动态形状¶
动态形状意味着一个张量的形状取决于另一个张量的值。例如
>>> import torch, torch_xla
>>> in_tensor = torch.randint(low=0, high=2, size=(5,5), device='xla:0')
>>> out_tensor = torch.nonzero(in_tensor)
out_tensor 的形状取决于 in_tensor 的值,并受到 in_tensor 形状的限制。换句话说,如果你这样做
>>> print(out_tensor.shape)
torch.Size([<=25, 2])
第一个维度取决于 in_tensor 的值,其最大值为 25。我们称第一个维度为动态维度。第二个维度不依赖于任何上游张量,因此我们称之为静态维度。
动态形状可以进一步分为有界动态形状和无界动态形状。
有界动态形状:指其动态维度受静态值约束的形状。它适用于需要静态内存分配的加速器(例如 TPU)。
无界动态形状:指其动态维度可以无限增大的形状。它适用于不需要静态内存分配的加速器(例如 GPU)。
目前,仅支持有界动态形状,且仍处于实验阶段。
有界动态形状¶
目前,我们支持在 TPU 上具有动态输入尺寸的多层感知机模型(MLP)。
此功能由一个标志控制:XLA_EXPERIMENTAL="nonzero:masked_select"。要运行启用此功能并进行修改的模型,请使用以下环境变量启动 Python:
XLA_EXPERIMENTAL="nonzero:masked_select:masked_scatter" python your_scripts.py
以下是我们运行 MLP 模型 100 次迭代时获得的一些数字:
无动态形状 |
有动态形状 |
|
|---|---|---|
端到端训练时间 |
29.49 |
20.03 |
编译次数 |
102 |
49 |
编译缓存命中 |
198 |
1953 |
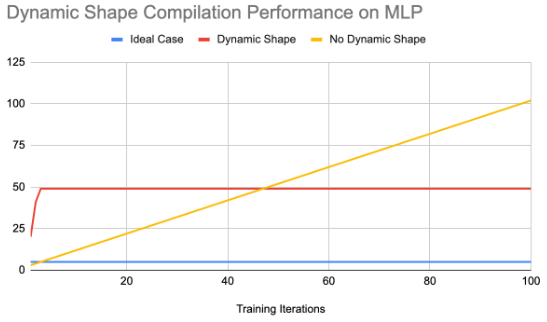
动态形状的动机之一是减少形状在迭代之间不断变化时过多的重新编译次数。从上图可以看出,编译次数减少了一半,从而缩短了训练时间。
如何尝试
XLA_EXPERIMENTAL="nonzero:masked_select" PJRT_DEVICE=TPU python3 pytorch/xla/test/ds/test_dynamic_shape_models.py TestDynamicShapeModels.test_backward_pass_with_dynamic_input
