注意
转到底部 下载完整示例代码
Torch Export with Cudagraphs¶
CUDA Graphs 允许通过单个 CPU 操作启动多个 GPU 操作,从而减少启动开销并提高 GPU 利用率。Torch-TensorRT 提供了一个简单的接口来启用 CUDA Graphs。此功能允许用户轻松利用 CUDA Graphs 的性能优势,而无需手动管理捕获和回放的复杂性。
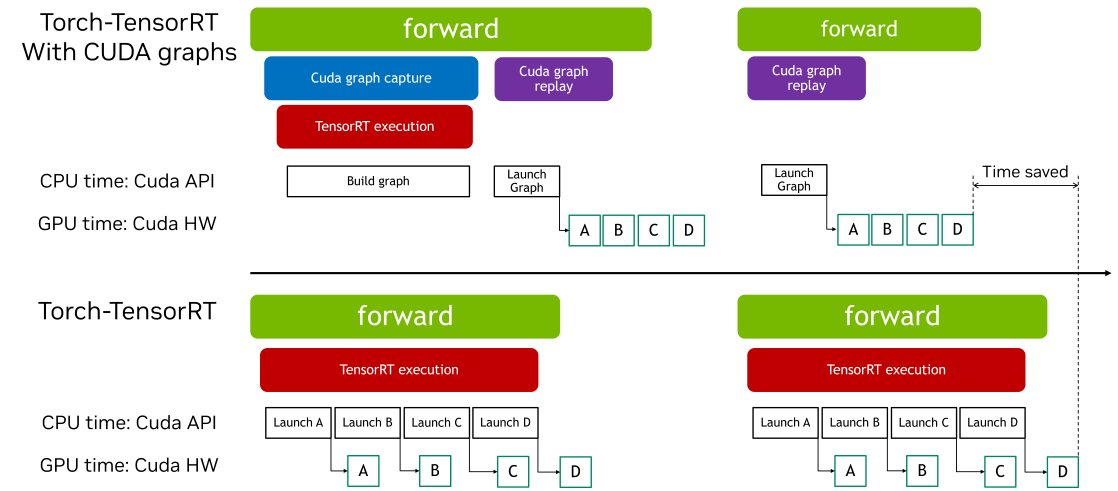
此交互式脚本旨在概述 Torch-TensorRT Cudagraphs 集成在 ir=”dynamo” 路径中的使用过程。该功能在 torch.compile 路径中也类似地工作。
导入和模型定义¶
import torch
import torch_tensorrt
import torchvision.models as models
使用 torch_tensorrt.compile 进行编译(使用默认设置)¶
# We begin by defining and initializing a model
model = models.resnet18(pretrained=True).cuda().eval()
# Define sample inputs
inputs = torch.randn((16, 3, 224, 224)).cuda()
# Next, we compile the model using torch_tensorrt.compile
# We use the `ir="dynamo"` flag here, and `ir="torch_compile"` should
# work with cudagraphs as well.
opt = torch_tensorrt.compile(
model,
ir="dynamo",
inputs=torch_tensorrt.Input(
min_shape=(1, 3, 224, 224),
opt_shape=(8, 3, 224, 224),
max_shape=(16, 3, 224, 224),
dtype=torch.float,
name="x",
),
)
使用 Cudagraphs 集成进行推理¶
# We can enable the cudagraphs API with a context manager
with torch.no_grad():
with torch_tensorrt.runtime.enable_cudagraphs(opt) as cudagraphs_module:
out_trt = cudagraphs_module(inputs)
# Alternatively, we can set the cudagraphs mode for the session
torch_tensorrt.runtime.set_cudagraphs_mode(True)
out_trt = opt(inputs)
# We can also turn off cudagraphs mode and perform inference as normal
torch_tensorrt.runtime.set_cudagraphs_mode(False)
out_trt = opt(inputs)
# If we provide new input shapes, cudagraphs will re-record the graph
inputs_2 = torch.randn((8, 3, 224, 224)).cuda()
inputs_3 = torch.randn((4, 3, 224, 224)).cuda()
with torch.no_grad():
with torch_tensorrt.runtime.enable_cudagraphs(opt) as cudagraphs_module:
out_trt_2 = cudagraphs_module(inputs_2)
out_trt_3 = cudagraphs_module(inputs_3)
包含图中断的模块的 CUDA Graphs¶
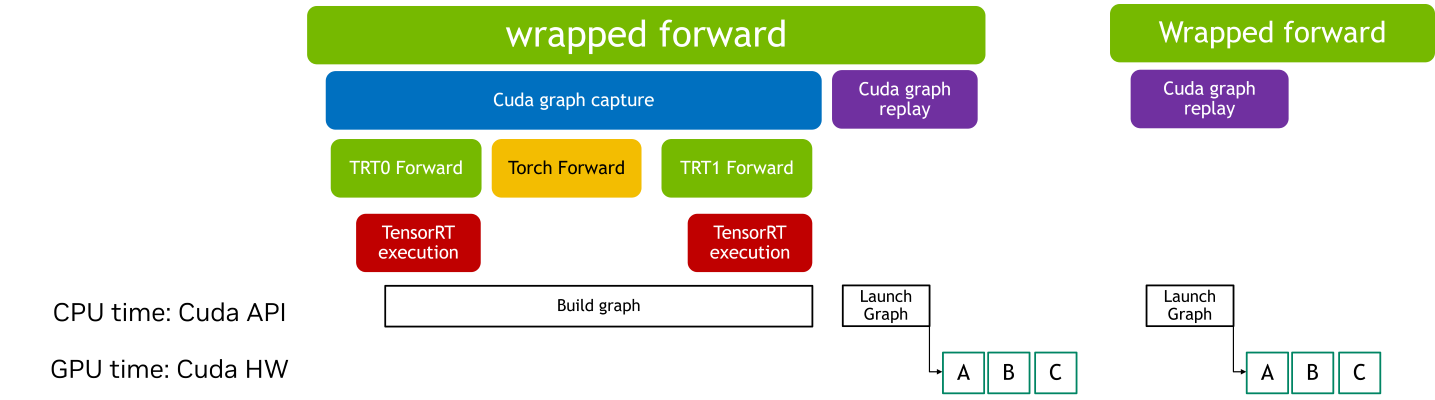
当 CUDA Graphs 应用于包含图中断的 TensorRT 模型时,每个中断都会引入额外的开销。这是因为图中断阻止了整个模型作为一个单一、连续的优化单元执行。因此,CUDA Graphs 通常提供的部分性能优势,例如减少的内核启动开销和提高的执行效率,可能会有所降低。
使用带 CUDA Graphs 的包装运行时模块,您可以将操作序列封装到图中,即使存在图中断,这些图也可以高效执行。如果 TensorRT 模块存在图中断,CUDA Graph 上下文管理器将返回一个 wrapped_module。此模块捕获整个执行图,通过减少内核启动开销和提高性能,从而在后续推理中实现高效回放。
请注意,使用包装器模块进行初始化涉及一个预热阶段,在此阶段会多次执行该模块。此预热可确保内存分配和初始化不会被记录在 CUDA Graphs 中,这有助于保持一致的执行路径并优化性能。
class SampleModel(torch.nn.Module):
def forward(self, x):
return torch.relu((x + 2) * 0.5)
model = SampleModel().cuda().eval()
input = torch.randn((1, 3, 224, 224)).cuda()
# The 'torch_executed_ops' compiler option is used in this example to intentionally introduce graph breaks within the module.
# Note: The Dynamo backend is required for the CUDA Graph context manager to handle modules in an Ahead-Of-Time (AOT) manner.
opt_with_graph_break = torch_tensorrt.compile(
model,
ir="dynamo",
inputs=[input],
min_block_size=1,
pass_through_build_failures=True,
torch_executed_ops={"torch.ops.aten.mul.Tensor"},
)
如果模块存在图中断,则整个子模块将被 cuda graphs 记录和回放
with torch.no_grad():
with torch_tensorrt.runtime.enable_cudagraphs(
opt_with_graph_break
) as cudagraphs_module:
cudagraphs_module(input)
脚本总运行时间: ( 0 分 0.000 秒)
