torchrl.collectors 包¶
数据收集器在某种程度上等同于 PyTorch 的数据加载器,除了 (1) 它们从非静态数据源收集数据,以及 (2) 数据是使用模型(很可能是正在训练的模型的一个版本)收集的。
TorchRL 的数据收集器接受两个主要参数:一个环境(或一组环境构造函数)和一个策略。它们将在定义的步数内迭代地执行一个环境步骤和一个策略查询,然后将收集到的数据堆栈提供给用户。当环境达到完成状态和/或达到预定义的步数后,环境将被重置。
由于数据收集是一个潜在的计算密集型过程,因此适当配置执行超参数至关重要。需要考虑的第一个参数是数据收集应该与优化步骤串行发生还是并行发生。SyncDataCollector 类将在训练工作进程上执行数据收集。MultiSyncDataCollector 将工作负载分配给多个工作进程,并汇总将提供给训练工作进程的结果。最后,MultiaSyncDataCollector 将在多个工作进程上执行数据收集,并提供它能收集到的第一批结果。此执行将连续不断地发生,并与网络训练同时进行:这意味着用于数据收集的策略权重可能略滞后于训练工作进程上的策略配置。因此,尽管此类收集数据的速度可能最快,但其代价是仅适用于可以异步收集数据的设置(例如,离策略 RL 或课程 RL)。对于远程执行的 rollout(MultiSyncDataCollector 或 MultiaSyncDataCollector),有必要使用 collector.update_policy_weights_() 或在构造函数中设置 update_at_each_batch=True 来同步远程策略的权重与训练工作进程上的权重。
第二个要考虑的参数(在远程设置中)是数据收集的设备以及执行环境和策略操作的设备。例如,在 CPU 上执行的策略可能比在 CUDA 上执行的策略慢。当多个推理工作进程同时运行时,跨可用设备分派计算工作负载可能会加快收集速度或避免 OOM 错误。最后,批次大小和传递设备(即等待传递给收集工作进程的数据的存储设备)的选择也可能影响内存管理。控制的关键参数是 devices,它控制执行设备(即策略的设备),以及 storing_device,它控制在 rollout 期间存储环境和数据的设备。一个好的经验法则是通常使用相同的设备进行存储和计算,当仅传递 devices 参数时,这是默认行为。
除了这些计算参数外,用户还可以选择配置以下参数
max_frames_per_traj:在调用
env.reset()之后的帧数frames_per_batch:每次迭代收集器提供的帧数
init_random_frames:随机步数(调用
env.rand_step()的步数)reset_at_each_iter:如果为
True,则在每次批次收集后重置环境。split_trajs:如果为
True,则轨迹将被拆分,并以填充的 tensordict 和一个"mask"键的形式提供,该键将指向表示有效值的布尔掩码。exploration_type:与策略一起使用的探索策略。
reset_when_done:是否在达到完成状态时重置环境。
收集器和批次大小¶
由于每个收集器都有其组织内部运行的环境的方式,因此根据收集器的具体情况,数据将具有不同的批次大小。下表总结了收集数据时的情况。
SyncDataCollector |
MultiSyncDataCollector (n=B) |
MultiaSyncDataCollector (n=B) |
|||
|---|---|---|---|---|---|
cat_results |
NA |
“stack” |
0 |
-1 |
NA |
单环境 |
[T] |
[B, T] |
[B*(T//B) |
[B*(T//B)] |
[T] |
批处理环境 (n=P) |
[P, T] |
[B, P, T] |
[B * P, T] |
[P, T * B] |
[P, T] |
在所有这些情况下,最后一个维度(T 表示 time)会进行调整,以使批次大小等于传递给收集器的 frames_per_batch 参数。
警告
MultiSyncDataCollector 不应与 cat_results=0 一起使用,因为数据将与批处理环境一起沿着批次维度堆叠,或者对于单环境则沿着时间维度堆叠,这在两者之间进行切换时可能会引起混淆。cat_results="stack" 是一种更好、更一致的与环境交互的方式,因为它会使每个维度保持独立,并提供更好的配置、收集器类和其他组件之间的可互换性。
而 MultiSyncDataCollector 有一个对应于正在运行的子收集器数量的维度(B),而 MultiaSyncDataCollector 则没有。这一点很容易理解,因为 MultiaSyncDataCollector 是基于“先到先得”的原则提供数据批次的,而 MultiSyncDataCollector 则在提供数据之前会从每个子收集器收集数据。
收集器和策略副本¶
当将策略传递给收集器时,我们可以选择策略运行的设备。这可以用于将策略的训练版本放在一个设备上,而将推理版本放在另一个设备上。例如,如果您有两个 CUDA 设备,最好在一个设备上训练,并在另一个设备上执行策略进行推理。如果是这种情况,可以使用 update_policy_weights_() 将参数从一个设备复制到另一个设备(如果不需要复制,则此方法无效)。
由于目的是避免显式调用 policy.to(policy_device),因此收集器将在实例化时对策略结构进行深度复制,并将参数放在新设备上(如果需要)。由于并非所有策略都支持深度复制(例如,使用 CUDA 图或依赖第三方库的策略),因此我们尽量限制执行深度复制的情况。以下图表显示了何时会发生这种情况。
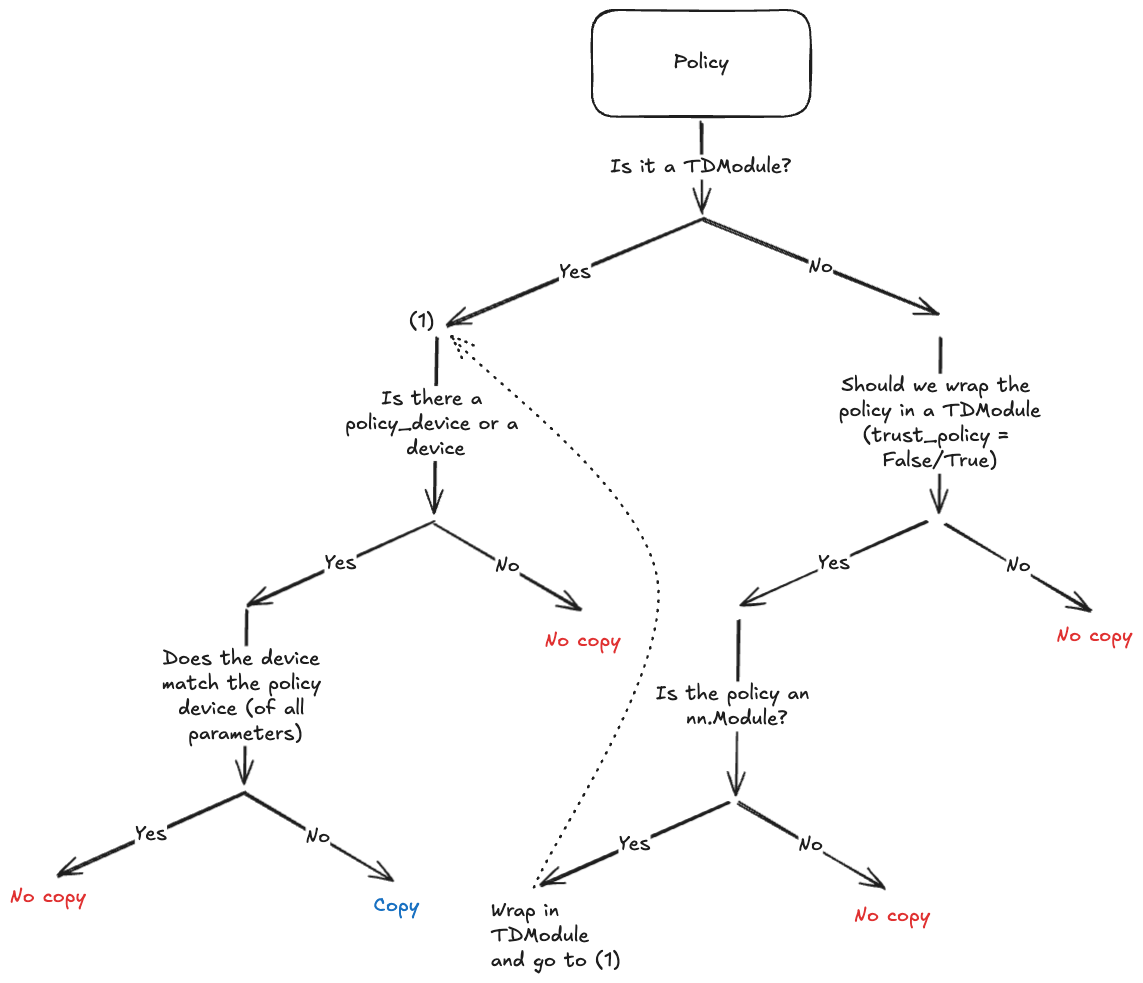
收集器中的策略复制决策树。¶
分布式环境中的权重同步¶
在分布式和多进程环境中,确保所有策略实例都与最新的训练权重同步对于保持性能一致至关重要。API 引入了一种灵活且可扩展的机制,用于在不同设备和进程之间更新策略权重,以适应各种部署场景。
使用 WeightUpdaters 发送和接收模型权重¶
权重同步过程通过一个专用的扩展点进行协调:WeightUpdaterBase。这个基类提供了一个结构化的接口来实现自定义权重更新逻辑,允许用户根据自己的具体需求定制同步过程。
WeightUpdaterBase 负责将策略权重分发给策略或远程推理工作进程,以及在必要时从服务器格式化/收集权重。每个收集器(服务器或工作进程)都应有一个 WeightUpdaterBase 实例来处理与策略的权重同步。即使是最简单的收集器也使用 VanillaWeightUpdater 实例来更新策略的 state_dict(假设它是一个 Module 实例)。
扩展 Updater 类¶
为了适应不同的用例,API 允许用户扩展 updater 类并进行自定义实现。目标是能够自定义权重同步策略,同时不修改收集器和策略的实现。这种灵活性在涉及复杂网络架构或专用硬件设置的场景中尤其有益。通过实现这些基类中的抽象方法,用户可以定义如何检索、转换和应用权重,确保与他们现有的基础设施无缝集成。
用于在推理工作进程上更新远程策略权重的基类。 |
|
|
用于更新本地策略权重的 |
|
用于跨多个进程或设备同步策略权重的远程权重更新器。 |
|
使用 Ray 在远程工作进程之间同步策略权重的远程权重更新器。 |
|
使用 RPC 在远程工作进程之间同步策略权重的远程权重更新器。 |
|
用于在分布式工作进程之间同步策略权重的远程权重更新器。 |
收集器与回放缓冲区互操作性¶
在需要从回放缓冲区采样单个转换的最简单场景中,几乎不需要关注收集器的构建方式。在填充存储之前,将数据展平作为预处理步骤就足够了。
>>> memory = ReplayBuffer(
... storage=LazyTensorStorage(N),
... transform=lambda data: data.reshape(-1))
>>> for data in collector:
... memory.extend(data)
如果需要收集轨迹切片,推荐的方法是创建一个多维缓冲区,并使用 SliceSampler 采样器类进行采样。必须确保传递给缓冲区的数据形状正确,并且 time 和 batch 维度清晰分开。实际上,以下配置将起作用。
>>> # Single environment: no need for a multi-dimensional buffer
>>> memory = ReplayBuffer(
... storage=LazyTensorStorage(N),
... sampler=SliceSampler(num_slices=4, trajectory_key=("collector", "traj_ids"))
... )
>>> collector = SyncDataCollector(env, policy, frames_per_batch=N, total_frames=-1)
>>> for data in collector:
... memory.extend(data)
>>> # Batched environments: a multi-dim buffer is required
>>> memory = ReplayBuffer(
... storage=LazyTensorStorage(N, ndim=2),
... sampler=SliceSampler(num_slices=4, trajectory_key=("collector", "traj_ids"))
... )
>>> env = ParallelEnv(4, make_env)
>>> collector = SyncDataCollector(env, policy, frames_per_batch=N, total_frames=-1)
>>> for data in collector:
... memory.extend(data)
>>> # MultiSyncDataCollector + regular env: behaves like a ParallelEnv if cat_results="stack"
>>> memory = ReplayBuffer(
... storage=LazyTensorStorage(N, ndim=2),
... sampler=SliceSampler(num_slices=4, trajectory_key=("collector", "traj_ids"))
... )
>>> collector = MultiSyncDataCollector([make_env] * 4,
... policy,
... frames_per_batch=N,
... total_frames=-1,
... cat_results="stack")
>>> for data in collector:
... memory.extend(data)
>>> # MultiSyncDataCollector + parallel env: the ndim must be adapted accordingly
>>> memory = ReplayBuffer(
... storage=LazyTensorStorage(N, ndim=3),
... sampler=SliceSampler(num_slices=4, trajectory_key=("collector", "traj_ids"))
... )
>>> collector = MultiSyncDataCollector([ParallelEnv(2, make_env)] * 4,
... policy,
... frames_per_batch=N,
... total_frames=-1,
... cat_results="stack")
>>> for data in collector:
... memory.extend(data)
使用 MultiSyncDataCollector 采样轨迹的回放缓冲区目前不受完全支持,因为数据批次可能来自任何工作进程,并且在大多数情况下,写入缓冲区中的连续批次不会来自同一来源(从而中断了轨迹)。
异步运行收集器¶
将回放缓冲区传递给收集器可以让我们开始收集,并摆脱收集器的迭代特性。如果你想在后台运行数据收集器,只需运行 start()。
>>> collector = SyncDataCollector(..., replay_buffer=rb) # pass your replay buffer
>>> collector.start()
>>> # little pause
>>> time.sleep(10)
>>> # Start training
>>> for i in range(optim_steps):
... data = rb.sample() # Sampling from the replay buffer
... # rest of the training loop
单进程收集器(SyncDataCollector)将使用多线程运行进程,因此请注意 Python 的 GIL 和相关的多线程限制。
另一方面,多进程收集器将允许子进程自己处理缓冲区的填充,从而真正解耦数据收集和训练。
使用 start() 启动的数据收集器应使用 async_shutdown() 关闭。
警告
异步运行收集器可以将收集与训练解耦,这意味着训练性能可能因硬件、负载和其他因素而有很大差异(尽管通常预期会提供显著的速度提升)。请确保您了解这可能如何影响您的算法,以及这是否是合理的做法!(例如,PPO 等 on-policy 算法不应异步运行,除非经过适当的基准测试)。
单节点数据收集器¶
数据收集器的基类。 |
|
|
RL 问题的通用数据收集器。 |
|
在单独的进程中同步运行给定数量的 DataCollectors。 |
|
在单独的进程中异步运行给定数量的 DataCollectors。 |
|
在单独的进程中运行单个 DataCollector。 |
分布式数据收集器¶
TorchRL 提供了一系列分布式数据收集器。这些工具支持多种后端('gloo'、'nccl'、'mpi'(使用 DistributedDataCollector)或 PyTorch RPC(使用 RPCDataCollector))和启动器('ray'、submitit 或 torch.multiprocessing)。它们可以在同步或异步模式下,在单节点或跨多个节点上高效使用。
资源:在专用文件夹中查找这些收集器的示例。
注意
选择子收集器:所有分布式收集器都支持各种单机收集器。人们可能会想为什么还要使用 MultiSyncDataCollector 或 ParallelEnv。总的来说,多进程收集器的 IO 开销比并行环境低,因为并行环境需要在每一步进行通信。然而,模型规格在反方向上起作用,因为使用并行环境将导致策略(和/或转换)执行速度更快,因为这些操作将被向量化。
注意
选择收集器(或并行环境)的设备:进程间数据共享是通过共享内存缓冲区实现的,并行环境和在 CPU 上执行的多进程环境。根据所用机器的功能,这可能比在 GPU 上共享数据(由 CUDA 驱动程序原生支持)慢得令人无法接受。实际上,这意味着在构建并行环境或收集器时使用 device="cpu" 关键字参数可能会比在可用时使用 device="cuda" 导致收集速度变慢。
注意
考虑到该库的许多可选依赖项(例如,Gym、Gymnasium 以及许多其他库),在多进程/分布式环境中,警告可能会很快变得非常烦人。默认情况下,TorchRL 会在子进程中过滤掉这些警告。如果仍然希望看到这些警告,可以通过设置 torchrl.filter_warnings_subprocess=False 来显示它们。
|
带有 torch.distributed 后端的分布式数据收集器。 |
|
基于 RPC 的分布式数据收集器。 |
|
带有 torch.distributed 后端的分布式同步数据收集器。 |
|
Submitit 的延迟启动器。 |
|
带有 Ray 后端的分布式数据收集器。 |
辅助函数¶
|
用于轨迹分离的实用函数。 |
