(第一部分) 使用 float8 进行预训练¶
TorchAO 通过利用我们集成到合作伙伴框架中的量化和稀疏技术,提供端到端的预训练、微调和推理模型优化流程。这是展示此端到端流程的 3 个教程中的第 1 部分,重点关注预训练步骤。
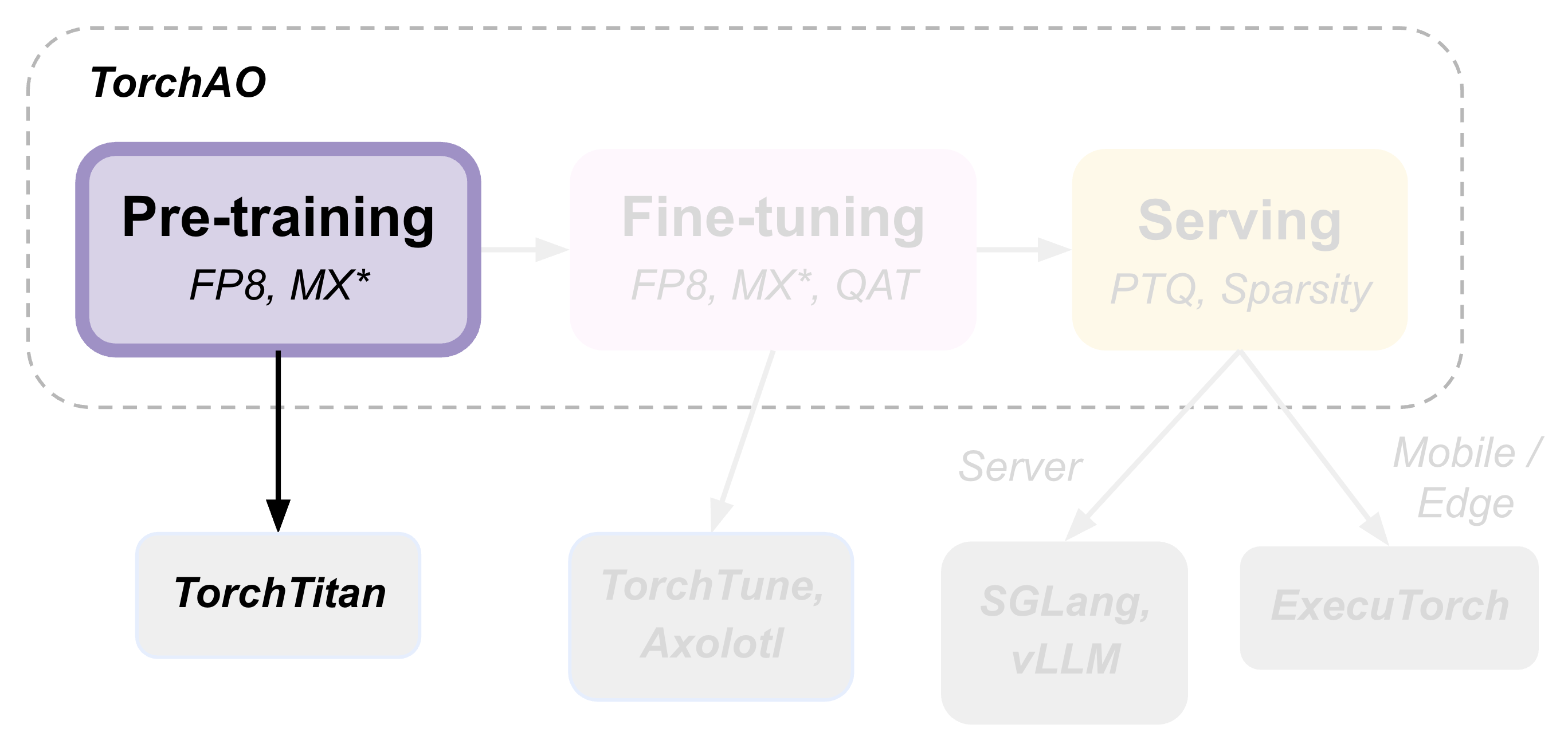
使用 torchao 和 float8 进行预训练可以在 512 个 GPU 集群上提供高达 1.5 倍的加速,在 2K H200 集群上使用最新的 torchao.float8 行式(rowwise)配方可提供高达 1.34-1.43 倍的加速。
在本教程中,我们将展示使用 torchao.float8 配方进行预训练的两种方法:
使用 torchtitan 进行预训练,这是 PyTorch 官方预训练框架,具有原生 torchao 集成。
直接使用 torchao 进行预训练,将 torchao 的 float8 训练配方集成到您自己的预训练代码中。
使用 torchtitan 进行预训练¶
在本教程中,我们将使用 torchtitan 和 torchao 的 float8 训练配方(行式缩放和张量式缩放)来预训练 Llama3-8B。
Torchtitan 是 PyTorch 的官方预训练框架,它与 torchao 原生集成,并支持多种流行的旗舰模型,具有常见的并行形式、float8 训练、分布式检查点等。有关更多详细信息,请参阅 torchtitan 的文档。
您可以使用此工作流程快速开始“开箱即用”的体验。用户通常会 fork torchtitan,并在准备好后在其基础上进行构建。
先决条件¶
(推荐) 使用 conda 或 venv 创建一个新的虚拟环境。
安装 torchtitan,包括“下载分词器”步骤。
现在您可以开始使用以下任一配方进行预训练作业了!
行式缩放¶
在 torchtitan 的根目录下运行以下命令,以启动一个在 8 个 GPU 上使用 float8 行式训练的 Llama3-8B 训练作业:
NGPU=8 CONFIG_FILE="./torchtitan/models/llama3/train_configs/llama3_8b.toml" ./run_train.sh --training.compile --model.converters="float8" --float8.recipe_name="rowwise"
当使用 1 个以上的 GPU 时,Torchtitan 将自动使用 FSDP2 来并行化训练。要使用其他并行形式、修改超参数或更改其他训练配置,您可以直接编辑 llama3_8b.toml 文件或使用命令行标志(运行命令并带 --help 参数可查看更多选项)。
您应该会看到类似以下的终端输出:
[rank0]:[titan] 2025-06-04 08:51:48,074 - root - INFO - step: 1 loss: 12.2254 memory: 27.34GiB(28.78%) tps: 375 tflops: 21.73 mfu: 2.20%
[rank0]:[titan] 2025-06-04 08:51:58,557 - root - INFO - step: 10 loss: 10.7069 memory: 30.99GiB(32.62%) tps: 7,034 tflops: 407.35 mfu: 41.19%
[rank0]:[titan] 2025-06-04 08:52:10,224 - root - INFO - step: 20 loss: 8.9196 memory: 30.99GiB(32.62%) tps: 7,022 tflops: 406.65 mfu: 41.12%
[rank0]:[titan] 2025-06-04 08:52:21,904 - root - INFO - step: 30 loss: 8.1423 memory: 30.99GiB(32.62%) tps: 7,014 tflops: 406.23 mfu: 41.08%
如您所见,忽略预热步骤,我们达到了约 7k TPS,峰值内存使用量为 30.99GB。为了与 bfloat16 训练进行性能比较,您可以删除 --model.converters="float8" --float8.recipe_name="rowwise" 标志并运行相同的命令,以查看 bfloat16 训练的基线性能。
NGPU=8 CONFIG_FILE="./torchtitan/models/llama3/train_configs/llama3_8b.toml" ./run_train.sh --training.compile
您应该会看到以下输出:
[rank0]:[titan] 2025-06-04 11:02:37,404 - root - INFO - step: 1 loss: 12.2611 memory: 27.22GiB(28.65%) tps: 595 tflops: 34.47 mfu: 3.49%
[rank0]:[titan] 2025-06-04 11:02:49,027 - root - INFO - step: 10 loss: 10.4260 memory: 30.89GiB(32.51%) tps: 6,344 tflops: 367.39 mfu: 37.15%
[rank0]:[titan] 2025-06-04 11:03:01,988 - root - INFO - step: 20 loss: 8.9482 memory: 30.89GiB(32.51%) tps: 6,321 tflops: 366.06 mfu: 37.01%
[rank0]:[titan] 2025-06-04 11:03:14,991 - root - INFO - step: 30 loss: 8.1183 memory: 30.89GiB(32.51%) tps: 6,300 tflops: 364.89 mfu: 36.89%
[rank0]:[titan] 2025-06-04 11:03:28,013 - root - INFO - step: 40 loss: 7.4659 memory: 30.89GiB(32.51%) tps: 6,291 tflops: 364.36 mfu: 36.84%
[rank0]:[titan] 2025-06-04 11:03:39,769 - root - INFO - [GC] Peforming periodical GC collection. 0.02 seconds.
如您所见,bfloat16 基线达到了约 6.3k TPS,峰值内存使用量为 30.89GB。
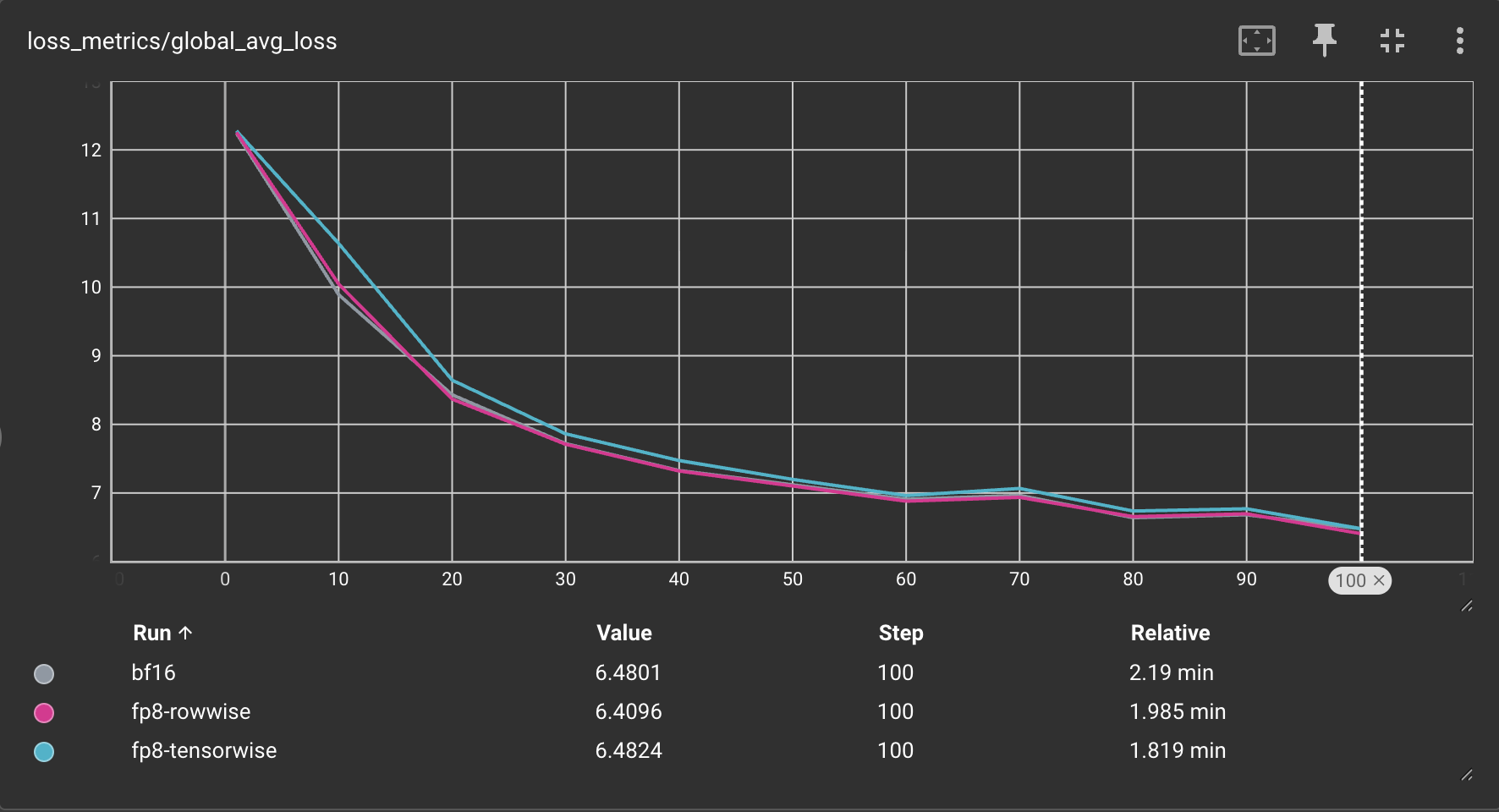
这意味着我们的 float8 行式缩放配方比 bfloat16 基线实现了1.11 倍的更高吞吐量,同时峰值内存使用量几乎相同!
请注意,使用张量式缩放配方可以实现更高的吞吐量提升,该配方在性能与准确度之间存在不同的权衡。
张量式缩放¶
使用张量式缩放的 Float8 训练是默认配方,因此我们可以省略 --float8.recipe_name 标志。
NGPU=8 CONFIG_FILE="./torchtitan/models/llama3/train_configs/llama3_8b.toml" ./run_train.sh --training.compile --model.converters="float8"
您应该会看到类似以下的输出:
[rank0]:[titan] 2025-06-04 10:52:19,648 - root - INFO - step: 1 loss: 12.2648 memory: 27.28GiB(28.71%) tps: 557 tflops: 32.29 mfu: 3.26%
[rank0]:[titan] 2025-06-04 10:52:29,475 - root - INFO - step: 10 loss: 10.9106 memory: 30.91GiB(32.53%) tps: 7,503 tflops: 434.53 mfu: 43.94%
[rank0]:[titan] 2025-06-04 10:52:40,166 - root - INFO - step: 20 loss: 9.0774 memory: 30.91GiB(32.53%) tps: 7,663 tflops: 443.78 mfu: 44.87%
[rank0]:[titan] 2025-06-04 10:52:50,885 - root - INFO - step: 30 loss: 8.3233 memory: 30.91GiB(32.53%) tps: 7,643 tflops: 442.66 mfu: 44.76%
[rank0]:[titan] 2025-06-04 10:53:01,613 - root - INFO - step: 40 loss: 7.6150 memory: 30.91GiB(32.53%) tps: 7,637 tflops: 442.27 mfu: 44.72%
如您所见,我们达到了约 7.6k TPS,峰值内存使用量为 30.91GB,这比 bfloat16 基线高出 1.21 倍的吞吐量!
选择配方¶
简而言之:行式缩放更适合优先考虑更准确的数值和训练稳定性的作业,而张量式更适合优先考虑训练吞吐量的作业。
张量式缩放的更高吞吐量是以略高的量化误差为代价的(即,与行式缩放相比,数值完整性有所降低)。这是因为行式缩放使用更精细的缩放因子(每行而不是每张量),这限制了可能导致缩放过程中下溢的异常值的影响。
您可以在下面看到在 8xH100 GPU 上训练 Llama3-8B 时,bfloat16、float8 张量式和 float8 行式训练的损失曲线对比:
重要说明¶
目前,torchtitan 中的 float8 训练仅支持 2 个及以上的 GPU,不支持单个 GPU 训练。
您必须使用
--training.compile来实现高性能。torchao float8 训练配方是基于torch.compile原生构建的,因此可以直接使用!
直接使用 torchao 进行预训练¶
在本教程中,我们将直接使用 torchao API 预训练一个玩具模型。
您可以使用此工作流程将 torchao 直接集成到您自己的自定义预训练代码中。
先决条件¶
(推荐) 使用 conda 或 venv 创建一个新的虚拟环境。
现在您可以直接将 torchao 集成到您的训练代码中了!
模型转换 API¶
用于将模型转换为使用 float8 训练的 torchao API 是:convert_to_float8_training。此 API 将递归地将模型中的 nn.Linear 模块转换为使用 Float8Linear。
您可以使用 module_filter_fn 参数来确定哪些 nn.Linear 层应被替换为使用 Float8Linear。
您应该参考此性能基准表,以了解相对于 bfloat16,对于给定的 GEMM 大小可以预期什么样的性能提升。
下面是一个展示如何使用它的代码片段:
import torch
from torch import nn
import torch.nn.functional as F
from torchao.float8.float8_linear_utils import convert_to_float8_training
from torchao.float8.float8_linear import Float8Linear
from torchao.float8 import convert_to_float8_training
# create model and sample input
m = nn.Sequential(
nn.Linear(2048, 4096),
nn.Linear(4096, 128),
nn.Linear(128, 1),
).bfloat16().cuda()
x = torch.randn(4096, 2048, device="cuda", dtype=torch.bfloat16)
optimizer = torch.optim.AdamW(m.parameters(), lr=1e-3)
# optional: filter modules from being eligible for float8 conversion
def module_filter_fn(mod: torch.nn.Module, fqn: str):
# don't convert the last module
if fqn == "1":
return False
# don't convert linear modules with weight dimensions not divisible by 16
if isinstance(mod, torch.nn.Linear):
if mod.in_features % 16 != 0 or mod.out_features % 16 != 0:
return False
return True
# convert specified `torch.nn.Linear` modules to `Float8Linear`
convert_to_float8_training(m, module_filter_fn=module_filter_fn)
# enable torch.compile for competitive performance
m = torch.compile(m)
# toy training loop
for _ in range(10):
optimizer.zero_grad()
output = m(x)
# use fake labels for demonstration purposes
fake_labels = torch.ones_like(output)
loss = F.mse_loss(output, fake_labels)
loss.backward()
optimizer.step()
# save the model
torch.save({
'model': m,
'model_state_dict': m.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
}, 'checkpoint.pth')
在预训练模型后,您可以选择将其微调到更特定于域的数据集,并为其在推理时的量化进行适配。在本教程的下一部分中,我们将探讨在微调步骤中的一些模型优化选项。
