SPMD 用户指南¶
在本用户指南中,您将了解 SPMD 如何集成到 PyTorch/XLA 中。
有关 SPMD 计算模型的概念指南,请参阅《如何扩展您的模型》一书中的分片矩阵及其乘法部分。
什么是 PyTorch/XLA SPMD?¶
SPMD 是一个通用的机器学习工作负载的自动并行化系统。XLA 编译器将单设备程序转换为分区程序,并根据用户提供的分片提示添加适当的集体通信。此功能允许开发人员编写 PyTorch 程序,就好像它们运行在单个大型设备上一样,而无需任何自定义的分片计算操作和/或用于扩展的集体通信。
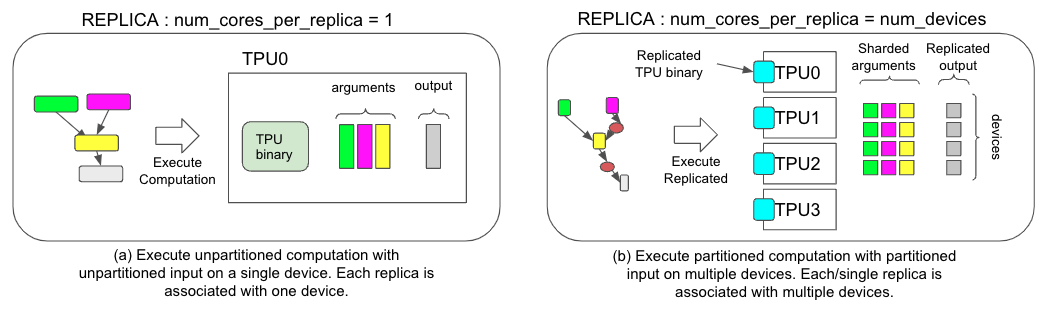 图 1. 两种不同执行策略的比较,(a) 非 SPMD 模式,(b) SPMD 模式。
图 1. 两种不同执行策略的比较,(a) 非 SPMD 模式,(b) SPMD 模式。
如何使用 PyTorch/XLA SPMD?¶
以下是使用 SPMD 的示例
import numpy as np
import torch
import torch_xla.core.xla_model as xm
import torch_xla.runtime as xr
import torch_xla.distributed.spmd as xs
from torch_xla.distributed.spmd import Mesh
# Enable XLA SPMD execution mode.
xr.use_spmd()
# Device mesh, this and partition spec as well as the input tensor shape define the individual shard shape.
num_devices = xr.global_runtime_device_count()
mesh_shape = (num_devices, 1)
device_ids = np.array(range(num_devices))
mesh = Mesh(device_ids, mesh_shape, ('data', 'model'))
t = torch.randn(8, 4).to('xla')
# Mesh partitioning, each device holds 1/8-th of the input
partition_spec = ('data', 'model')
xs.mark_sharding(t, mesh, partition_spec)
SPMD 模式¶
要使用 SPMD,您需要通过 `xr.use_spmd()` 来启用它。在 SPMD 模式下,只有一个逻辑设备。分布式计算和集体通信由 `mark_sharding` 处理。请注意,您不能将 SPMD 与其他分布式库混合使用。
Mesh(设备网格)¶
SPMD 编程模型围绕设备网格的概念构建。设备网格是计算设备(例如 TPU 核心)的 N 维逻辑排列,可以在网格的轴上请求类似 MPI 的集体操作。设备网格形状不一定反映物理网络布局。您可以在同一组物理设备上创建不同的设备网格形状。例如,一个 512 核的 TPU 切片可以被视为 16x16x2 的 3D 网格、32x16 的 2D 网格或 512 的 1D 网格,具体取决于您如何分区张量。使用 `Mesh` 类来创建设备网格。
在以下代码片段中
mesh_shape = (num_devices, 1)
device_ids = np.array(range(num_devices))
mesh = Mesh(device_ids, mesh_shape, ('data', 'model'))
`mesh_shape` 是一个元组,其元素描述了设备网格每个轴的大小。将元组中的元素相乘,应等于环境中物理设备的总数。
`device_ids` 指定了网格中物理设备的排序,采用行优先顺序。它始终是一个包含从 0 到 `num_devices - 1` 的整数的一维 numpy 数组,其中 `num_devices` 是环境中设备的总数。每个 ID 都索引到 `xr.global_runtime_device_attributes()` 中的设备列表。最简单的排序是 `np.array(range(num_devices))`,但调整设备排序和网格形状以利用底层物理互连可以提高效率。
最佳实践是为每个网格轴指定一个名称。然后,您可以将张量的每个维度分片到特定的网格轴上,以实现所需的并行化。在前面的示例中,第一个网格维度是 `data` 维度,第二个网格维度是 `model` 维度。
通过以下方式检索更多网格信息:
>>> mesh.shape()
OrderedDict([('data', 4), ('model', 1)])
>>> mesh.get_logical_mesh()
array([[0], [1], [2], [3]])
# Details about these 4 TPUs
>>> xr.global_runtime_device_attributes()
[{'core_on_chip': 0, 'num_cores': 1, 'coords': [0, 0, 0], 'name': 'TPU:0'},
{'core_on_chip': 0, 'num_cores': 1, 'coords': [1, 0, 0], 'name': 'TPU:1'},
{'core_on_chip': 0, 'num_cores': 1, 'coords': [0, 1, 0], 'name': 'TPU:2'},
{'core_on_chip': 0, 'num_cores': 1, 'coords': [1, 1, 0], 'name': 'TPU:3'}]
如果您的工作负载同时在多个 TPU 切片上运行,设备属性将包含一个 `slice_index`,指示其所在的切片。
# Details about 8 TPUs allocated over 2 slices
>>> xr.global_runtime_device_attributes()
[{'num_cores': 1, 'core_on_chip': 0, 'slice_index': 0, 'coords': [0, 0, 0], 'name': 'TPU:0'},
{'num_cores': 1, 'core_on_chip': 0, 'slice_index': 0, 'coords': [1, 0, 0], 'name': 'TPU:1'},
{'num_cores': 1, 'core_on_chip': 0, 'slice_index': 0, 'coords': [0, 1, 0], 'name': 'TPU:2'},
{'num_cores': 1, 'core_on_chip': 0, 'slice_index': 0, 'coords': [1, 1, 0], 'name': 'TPU:3'},
{'num_cores': 1, 'core_on_chip': 0, 'slice_index': 1, 'coords': [0, 0, 0], 'name': 'TPU:4'},
{'num_cores': 1, 'core_on_chip': 0, 'slice_index': 1, 'coords': [1, 0, 0], 'name': 'TPU:5'},
{'num_cores': 1, 'core_on_chip': 0, 'slice_index': 1, 'coords': [0, 1, 0], 'name': 'TPU:6'},
{'num_cores': 1, 'core_on_chip': 0, 'slice_index': 1, 'coords': [1, 1, 0], 'name': 'TPU:7'}]
在此示例中,设备 ID 7 将引用第二个切片中坐标为 [1, 1, 0] 的 TPU。
Partition spec(分区规范)¶
在以下代码片段中
partition_spec = ('data', 'model')
xs.mark_sharding(t, mesh, partition_spec)
`partition_spec` 的秩与输入张量相同。每个维度描述了相应的输入张量维度如何在设备网格上分片。在上面的示例中,张量 `t` 的第一个维度分片到 `data` 维度,第二个维度分片到 `model` 维度。
用户也可以分片秩与网格形状不同的张量。
t1 = torch.randn(8, 8, 16).to(device)
t2 = torch.randn(8).to(device)
# First dimension is being replicated.
xs.mark_sharding(t1, mesh, (None, 'data', 'model'))
# First dimension is being sharded at data dimension.
# model dimension is used for replication when omitted.
xs.mark_sharding(t2, mesh, ('data',))
# First dimension is sharded across both mesh axes.
xs.mark_sharding(t2, mesh, (('data', 'model'),))
哪个设备持有哪个分片?¶
传递给 `mark_sharding` 的张量的每个维度将根据分区规范中对应的元素在设备上进行分割。例如,给定一个形状为 `[M, N]` 的张量 `t`,一个形状为 `[X, Y]` 的网格,以及一个形状为 `('X', 'Y')` 的分区规范,张量的第一个维度将被分割 `X` 次,第二个维度将被分割 `Y` 次。由 `device_ids[i]` 标识的设备将持有数据子集,该子集为 `t[a * M / X : (a + 1) * M / X, b * N / Y : (b + 1) * N / Y]`,其中 `a = i // Y` 且 `b = i % Y`。
这假设 `M` 和 `N` 分别可以被 `X` 和 `Y` 整除。如果不能,最后一个设备可能包含一些填充。
您还可以使用我们位于SPMD 调试工具的 SPMD 调试工具来可视化张量如何在设备上分片。
