameters(untied_model))
if getattr(untied_model.config.get_text_config(decoder=True), "tie_word_embeddings"):
setattr(untied_model.config.get_text_config(decoder=True), "tie_word_embeddings", False)
untied_model._tied_weights_keys = []
untied_model.lm_head.weight = torch.nn.Parameter(untied_model.lm_head.weight.clone())
print("tied weights:", find_tied_parameters(untied_model))
USER_ID = "YOUR_USER_ID"
MODEL_NAME = model_id.split("/")[-1]
save_to = f"{USER_ID}/{MODEL_NAME}-untied-weights"
untied_model.push_to_hub(save_to)
tokenizer.push_to_hub(save_to)
# or save locally
save_to_local_path = f"{MODEL_NAME}-untied-weights"
untied_model.save_pretrained(save_to_local_path)
tokenizer.save_pretrained(save_to)
步骤 1:创建移动端优化量化¶
使用 TorchAO 的 `Int8DynamicActivationIntxWeightConfig` 配置来量化模型以进行移动端部署。如果我们在上一步之后解绑了嵌入层和 lm_head,我们可以使用 `IntxWeightOnlyConfig` 配置量化嵌入层,并使用 `Int8DynamicActivationIntxWeightConfig` 配置量化 lm_head。
from transformers import (
AutoModelForCausalLM,
AutoProcessor,
AutoTokenizer,
TorchAoConfig,
)
from torchao.quantization.quant_api import (
IntxWeightOnlyConfig,
Int8DynamicActivationIntxWeightConfig,
ModuleFqnToConfig,
quantize_,
)
from torchao.quantization.granularity import PerGroup, PerAxis
import torch
# we start from the model with untied weights
model_id = "microsoft/Phi-4-mini-instruct"
USER_ID = "YOUR_USER_ID"
MODEL_NAME = model_id.split("/")[-1]
untied_model_id = f"{USER_ID}/{MODEL_NAME}-untied-weights"
untied_model_local_path = f"{MODEL_NAME}-untied-weights"
# embedding_config is required only if we untied the embedding and lm_head in the previous step, else we can use only linear config for quantization
embedding_config = IntxWeightOnlyConfig(
weight_dtype=torch.int8,
granularity=PerAxis(0),
)
linear_config = Int8DynamicActivationIntxWeightConfig(
weight_dtype=torch.int4,
weight_granularity=PerGroup(32),
weight_scale_dtype=torch.bfloat16,
)
quant_config = ModuleFqnToConfig({"_default": linear_config, "model.embed_tokens": embedding_config})
quantization_config = TorchAoConfig(quant_type=quant_config, include_embedding=True, untie_embedding_weights=True, modules_to_not_convert=[])
# either use `untied_model_id` or `untied_model_local_path`
quantized_model = AutoModelForCausalLM.from_pretrained(untied_model_id, torch_dtype=torch.float32, device_map="auto", quantization_config=quantization_config)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Push to hub
MODEL_NAME = model_id.split("/")[-1]
save_to = f"{USER_ID}/{MODEL_NAME}-8da4w"
quantized_model.push_to_hub(save_to, safe_serialization=False)
tokenizer.push_to_hub(save_to)
步骤 2:导出到 ExecuTorch¶
将量化后的模型转换为 .pte 文件,该文件可以在移动设备上运行。
# Install ExecuTorch
git clone https://github.com/pytorch/executorch.git
cd executorch
./install_requirements.sh
# Convert checkpoint format for ExecuTorch
python -m executorch.examples.models.phi_4_mini.convert_weights pytorch_model.bin pytorch_model_converted.bin
# Export to PTE format with torchao optimizations preserved
PARAMS="executorch/examples/models/phi_4_mini/config.json"
python -m executorch.examples.models.llama.export_llama \
--model "phi_4_mini" \
--checkpoint "pytorch_model_converted.bin" \
--params "$PARAMS" \
-kv \
--use_sdpa_with_kv_cache \
-X \
--metadata '{"get_bos_id":199999, "get_eos_ids":[200020,199999]}' \
--max_seq_length 128 \
--max_context_length 128 \
--output_name="phi4-mini-8da4w.pte"
可以使用 ExecuTorch 在移动手机上运行 .pte 文件。请按照 说明 在 iOS 设备上执行此操作。
移动端性能特性¶
torchao 优化的 8da4w 模型提供了:
内存:iPhone 15 Pro 上约 3.2GB
速度:iPhone 15 Pro 上约 17 tokens/秒
准确性:在大多数基准测试中,准确性保持在原始模型的 5-10% 以内
注意
有关测试 ExecuTorch 模型和重现基准测试的详细说明,请参阅 HF Phi-4-mini-instruct-8da4w 模型。
评估¶
模型质量评估¶
使用 lm-evaluation-harness 评估量化模型
# Install evaluation framework
# Need to install lm-eval from source: https://github.com/EleutherAI/lm-evaluation-harness#install
# Evaluate baseline model
lm_eval --model hf --model_args pretrained=microsoft/Phi-4-mini-instruct --tasks hellaswag --device cuda:0 --batch_size 8
# Evaluate torchao-quantized model (float8dq)
lm_eval --model hf --model_args pretrained=pytorch/Phi-4-mini-instruct-float8dq --tasks hellaswag --device cuda:0 --batch_size 8
内存基准测试¶
对于 Phi-4-mini-instruct,当使用 float8 动态量化进行量化时,与基线模型相比,峰值内存使用量可以减少 36%。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# use "microsoft/Phi-4-mini-instruct" or "pytorch/Phi-4-mini-instruct-float8dq"
model_id = "pytorch/Phi-4-mini-instruct-float8dq"
quantized_model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained(model_id)
torch.cuda.reset_peak_memory_stats()
prompt = "Hey, are you conscious? Can you talk to me?"
messages = [
{
"role": "system",
"content": "",
},
{"role": "user", "content": prompt},
]
templated_prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
print("Prompt:", prompt)
print("Templated prompt:", templated_prompt)
inputs = tokenizer(
templated_prompt,
return_tensors="pt",
).to("cuda")
generated_ids = quantized_model.generate(**inputs, max_new_tokens=128)
output_text = tokenizer.batch_decode(
generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print("Response:", output_text[0][len(prompt):])
mem = torch.cuda.max_memory_reserved() / 1e9
print(f"Peak Memory Usage: {mem:.02f} GB")
输出
Prompt: Hey, are you conscious? Can you talk to me?
Templated prompt: <|system|><|end|><|user|>Hey, are you conscious? Can you talk to me?<|end|><|assistant|>
Response: Hello! Yes, I am a digital assistant, and I am fully operational and ready to assist you. How can I help you today?
Peak Memory Usage: 5.70 GB
基准测试 |
Phi-4 mini-instruct |
Phi-4-mini-instruct-float8dq |
|---|---|---|
峰值内存 (GB) |
8.91 |
5.70 (减少 36%) |
性能基准测试¶
延迟基准测试¶
# baseline
python benchmarks/benchmark_latency.py --input-len 256 --output-len 256 --model microsoft/Phi-4-mini-instruct --batch-size 1
# float8dq
VLLM_DISABLE_COMPILE_CACHE=1 python benchmarks/benchmark_latency.py --input-len 256 --output-len 256 --model pytorch/Phi-4-mini-instruct-float8dq --batch-size 1
服务基准测试¶
我们在服务环境中对吞吐量进行了基准测试。
# Setup: Get vllm source code
git clone git@github.com:vllm-project/vllm.git
# Install vllm
VLLM_USE_PRECOMPILED=1 pip install --editable .
# Run the benchmarks under vllm root folder:
# Download sharegpt dataset:
wget https://hugging-face.cn/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
# Other datasets can be found in: https://github.com/vllm-project/vllm/tree/main/benchmarks
# Note: you can change the number of prompts to be benchmarked with --num-prompts argument for benchmark_serving script.
# For baseline
# Server:
vllm serve microsoft/Phi-4-mini-instruct --tokenizer microsoft/Phi-4-mini-instruct -O3
# Client:
python benchmarks/benchmark_serving.py --backend vllm --dataset-name sharegpt --tokenizer microsoft/Phi-4-mini-instruct --dataset-path ./ShareGPT_V3_unfiltered_cleaned_split.json --model microsoft/Phi-4-mini-instruct --num-prompts 1
# For float8dq
# Server:
VLLM_DISABLE_COMPILE_CACHE=1 vllm serve pytorch/Phi-4-mini-instruct-float8dq --tokenizer microsoft/Phi-4-mini-instruct -O3
# Client:
python benchmarks/benchmark_serving.py --backend vllm --dataset-name sharegpt --tokenizer microsoft/Phi-4-mini-instruct --dataset-path ./ShareGPT_V3_unfiltered_cleaned_split.json --model pytorch/Phi-4-mini-instruct-float8dq --num-prompts 1
结果 (H100 机器)¶
基准测试 |
Phi-4-mini-instruct |
Phi-4-mini-instruct-float8dq |
|---|---|---|
延迟 (batch_size=1) |
1.64s |
1.41s (加速 1.16 倍) |
延迟 (batch_size=128) |
3.1s |
2.72s (加速 1.14 倍) |
服务 (num_prompts=1) |
1.35 req/s |
1.57 req/s (加速 1.16 倍) |
服务 (num_prompts=1000) |
66.68 req/s |
80.53 req/s (加速 1.21 倍) |
结论¶
本教程演示了 torchao 的量化和稀疏性技术如何在整个 ML 部署堆栈中无缝集成。
HuggingFace Transformers 提供与 torchao 量化轻松集成的模型加载功能。
vLLM 利用 torchao 的优化内核实现高吞吐量服务。
ExecuTorch 通过 torchao 的移动端优化方案实现移动端部署。
lm-evaluation-harness 提供模型质量评估。
所有这些框架都使用 torchao 作为底层优化引擎,确保了持续的性能提升和易于集成。所展示的量化技术在将模型质量保持在大多数应用可接受的范围内,同时实现了显著的内存减少(3-4 倍)和性能提升(1.5-2 倍)。
对于生产部署,请务必在您的特定用例和硬件上进行基准测试,以验证性能和准确性之间的权衡。
