


整体追踪分析简介#
创建于: 2024 年 01 月 02 日 | 最后更新: 2024 年 01 月 05 日 | 最后验证: 2024 年 11 月 05 日
作者: Anupam Bhatnagar
在本教程中,我们将演示如何使用整体追踪分析 (HTA) 来分析分布式训练作业的追踪数据。请按照以下步骤开始。
安装 HTA#
我们建议使用 Conda 环境来安装 HTA。要安装 Anaconda,请参阅 官方 Anaconda 文档。
使用 pip 安装 HTA
pip install HolisticTraceAnalysis
(可选且推荐) 设置 Conda 环境
# create the environment env_name conda create -n env_name # activate the environment conda activate env_name # When you are done, deactivate the environment by running ``conda deactivate``
入门#
启动 Jupyter notebook 并将 trace_dir 变量设置为追踪数据的位置。
from hta.trace_analysis import TraceAnalysis
trace_dir = "/path/to/folder/with/traces"
analyzer = TraceAnalysis(trace_dir=trace_dir)
时间分解#
为了有效利用 GPU,了解它们如何为特定作业花费时间至关重要。它们主要从事计算、通信、内存事件,还是处于空闲状态?时间分解功能提供了对这三个类别花费时间的详细分析。
空闲时间 - GPU 处于空闲状态。
计算时间 - GPU 用于矩阵乘法或向量运算。
非计算时间 - GPU 用于通信或内存事件。
为了实现高训练效率,代码应最大化计算时间并最小化空闲时间和非计算时间。以下函数生成一个数据帧,提供每个 rank 的时间使用情况的详细分解。
analyzer = TraceAnalysis(trace_dir = "/path/to/trace/folder")
time_spent_df = analyzer.get_temporal_breakdown()
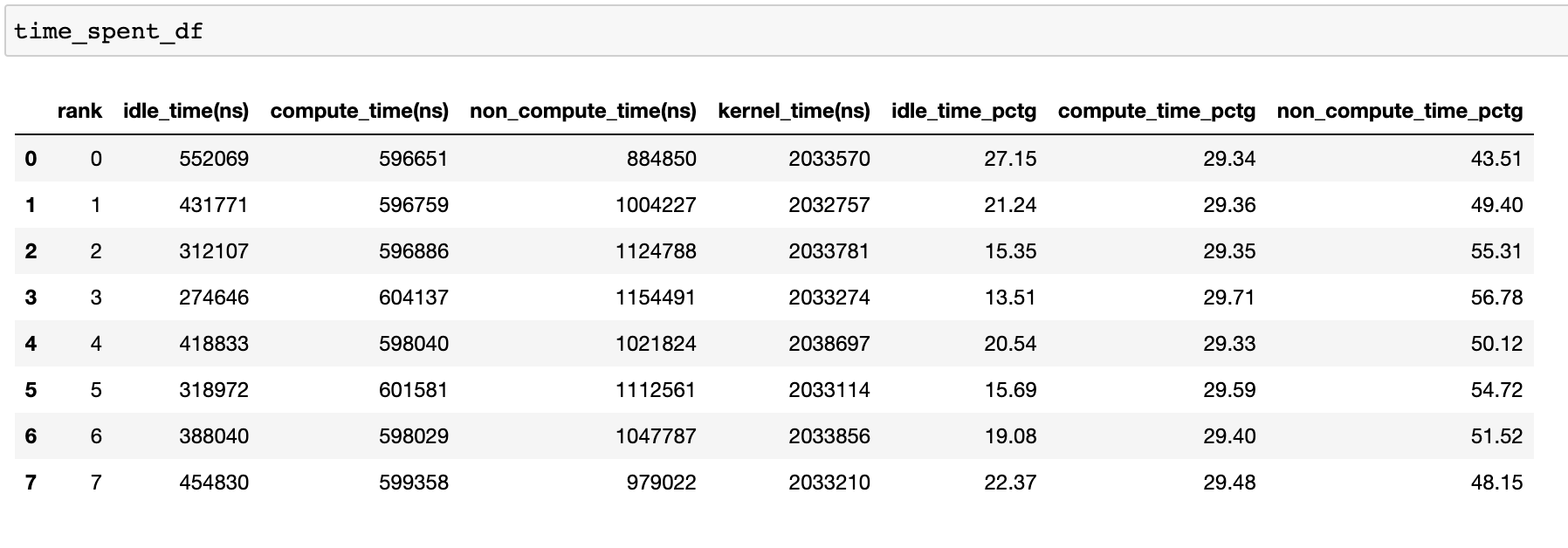
当 get_temporal_breakdown 函数中的 visualize 参数设置为 True 时,它还会生成一个表示按 rank 分解的条形图。
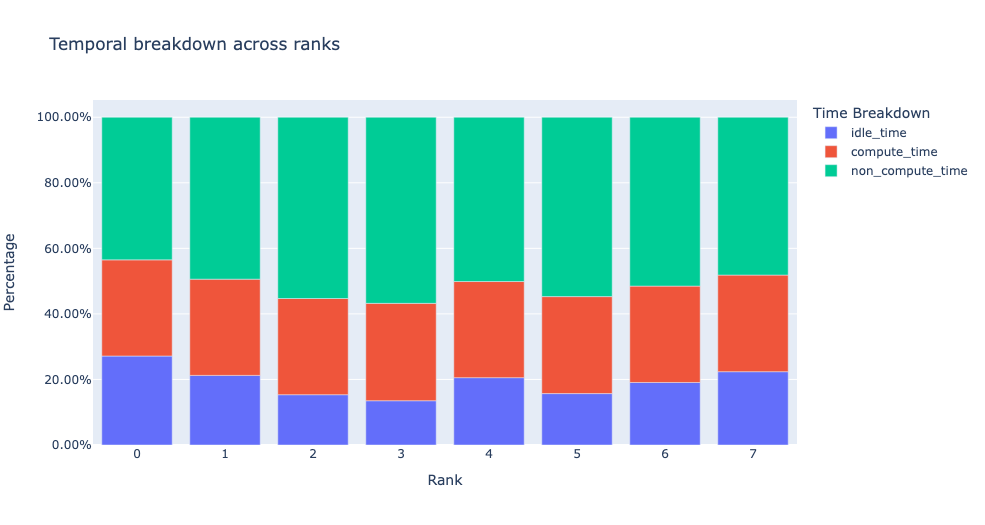
空闲时间分解#
深入了解 GPU 空闲时间及其原因,有助于指导优化策略。当 GPU 上没有内核运行时,它被视为空闲。我们开发了一种算法,将 空闲 时间分为三个不同的类别:
主机等待: 指 GPU 上因 CPU 排列内核不够快以致 GPU 未充分利用而造成的空闲时间。这类低效率可以通过检查导致延迟的 CPU 操作、增加批量大小和应用操作融合来解决。
内核等待: 指在 GPU 上启动连续内核的短暂开销。可以通过使用 CUDA 图优化来最小化归因于此类的空闲时间。
其他等待: 此类别包括目前由于信息不足而无法归因的空闲时间。可能的原因包括使用 CUDA 事件进行 CUDA 流之间的同步以及启动内核的延迟。
主机等待时间可解释为 GPU 因 CPU 而停滞的时间。为了将空闲时间归因于内核等待,我们使用以下启发式方法:
连续内核之间的间隔 < 阈值
默认阈值是 30 纳秒,可以通过 consecutive_kernel_delay 参数进行配置。默认情况下,空闲时间分解仅为 rank 0 计算。为了计算其他 rank 的分解,请使用 get_idle_time_breakdown 函数中的 ranks 参数。空闲时间分解可以按以下方式生成:
analyzer = TraceAnalysis(trace_dir = "/path/to/trace/folder")
idle_time_df = analyzer.get_idle_time_breakdown()
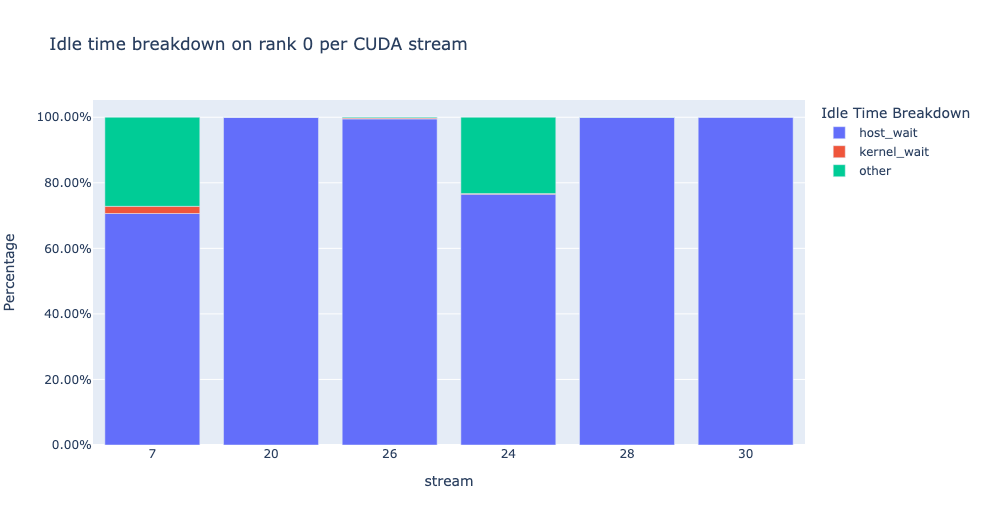
该函数返回一个数据帧元组。第一个数据帧包含每个 rank 的每个流的按类别的空闲时间。
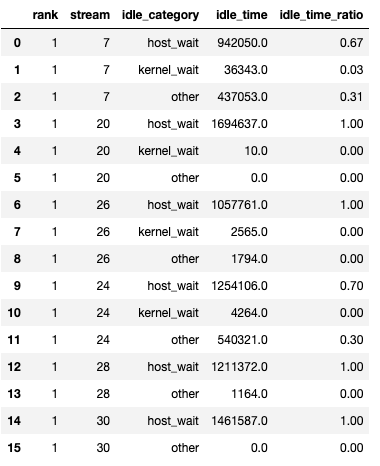
当 show_idle_interval_stats 设置为 True 时,生成第二个数据帧。它包含每个 rank 的每个流的空闲时间的摘要统计信息。
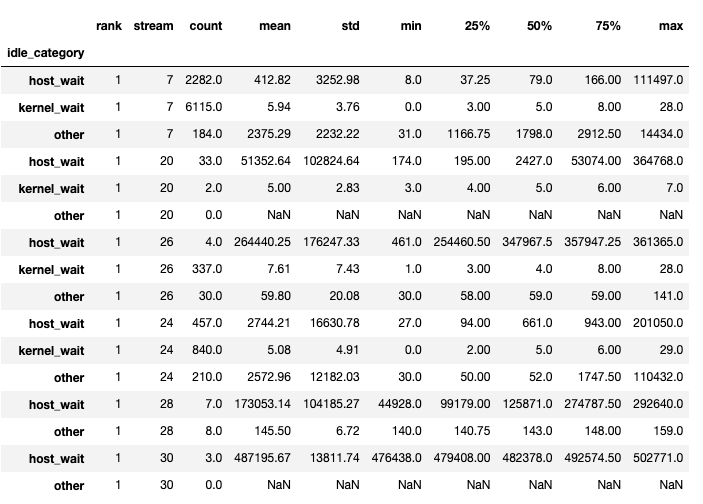
提示
默认情况下,空闲时间分解会显示每个空闲时间类别的百分比。将 visualize_pctg 参数设置为 False,该函数将以 y 轴上的绝对时间进行渲染。
内核分解#
内核分解功能将所有 rank 在每种内核类型(例如通信 (COMM)、计算 (COMP) 和内存 (MEM))上花费的时间进行分解,并显示每个类别花费时间的比例。以下是作为饼图显示的每个类别所花费时间的百分比:
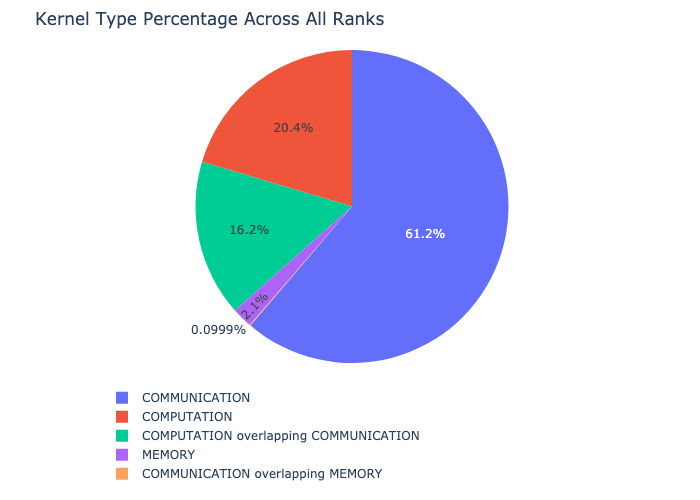
内核分解可以按以下方式计算:
analyzer = TraceAnalysis(trace_dir = "/path/to/trace/folder")
kernel_type_metrics_df, kernel_metrics_df = analyzer.get_gpu_kernel_breakdown()
函数返回的第一个数据帧包含用于生成饼图的原始值。
内核持续时间分布#
由 get_gpu_kernel_breakdown 返回的第二个数据帧包含每个内核的持续时间摘要统计信息。特别是,它包括每个 rank 的每个内核的计数、最小值、最大值、平均值、标准差、总和和内核类型。
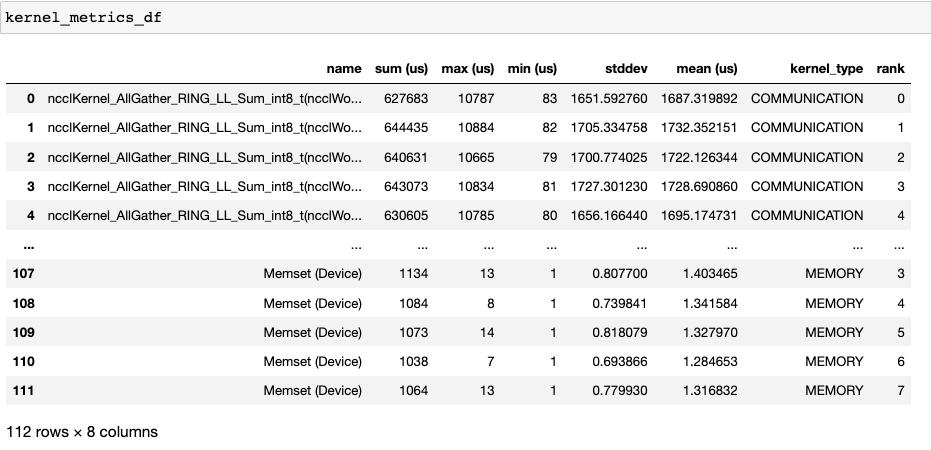
利用这些数据,HTA 创建了许多可视化来识别性能瓶颈。
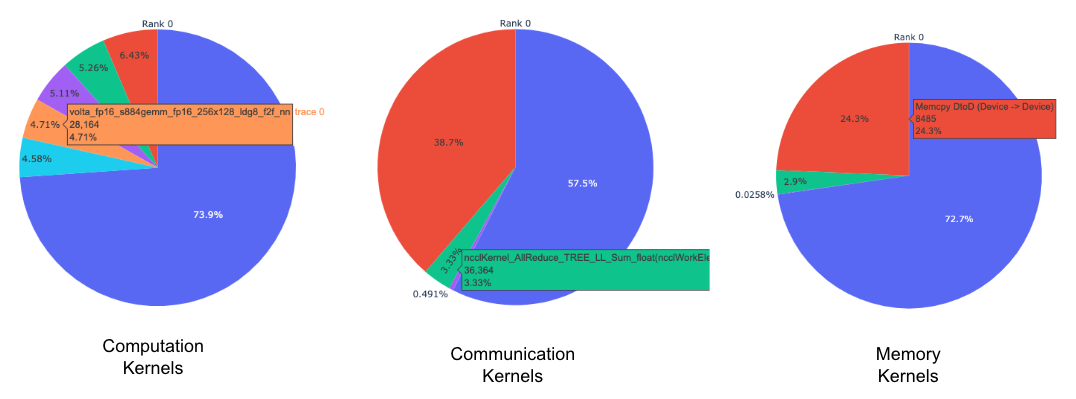
每个 rank 的每种内核类型的顶级内核的饼图。
所有 rank 中每个顶级内核和每种内核类型的平均持续时间的条形图。
提示
所有图像均使用 plotly 生成。将鼠标悬停在图表上会在右上角显示模式栏,允许用户缩放、平移、选择和下载图表。
上方的饼图显示了计算、通信和内存内核的前 5 名。类似地为每个 rank 生成饼图。可以使用传递给 get_gpu_kernel_breakdown 函数的 num_kernels 参数来配置饼图以显示前 k 个内核。此外,还可以使用 duration_ratio 参数来调整需要分析的时间百分比。如果同时指定了 num_kernels 和 duration_ratio,则 num_kernels 具有优先权。
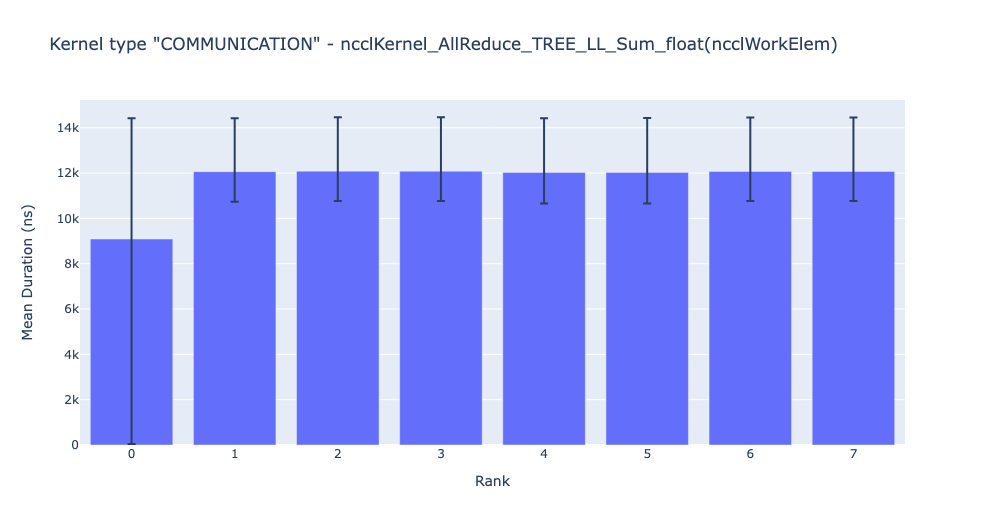
上方的条形图显示了所有 rank 中 NCCL AllReduce 内核的平均持续时间。黑线表示每个 rank 上的最短和最长时间。
警告
当使用 jupyter-lab 时,将 “image_renderer” 参数值设置为 “jupyterlab”,否则图表将无法在 notebook 中渲染。
有关此功能的详细演练,请参阅仓库示例文件夹中的 gpu_kernel_breakdown notebook。
通信计算重叠#
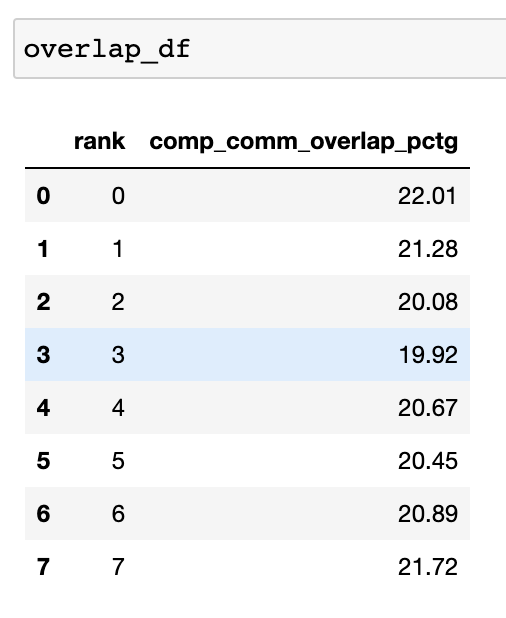
在分布式训练中,大量时间花在 GPU 之间的通信和同步事件上。为了实现高 GPU 效率(例如 TFLOPS/GPU),保持 GPU 被计算内核过度订阅至关重要。换句话说,GPU 不应因未解决的数据依赖性而阻塞。衡量计算被数据依赖性阻塞程度的一种方法是计算通信计算重叠。如果通信事件与计算事件重叠,则观察到更高的 GPU 效率。缺乏通信和计算重叠将导致 GPU 空闲,从而导致效率低下。总之,更高的通信计算重叠是可取的。为了计算每个 rank 的重叠百分比,我们测量以下比率:
(通信期间花费的计算时间) / (通信期间花费的时间)
通信计算重叠可以按以下方式计算:
analyzer = TraceAnalysis(trace_dir = "/path/to/trace/folder")
overlap_df = analyzer.get_comm_comp_overlap()
该函数返回一个包含每个 rank 的重叠百分比的数据帧。
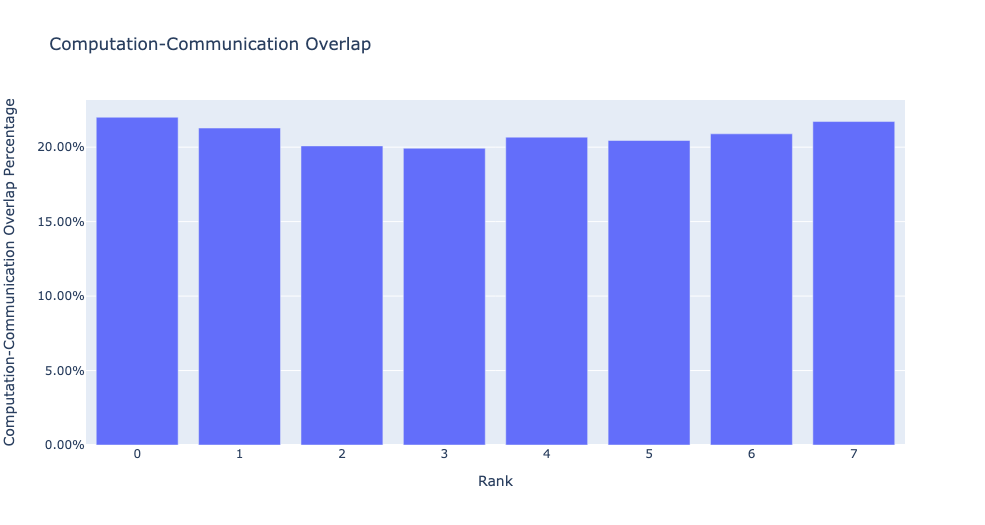
当 visualize 参数设置为 True 时,get_comm_comp_overlap 函数还会生成一个表示按 rank 重叠的条形图。
增强计数器#
内存带宽和队列长度计数器#
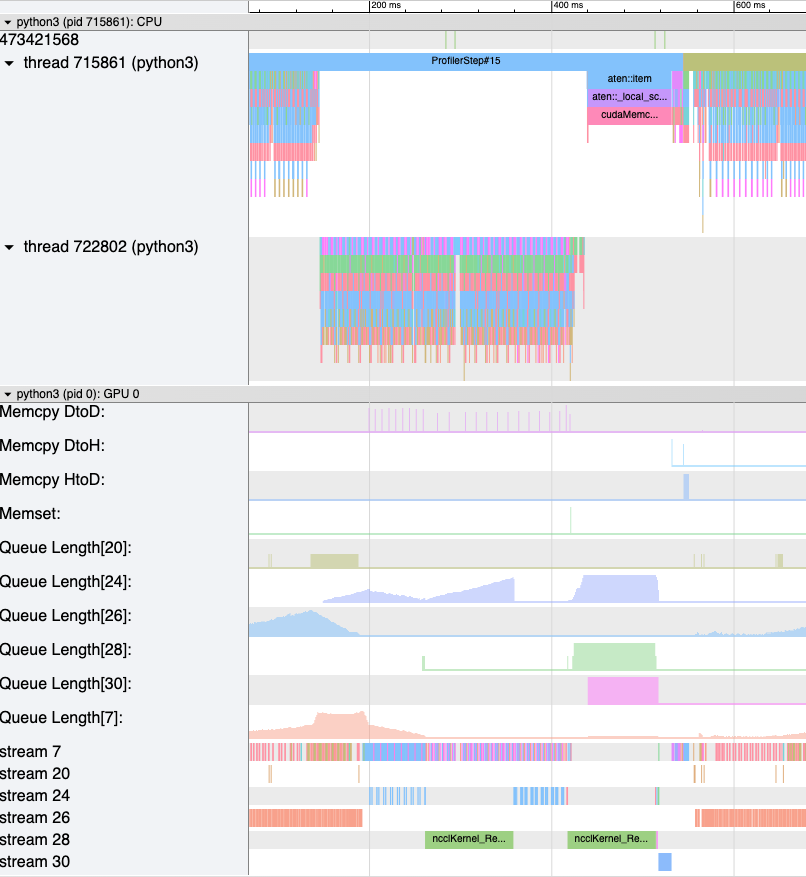
内存带宽计数器测量在通过内存复制 (memcpy) 和内存设置 (memset) 事件从 H2D、D2H 和 D2D 复制数据时使用的内存复制带宽。HTA 还计算每个 CUDA 流上的未完成操作数。我们称之为队列长度。当流上的队列长度为 1024 或更大时,无法在该流上调度新事件,CPU 将一直等待,直到 GPU 流上的事件已处理完毕。
generate_trace_with_counters API 输出一个新的追踪文件,其中包含内存带宽和队列长度计数器。新追踪文件包含指示 memcpy/memset 操作使用的内存带宽的轨迹,以及每个流上队列长度的轨迹。默认情况下,这些计数器使用 rank 0 的追踪文件生成,新文件名称中包含后缀 _with_counters。用户可以通过在 generate_trace_with_counters API 中使用 ranks 参数来为多个 rank 生成计数器。
analyzer = TraceAnalysis(trace_dir = "/path/to/trace/folder")
analyzer.generate_trace_with_counters()
带有增强计数器的生成追踪文件的截图。
HTA 还提供内存复制带宽和队列长度计数器的摘要,以及使用以下 API 对代码的分析部分的时间序列:
要查看摘要和时间序列,请使用:
# generate summary
mem_bw_summary = analyzer.get_memory_bw_summary()
queue_len_summary = analyzer.get_queue_length_summary()
# get time series
mem_bw_series = analyzer.get_memory_bw_time_series()
queue_len_series = analyzer.get_queue_length_series()
摘要包含计数、最小值、最大值、均值、标准差、25%、50% 和 75% 百分位数。
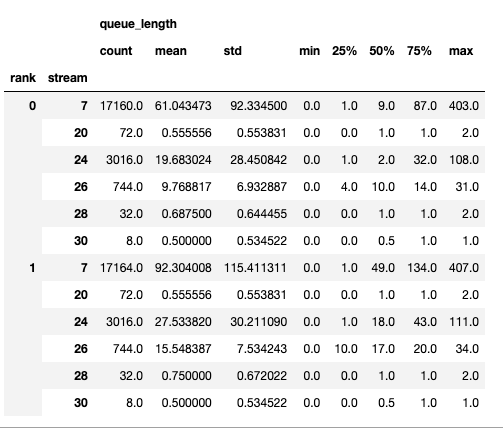
时间序列仅包含值更改时的点。一旦观察到某个值,时间序列将保持不变,直到下次更新。内存带宽和队列长度时间序列函数返回一个字典,其键是 rank,值是该 rank 的时间序列。默认情况下,时间序列仅为 rank 0 计算。
CUDA 内核启动统计信息#
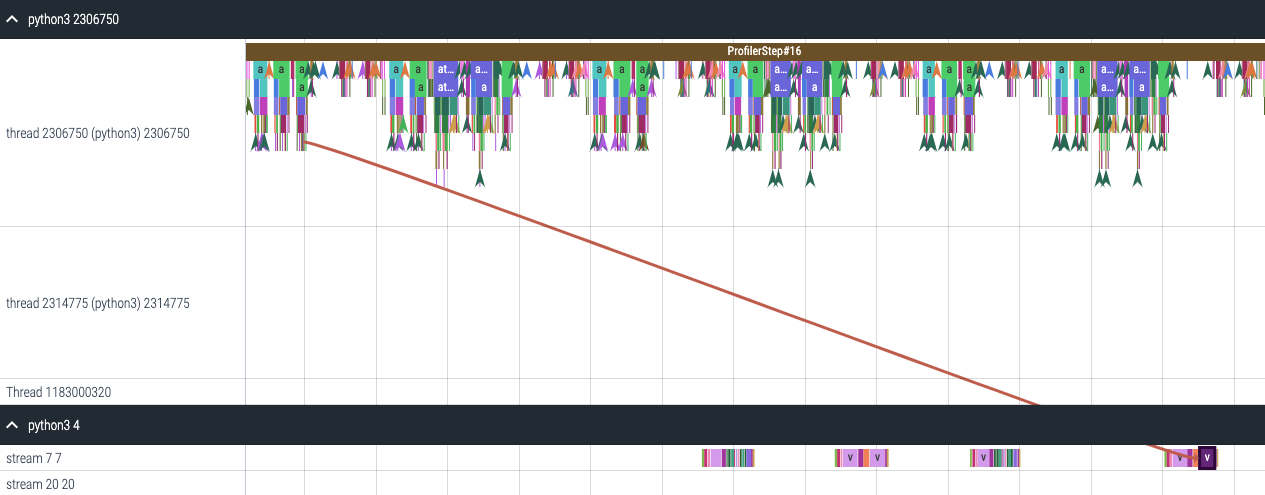
对于在 GPU 上启动的每个事件,都有一个相应的 CPU 调度事件,例如 CudaLaunchKernel、CudaMemcpyAsync、CudaMemsetAsync。这些事件通过追踪中的公共关联 ID 进行链接 - 请参见上图。此功能计算 CPU 运行时事件的持续时间、相应的 GPU 内核以及启动延迟(例如,GPU 内核开始与 CPU 操作结束之间的差值)。内核启动信息可以按以下方式生成:
analyzer = TraceAnalysis(trace_dir="/path/to/trace/dir")
kernel_info_df = analyzer.get_cuda_kernel_launch_stats()
下面是生成的数据帧的截图。
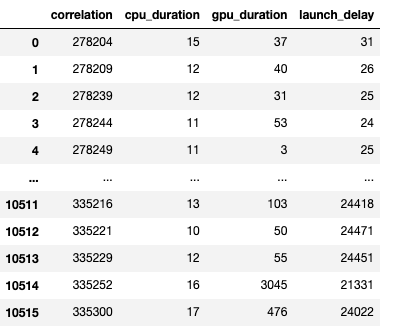
CPU 操作、GPU 内核和启动延迟的持续时间使我们能够找到以下内容:
短 GPU 内核 - 持续时间小于相应 CPU 运行时事件的 GPU 内核。
运行时事件异常值 - 持续时间过长的 CPU 运行时事件。
启动延迟异常值 - 启动耗时过长的 GPU 内核。
HTA 为上述三个类别中的每一个生成分布图。
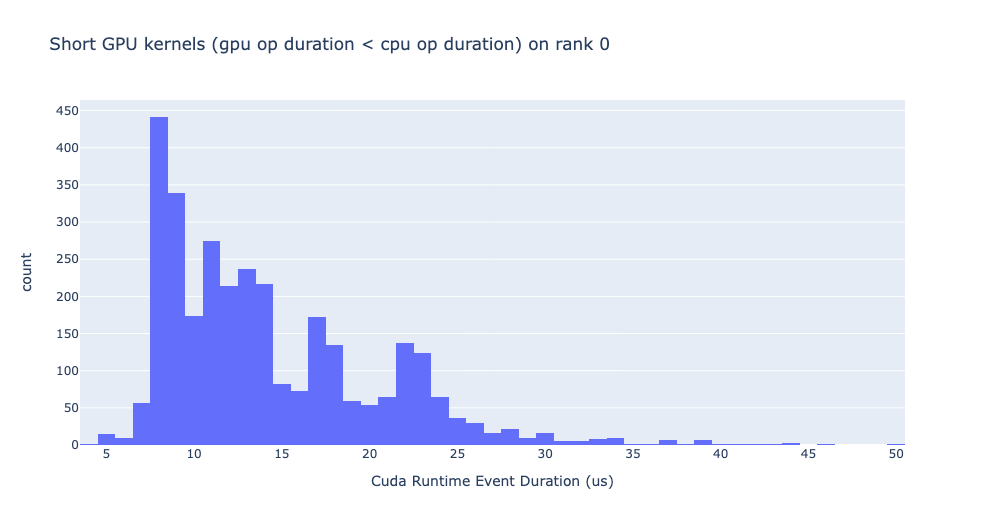
短 GPU 内核
通常,CPU 端的启动时间在 5-20 微秒之间。在某些情况下,GPU 执行时间低于启动时间本身。下图有助于我们了解代码中此类实例发生的频率。
运行时事件异常值
运行时异常值取决于用于分类异常值的截止值,因此 get_cuda_kernel_launch_stats API 提供了 runtime_cutoff 参数来配置该值。
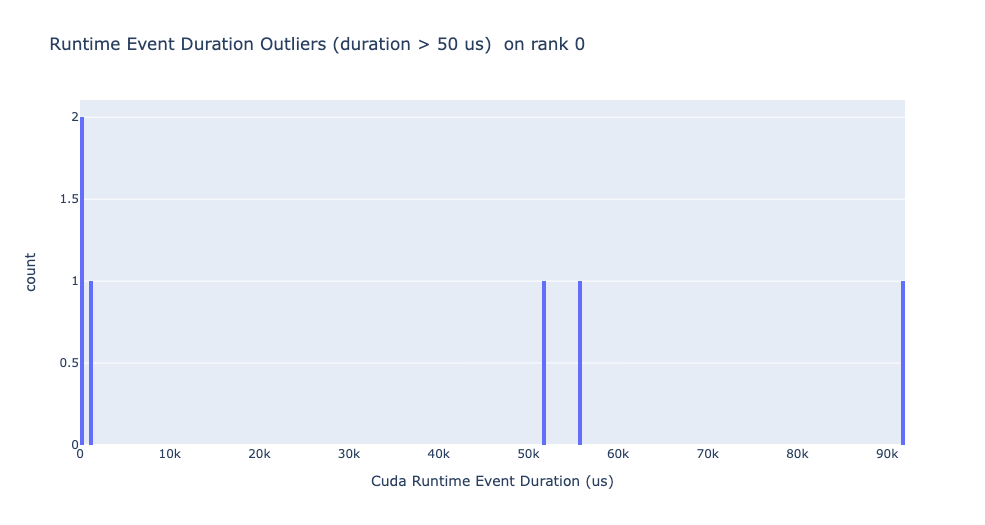
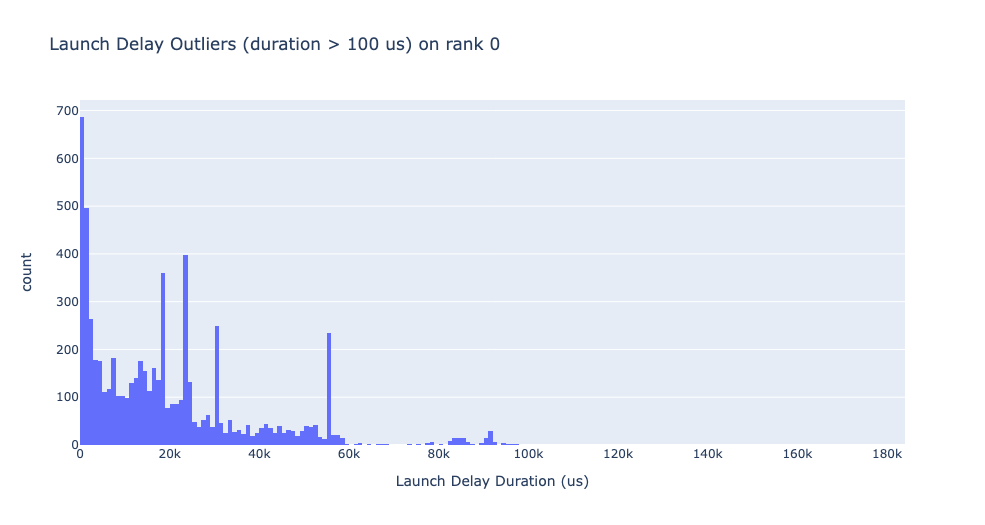
启动延迟异常值
启动延迟异常值取决于用于分类异常值的截止值,因此 get_cuda_kernel_launch_stats API 提供了 launch_delay_cutoff 参数来配置该值。
结论#
在本教程中,您学习了如何安装和使用 HTA,这是一个性能工具,可帮助您分析分布式训练工作流中的瓶颈。要了解如何使用 HTA 工具执行追踪差异分析,请参阅 使用整体追踪分析进行追踪差异。
