


双重反向传播与自定义函数#
创建日期:2021 年 8 月 13 日 | 最后更新:2021 年 8 月 13 日 | 最后验证:2024 年 11 月 5 日
有时需要对反向传播图进行两次反向传播,例如计算高阶梯度。这需要对 autograd 的理解和一些注意事项来支持双重反向传播。并非所有能支持单次反向传播的函数都一定能支持双重反向传播。在本教程中,我们将展示如何编写支持双重反向传播的自定义 autograd 函数,并指出一些需要注意的地方。
在编写用于双重反向传播的自定义 autograd 函数时,重要的是了解自定义函数中的操作何时会被 autograd 记录,何时不会,以及最重要的是,save_for_backward 如何与所有这些协同工作。
自定义函数通过两种方式隐式影响 grad 模式
在前向传播过程中,autograd 不会记录在 forward 函数内执行的任何操作的图。当 forward 完成后,自定义函数的 backward 函数将成为 forward 输出的 grad_fn。
在反向传播过程中,如果指定了 create_graph,autograd 会记录用于计算反向传播的计算图。
接下来,为了理解 save_for_backward 如何与上述机制交互,我们可以通过几个例子来探讨。
保存输入#
考虑这个简单的平方函数。它会保存一个输入张量用于反向传播。当 autograd 能够记录反向传播中的操作时,双重反向传播会自动工作,因此当我们为反向传播保存输入时,通常无需担心,因为如果输入是任何需要 grad 的张量的函数,它应该有一个 grad_fn。这使得梯度能够正确传播。
import torch
class Square(torch.autograd.Function):
@staticmethod
def forward(ctx, x):
# Because we are saving one of the inputs use `save_for_backward`
# Save non-tensors and non-inputs/non-outputs directly on ctx
ctx.save_for_backward(x)
return x**2
@staticmethod
def backward(ctx, grad_out):
# A function support double backward automatically if autograd
# is able to record the computations performed in backward
x, = ctx.saved_tensors
return grad_out * 2 * x
# Use double precision because finite differencing method magnifies errors
x = torch.rand(3, 3, requires_grad=True, dtype=torch.double)
torch.autograd.gradcheck(Square.apply, x)
# Use gradcheck to verify second-order derivatives
torch.autograd.gradgradcheck(Square.apply, x)
我们可以使用 torchviz 来可视化图,以了解为什么这会起作用。
import torchviz
x = torch.tensor(1., requires_grad=True).clone()
out = Square.apply(x)
grad_x, = torch.autograd.grad(out, x, create_graph=True)
torchviz.make_dot((grad_x, x, out), {"grad_x": grad_x, "x": x, "out": out})
我们可以看到,关于 x 的梯度本身就是 x 的函数(dout/dx = 2x),并且这个函数的图已经正确构建。
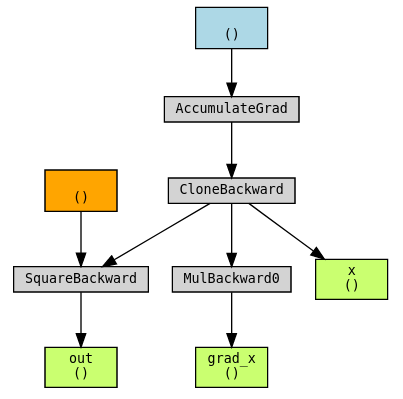
保存输出#
与前一个示例略有不同的是,它保存输出而不是输入。其机制是相似的,因为输出也与 grad_fn 相关联。
class Exp(torch.autograd.Function):
# Simple case where everything goes well
@staticmethod
def forward(ctx, x):
# This time we save the output
result = torch.exp(x)
# Note that we should use `save_for_backward` here when
# the tensor saved is an ouptut (or an input).
ctx.save_for_backward(result)
return result
@staticmethod
def backward(ctx, grad_out):
result, = ctx.saved_tensors
return result * grad_out
x = torch.tensor(1., requires_grad=True, dtype=torch.double).clone()
# Validate our gradients using gradcheck
torch.autograd.gradcheck(Exp.apply, x)
torch.autograd.gradgradcheck(Exp.apply, x)
使用 torchviz 可视化图。
out = Exp.apply(x)
grad_x, = torch.autograd.grad(out, x, create_graph=True)
torchviz.make_dot((grad_x, x, out), {"grad_x": grad_x, "x": x, "out": out})
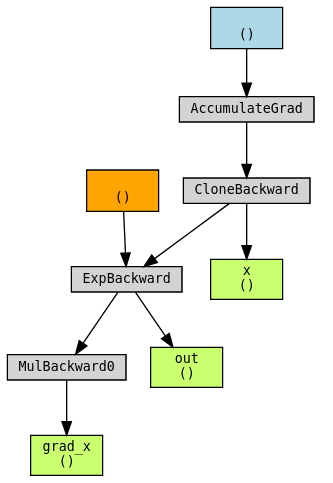
保存中间结果#
一个更棘手的情况是我们有时需要保存一个中间结果。我们通过实现以下函数来演示这种情况:
由于 sinh 的导数是 cosh,因此在反向传播计算中重用 forward 中的两个中间结果 exp(x) 和 exp(-x) 可能很有用。
然而,中间结果不应直接保存并在反向传播中使用。因为 forward 是在 no-grad 模式下执行的,如果 forward 过程的中间结果被用于计算 backward 中的梯度,那么梯度的 backward 图将不包含计算中间结果的操作。这会导致梯度不正确。
class Sinh(torch.autograd.Function):
@staticmethod
def forward(ctx, x):
expx = torch.exp(x)
expnegx = torch.exp(-x)
ctx.save_for_backward(expx, expnegx)
# In order to be able to save the intermediate results, a trick is to
# include them as our outputs, so that the backward graph is constructed
return (expx - expnegx) / 2, expx, expnegx
@staticmethod
def backward(ctx, grad_out, _grad_out_exp, _grad_out_negexp):
expx, expnegx = ctx.saved_tensors
grad_input = grad_out * (expx + expnegx) / 2
# We cannot skip accumulating these even though we won't use the outputs
# directly. They will be used later in the second backward.
grad_input += _grad_out_exp * expx
grad_input -= _grad_out_negexp * expnegx
return grad_input
def sinh(x):
# Create a wrapper that only returns the first output
return Sinh.apply(x)[0]
x = torch.rand(3, 3, requires_grad=True, dtype=torch.double)
torch.autograd.gradcheck(sinh, x)
torch.autograd.gradgradcheck(sinh, x)
使用 torchviz 可视化图。
out = sinh(x)
grad_x, = torch.autograd.grad(out.sum(), x, create_graph=True)
torchviz.make_dot((grad_x, x, out), params={"grad_x": grad_x, "x": x, "out": out})
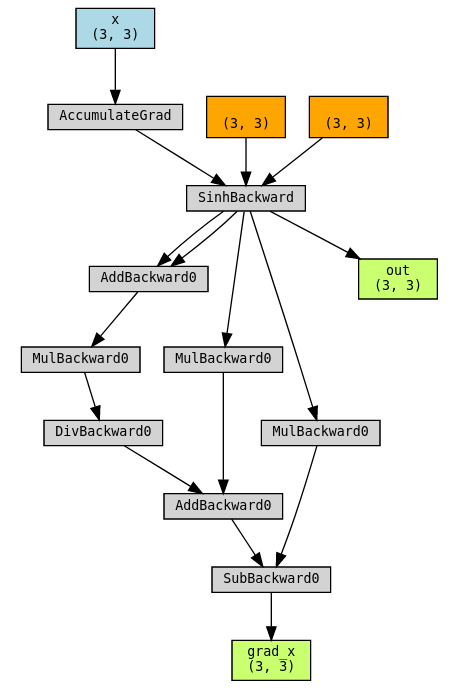
保存中间结果:不该怎么做#
现在我们展示当也没有将中间结果作为输出返回时会发生什么:grad_x 甚至不会有 backward 图,因为它仅仅是 exp 和 expnegx 的函数,而它们不需要 grad。
class SinhBad(torch.autograd.Function):
# This is an example of what NOT to do!
@staticmethod
def forward(ctx, x):
expx = torch.exp(x)
expnegx = torch.exp(-x)
ctx.expx = expx
ctx.expnegx = expnegx
return (expx - expnegx) / 2
@staticmethod
def backward(ctx, grad_out):
expx = ctx.expx
expnegx = ctx.expnegx
grad_input = grad_out * (expx + expnegx) / 2
return grad_input
使用 torchviz 可视化图。请注意,grad_x 不在图的范围内!
out = SinhBad.apply(x)
grad_x, = torch.autograd.grad(out.sum(), x, create_graph=True)
torchviz.make_dot((grad_x, x, out), params={"grad_x": grad_x, "x": x, "out": out})
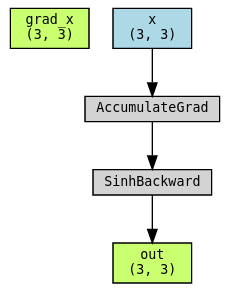
当反向传播未被跟踪时#
最后,我们来考虑一个 autograd 完全无法跟踪函数反向传播梯度的示例。我们可以设想 cube_backward 是一个可能需要非 PyTorch 库(如 SciPy 或 NumPy)的函数,或者它被写成 C++ 扩展。这里演示的解决方法是创建另一个自定义函数 CubeBackward,您也需要手动指定 cube_backward 的 backward!
def cube_forward(x):
return x**3
def cube_backward(grad_out, x):
return grad_out * 3 * x**2
def cube_backward_backward(grad_out, sav_grad_out, x):
return grad_out * sav_grad_out * 6 * x
def cube_backward_backward_grad_out(grad_out, x):
return grad_out * 3 * x**2
class Cube(torch.autograd.Function):
@staticmethod
def forward(ctx, x):
ctx.save_for_backward(x)
return cube_forward(x)
@staticmethod
def backward(ctx, grad_out):
x, = ctx.saved_tensors
return CubeBackward.apply(grad_out, x)
class CubeBackward(torch.autograd.Function):
@staticmethod
def forward(ctx, grad_out, x):
ctx.save_for_backward(x, grad_out)
return cube_backward(grad_out, x)
@staticmethod
def backward(ctx, grad_out):
x, sav_grad_out = ctx.saved_tensors
dx = cube_backward_backward(grad_out, sav_grad_out, x)
dgrad_out = cube_backward_backward_grad_out(grad_out, x)
return dgrad_out, dx
x = torch.tensor(2., requires_grad=True, dtype=torch.double)
torch.autograd.gradcheck(Cube.apply, x)
torch.autograd.gradgradcheck(Cube.apply, x)
使用 torchviz 可视化图。
out = Cube.apply(x)
grad_x, = torch.autograd.grad(out, x, create_graph=True)
torchviz.make_dot((grad_x, x, out), params={"grad_x": grad_x, "x": x, "out": out})
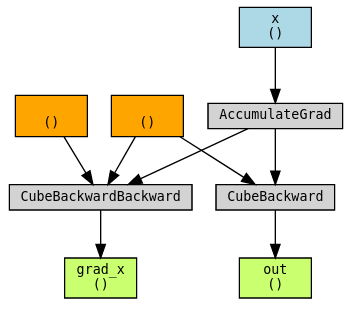
总而言之,您的自定义函数是否支持双重反向传播,仅取决于反向传播是否能被 autograd 跟踪。通过前两个示例,我们展示了双重反向传播开箱即用的情况。通过第三个和第四个示例,我们演示了在通常情况下反向传播函数无法被跟踪时,启用其跟踪的技术。
