


注意
转到末尾 下载完整的示例代码。
自定义 Python 运算符#
创建时间:2024 年 6 月 18 日 | 最后更新:2025 年 3 月 19 日 | 最后验证:2024 年 11 月 5 日
如何将用 Python 编写的自定义运算符与 PyTorch 集成
如何使用
torch.library.opcheck测试自定义运算符
PyTorch 2.4 或更高版本
PyTorch 提供了一个大型运算符库,可用于 Tensor(例如 torch.add、torch.sum 等)。但是,您可能希望使用 PyTorch 的新自定义运算符,也许是由第三方库编写的。本教程将展示如何包装 Python 函数,使其行为类似于 PyTorch 的原生运算符。您可能希望在 PyTorch 中创建自定义运算符的原因包括:
将任意 Python 函数视为对
torch.compile不透明的可调用对象(即,阻止torch.compile跟踪该函数)。为任意 Python 函数添加训练支持
使用 torch.library.custom_op() 创建 Python 自定义运算符。使用 C++ TORCH_LIBRARY API 创建 C++ 自定义运算符(这些在无 Python 的环境中工作)。有关更多详细信息,请参阅 自定义运算符登陆页面。
请注意,如果您的操作可以表示为现有 PyTorch 运算符的组合,那么通常不需要使用自定义运算符 API — 所有内容(例如 torch.compile、训练支持)都应该可以正常工作。
示例:将 PIL 的 crop 包装成自定义运算符#
假设我们正在使用 PIL 的 crop 操作。
import torch
from torchvision.transforms.functional import to_pil_image, pil_to_tensor
import PIL
import IPython
import matplotlib.pyplot as plt
def crop(pic, box):
img = to_pil_image(pic.cpu())
cropped_img = img.crop(box)
return pil_to_tensor(cropped_img).to(pic.device) / 255.
def display(img):
plt.imshow(img.numpy().transpose((1, 2, 0)))
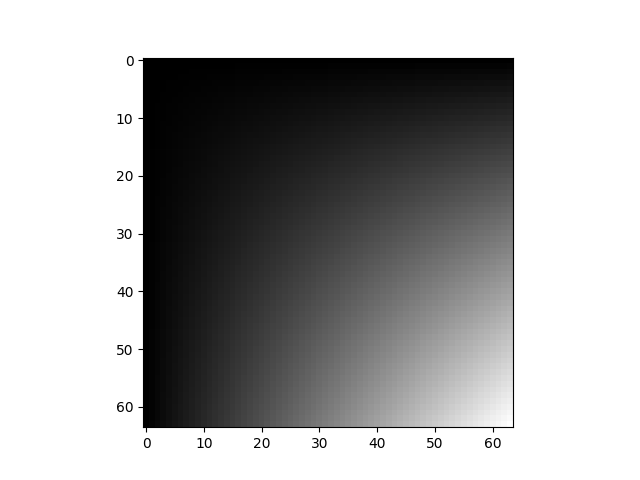
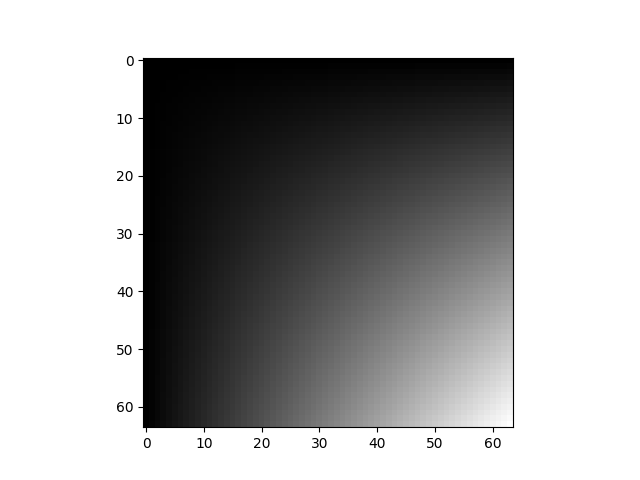
img = torch.ones(3, 64, 64)
img *= torch.linspace(0, 1, steps=64) * torch.linspace(0, 1, steps=64).unsqueeze(-1)
display(img)
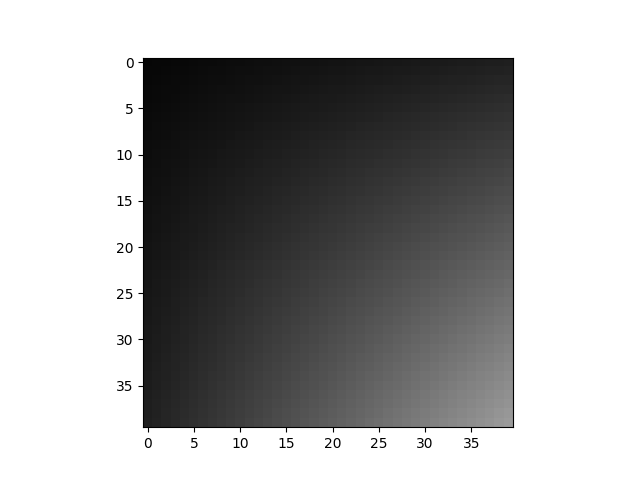
cropped_img = crop(img, (10, 10, 50, 50))
display(cropped_img)
torch.compile 默认情况下无法有效处理 crop:torch.compile 会在它无法处理的函数上引发“图中断”,而图中断不利于性能。下面的代码通过引发错误来演示这一点(torch.compile 配合 fullgraph=True 在发生图中断时会引发错误)。
为了将 crop 黑盒化以供 torch.compile 使用,我们需要做两件事:
将函数包装成 PyTorch 自定义运算符。
为该运算符添加一个“
FakeTensor内核”(也称为“元内核”)。给定一些FakeTensors输入(不具有存储的虚拟 Tensor),此函数应返回您选择的具有正确 Tensor 元数据(形状/步幅/dtype/设备)的虚拟 Tensor。
from typing import Sequence
# Use torch.library.custom_op to define a new custom operator.
# If your operator mutates any input Tensors, their names must be specified
# in the ``mutates_args`` argument.
@torch.library.custom_op("mylib::crop", mutates_args=())
def crop(pic: torch.Tensor, box: Sequence[int]) -> torch.Tensor:
img = to_pil_image(pic.cpu())
cropped_img = img.crop(box)
return (pil_to_tensor(cropped_img) / 255.).to(pic.device, pic.dtype)
# Use register_fake to add a ``FakeTensor`` kernel for the operator
@crop.register_fake
def _(pic, box):
channels = pic.shape[0]
x0, y0, x1, y1 = box
result = pic.new_empty(y1 - y0, x1 - x0, channels).permute(2, 0, 1)
# The result should have the same metadata (shape/strides/``dtype``/device)
# as running the ``crop`` function above.
return result
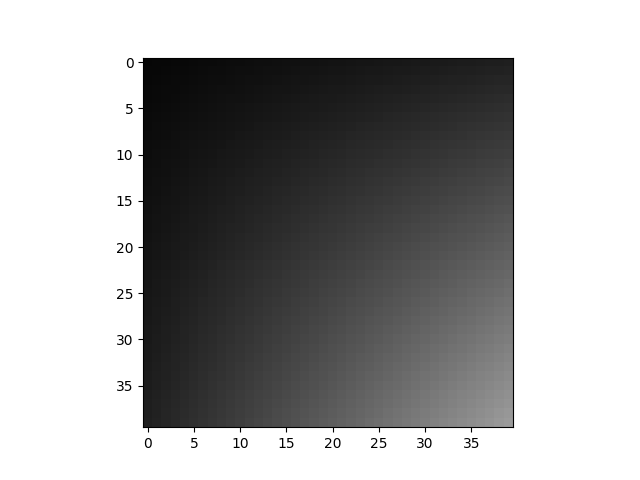
完成此操作后,crop 将不再有图中断。
display(cropped_img)
为 crop 添加训练支持#
使用 torch.library.register_autograd 为运算符添加训练支持。优先使用此方法,而不是直接使用 torch.autograd.Function;某些 autograd.Function 与 PyTorch 运算符注册 API 的组合可能会导致(并且已经导致)与 torch.compile 组合时出现静默不正确的情况。
如果您不需要训练支持,则无需使用 torch.library.register_autograd。如果您最终使用没有自动微分注册的 custom_op 进行训练,我们将发出错误消息。
crop 的梯度公式本质上是 PIL.paste(我们将推导过程留给读者作为练习)。首先,我们将 paste 包装成一个自定义运算符。
@torch.library.custom_op("mylib::paste", mutates_args=())
def paste(im1: torch.Tensor, im2: torch.Tensor, coord: Sequence[int]) -> torch.Tensor:
assert im1.device == im2.device
assert im1.dtype == im2.dtype
im1_pil = to_pil_image(im1.cpu())
im2_pil = to_pil_image(im2.cpu())
PIL.Image.Image.paste(im1_pil, im2_pil, coord)
return (pil_to_tensor(im1_pil) / 255.).to(im1.device, im1.dtype)
@paste.register_fake
def _(im1, im2, coord):
assert im1.device == im2.device
assert im1.dtype == im2.dtype
return torch.empty_like(im1)
现在,我们使用 register_autograd 来指定 crop 的梯度公式。
def backward(ctx, grad_output):
grad_input = grad_output.new_zeros(ctx.pic_shape)
grad_input = paste(grad_input, grad_output, ctx.coords)
return grad_input, None
def setup_context(ctx, inputs, output):
pic, box = inputs
ctx.coords = box[:2]
ctx.pic_shape = pic.shape
crop.register_autograd(backward, setup_context=setup_context)
请注意,反向传播必须是 PyTorch 可理解的运算符的组合,这就是为什么我们将 paste 包装成自定义运算符,而不是直接使用 PIL 的 paste。
这是正确的梯度,在裁剪区域为 1(白色),在未使用区域为 0(黑色)。
测试 Python 自定义运算符#
使用 torch.library.opcheck 测试自定义运算符是否已正确注册。这不会测试梯度在数学上是否正确;请为此编写单独的测试(手动测试或使用 torch.autograd.gradcheck)。
要使用 opcheck,请向其传递一组示例输入进行测试。如果您的运算符支持训练,则示例应包含需要 grad 的 Tensor。如果您的运算符支持多个设备,则示例应包含来自每个设备的 Tensor。
examples = [
[torch.randn(3, 64, 64), [0, 0, 10, 10]],
[torch.randn(3, 91, 91, requires_grad=True), [10, 0, 20, 10]],
[torch.randn(3, 60, 60, dtype=torch.double), [3, 4, 32, 20]],
[torch.randn(3, 512, 512, requires_grad=True, dtype=torch.double), [3, 4, 32, 45]],
]
for example in examples:
torch.library.opcheck(crop, example)
可变 Python 自定义运算符#
您还可以包装一个可变输入的 Python 函数作为自定义运算符。可变输入的函数很常见,因为许多底层内核就是这样编写的;例如,一个计算 sin 的内核可能接收输入和输出张量,并将 input.sin() 写入输出张量。
我们将使用 numpy.sin 来演示可变 Python 自定义运算符的示例。
import numpy as np
@torch.library.custom_op("mylib::numpy_sin", mutates_args={"output"}, device_types="cpu")
def numpy_sin(input: torch.Tensor, output: torch.Tensor) -> None:
assert input.device == output.device
assert input.device.type == "cpu"
input_np = input.numpy()
output_np = output.numpy()
np.sin(input_np, out=output_np)
由于该运算符不返回任何内容,因此无需注册 FakeTensor 内核(元内核)即可使其与 torch.compile 一起使用。
@torch.compile(fullgraph=True)
def f(x):
out = torch.empty(3)
numpy_sin(x, out)
return out
x = torch.randn(3)
y = f(x)
assert torch.allclose(y, x.sin())
这是 opcheck 的运行结果,告诉我们确实正确注册了该运算符。opcheck 会在您忘记将输出添加到 mutates_args 时出错,例如。
example_inputs = [
[torch.randn(3), torch.empty(3)],
[torch.randn(0, 3), torch.empty(0, 3)],
[torch.randn(1, 2, 3, 4, dtype=torch.double), torch.empty(1, 2, 3, 4, dtype=torch.double)],
]
for example in example_inputs:
torch.library.opcheck(numpy_sin, example)
结论#
在本教程中,我们学习了如何使用 torch.library.custom_op 在 Python 中创建自定义运算符,该运算符可与 torch.compile 和 autograd 等 PyTorch 子系统配合使用。
本教程提供了自定义运算符的基本介绍。有关更多详细信息,请参阅:
脚本总运行时间: (0 分钟 3.593 秒)
