


FSDP2 入门#
创建于:2022 年 3 月 17 日 | 最后更新:2025 年 9 月 2 日 | 最后验证:2024 年 11 月 5 日
作者:Wei Feng, Will Constable, Yifan Mao
注意
 从 pytorch/examples 查看本教程中的代码。FSDP1 已弃用。FSDP1 教程已存档在 [1] 和 [2]
从 pytorch/examples 查看本教程中的代码。FSDP1 已弃用。FSDP1 教程已存档在 [1] 和 [2]
FSDP2 工作原理#
在 DistributedDataParallel (DDP) 训练中,每个 rank 拥有一个模型副本并处理一个数据批次,最后使用 all-reduce 在 ranks 之间同步梯度。
与 DDP 相比,FSDP 通过分片模型参数、梯度和优化器状态来减少 GPU 内存占用。这使得训练无法放入单个 GPU 的模型成为可能。如下图所示,
在前向和后向计算之外,参数是完全分片的
在前向和后向计算之前,分片参数被 all-gather 成未分片参数
在后向计算内部,本地未分片梯度被 reduce-scatter 成分片梯度
优化器使用分片梯度更新分片参数,从而产生分片优化器状态
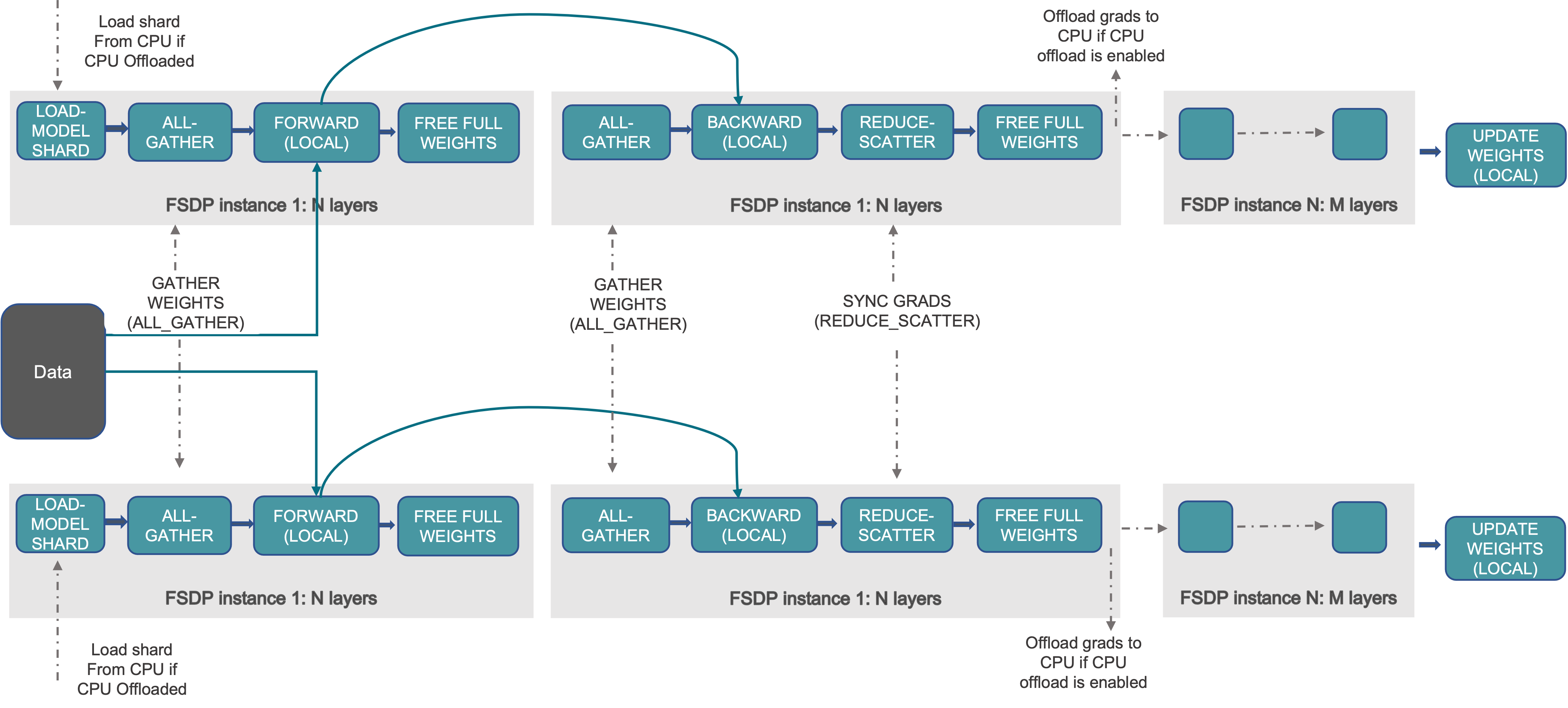
FSDP 可以被认为是 DDP 的 all-reduce 操作分解为 reduce-scatter 和 all-gather 操作
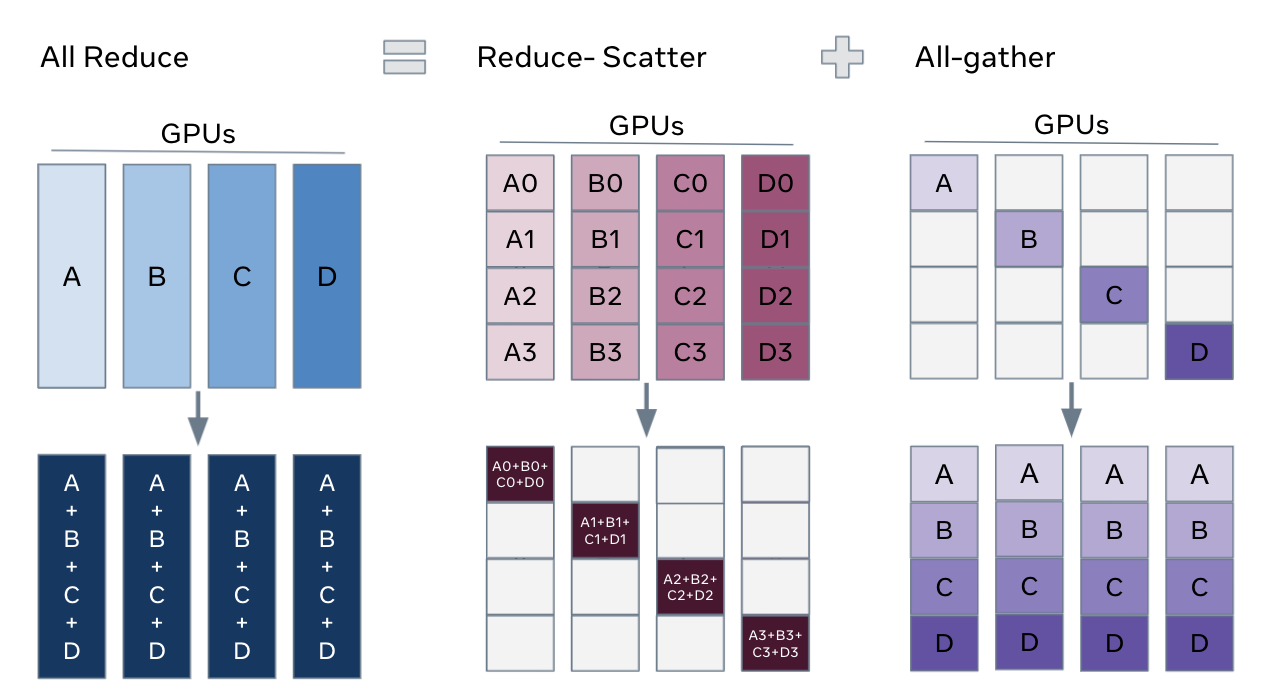
与 FSDP1 相比,FSDP2 具有以下优点
如何使用 FSDP2#
模型初始化#
在子模块上应用 fully_shard:与 DDP 不同,我们应该在子模块以及根模型上应用 fully_shard。在下面的 Transformer 示例中,我们首先在每个层上应用了 fully_shard,然后是根模型
在
layers[i]的前向计算过程中,其余层被分片以减少内存占用在
fully_shard(model)内部,FSDP2 会排除model.layers中的参数,并将剩余参数分类到参数组中,以便高效地进行 all-gather 和 reduce-scatter。fully_shard将分片模型移动到实际的训练设备(例如cuda)
命令:torchrun --nproc_per_node 2 train.py
from torch.distributed.fsdp import fully_shard, FSDPModule
model = Transformer()
for layer in model.layers:
fully_shard(layer)
fully_shard(model)
assert isinstance(model, Transformer)
assert isinstance(model, FSDPModule)
print(model)
# FSDPTransformer(
# (tok_embeddings): Embedding(...)
# ...
# (layers): 3 x FSDPTransformerBlock(...)
# (output): Linear(...)
# )
我们可以使用 print(model) 来检查嵌套的包装。 FSDPTransformer 是 Transformer 和 FSDPModule 的联合类。对于 FSDPTransformerBlock 也是如此。所有 FSDP2 公共 API 都通过 FSDPModule 公开。例如,用户可以调用 model.unshard() 来手动控制 all-gather 调度。有关详细信息,请参阅下面的“显式预取”。
model.parameters() 作为 DTensor:fully_shard 在 ranks 之间分片参数,并将 model.parameters() 从普通的 torch.Tensor 转换为 DTensor 来表示分片参数。FSDP2 默认在 dim-0 上分片,因此 DTensor 的 placement 是 Shard(dim=0)。假设我们有 N 个 ranks 和一个在分片前有 N 行的参数。分片后,每个 rank 将拥有该参数的 1 行。我们可以使用 param.to_local() 来检查分片参数。
from torch.distributed.tensor import DTensor
for param in model.parameters():
assert isinstance(param, DTensor)
assert param.placements == (Shard(0),)
# inspect sharded parameters with param.to_local()
optim = torch.optim.Adam(model.parameters(), lr=1e-2)
请注意,优化器是在应用 fully_shard 后构造的。模型和优化器状态字典都以 DTensor 的形式表示。
DTensor 促进了优化器、梯度裁剪和检查点
torch.optim.Adam和torch.nn.utils.clip_grad_norm_对 DTensor 参数开箱即用。这使得代码在单设备和分布式训练之间保持一致。我们可以使用 DTensor 和 DCP API 来操作参数以获取完整的 state dict,有关详细信息,请参阅“state dict”部分。对于分布式 state dict,我们可以保存/加载检查点(文档),而无需额外的通信。
带预取的 Forward/Backward#
命令:torchrun --nproc_per_node 2 train.py
for _ in range(epochs):
x = torch.randint(0, vocab_size, (batch_size, seq_len), device=device)
loss = model(x).sum()
loss.backward()
optim.step()
optim.zero_grad()
fully_shard 会向所有层注册前向/后向钩子,以便在计算前 all-gather 参数,并在计算后重新分片参数。为了重叠 all-gathers 和计算,FSDP2 提供了**隐式预取**,它与上述训练循环开箱即用,以及供高级用户手动控制 all-gather 调度的**显式预取**。
隐式预取:CPU 线程在层 i 之前发出 all-gather i。All-gathers 被排入其自己的 cuda 流,而层 i 的计算发生在默认流中。对于非 CPU 密集型工作负载(例如具有大批量大小的 Transformer),all-gather i+1 可以与层 i 的计算重叠。隐式预取在后向操作中类似,只是 all-gathers 的发出顺序与前向后顺序相反。
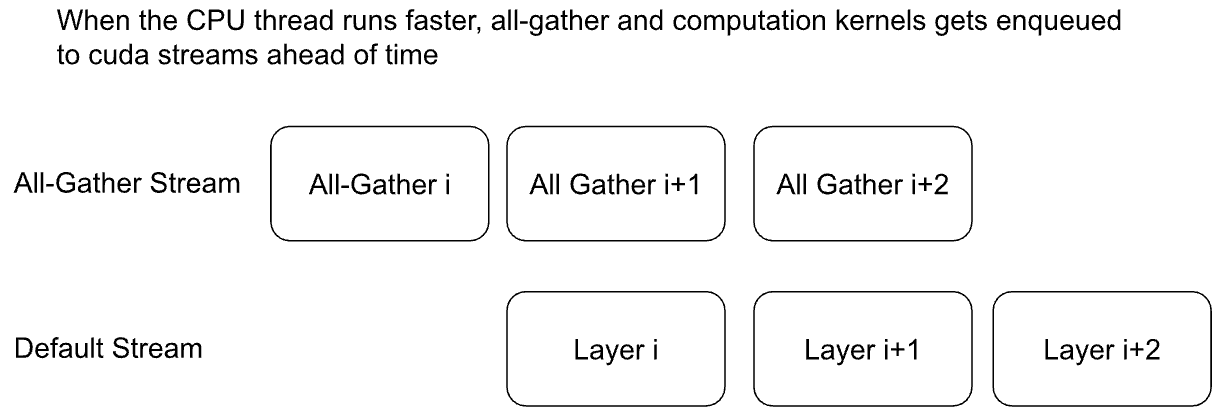
我们建议用户从隐式预取开始,以了解开箱即用的性能。
显式预取:用户可以通过 set_modules_to_forward_prefetch 指定前向顺序,并通过 set_modules_to_backward_prefetch 指定后向顺序。如下面的代码所示,CPU 线程在层 i 处发出 all-gather i + 1 和 i + 2。
显式预取在以下情况下效果很好
CPU 密集型工作负载:如果使用隐式预取,当层 i 的内核执行时,CPU 线程将太慢而无法发出层 i+1 的 all-gather。我们必须在运行层 i 的前向计算之前显式发出 all-gather i+1。
2 层及以上预取:隐式预取一次只 all-gather 下一层,以最大限度地减少内存占用。通过显式预取,可以一次 all-gather 多层,以可能获得更好的性能,同时增加内存。请参阅代码中的 layers_to_prefetch。
提前发出第一个 all-gather:隐式预取在调用 model(x) 时发生。第一个 all-gather 会被暴露。我们可以显式调用 model.unshard() 来提前发出第一个 all-gather。
命令:torchrun --nproc_per_node 2 train.py --explicit-prefetching
num_to_forward_prefetch = 2
for i, layer in enumerate(model.layers):
if i >= len(model.layers) - num_to_forward_prefetch:
break
layers_to_prefetch = [
model.layers[i + j] for j in range(1, num_to_forward_prefetch + 1)
]
layer.set_modules_to_forward_prefetch(layers_to_prefetch)
num_to_backward_prefetch = 2
for i, layer in enumerate(model.layers):
if i < num_to_backward_prefetch:
continue
layers_to_prefetch = [
model.layers[i - j] for j in range(1, num_to_backward_prefetch + 1)
]
layer.set_modules_to_backward_prefetch(layers_to_prefetch)
for _ in range(epochs):
# trigger 1st all-gather earlier
# this overlaps all-gather with any computation before model(x)
model.unshard()
x = torch.randint(0, vocab_size, (batch_size, seq_len), device=device)
loss = model(x).sum()
loss.backward()
optim.step()
optim.zero_grad()
启用混合精度#
FSDP2 提供了一个灵活的 混合精度策略 来加速训练。一个典型的用例是:
将 float32 参数转换为 bfloat16 进行前向/后向计算,请参阅
param_dtype=torch.bfloat16将梯度提升为 float32 进行 reduce-scatter 以保持精度,请参阅
reduce_dtype=torch.float32
与 torch.amp 相比,FSDP2 混合精度具有以下优点:
高效灵活的参数转换:
FSDPModule内的所有参数都在模块边界(前向/后向之前和之后)一起转换。我们可以为每个层设置不同的混合精度策略。例如,前几层可以是 float32,其余层可以是 bfloat16。float32 梯度归约(reduce-scatter):梯度可能因 rank 而异。以 float32 归约梯度对于数值计算可能至关重要。
命令:torchrun --nproc_per_node 2 train.py --mixed-precision
model = Transformer(model_args)
fsdp_kwargs = {
"mp_policy": MixedPrecisionPolicy(
param_dtype=torch.bfloat16,
reduce_dtype=torch.float32,
)
}
for layer in model.layers:
fully_shard(layer, **fsdp_kwargs)
fully_shard(model, **fsdp_kwargs)
# sharded parameters are float32
for param in model.parameters():
assert param.dtype == torch.float32
# unsharded parameters are bfloat16
model.unshard()
for param in model.parameters(recurse=False):
assert param.dtype == torch.bfloat16
model.reshard()
# optimizer states are in float32
optim = torch.optim.Adam(model.parameters(), lr=1e-2)
# training loop
# ...
梯度裁剪和带 DTensor 的优化器#
命令:torchrun --nproc_per_node 2 train.py
# optim is constructed base on DTensor model parameters
optim = torch.optim.Adam(model.parameters(), lr=1e-2)
for _ in range(epochs):
x = torch.randint(0, vocab_size, (batch_size, seq_len), device=device)
loss = model(x).sum()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=max_norm)
optim.step()
optim.zero_grad()
优化器在对模型应用 fully_shard 后进行初始化,并持有对 DTensor model.parameters() 的引用。对于梯度裁剪,torch.nn.utils.clip_grad_norm_ 可用于 DTensor 参数。Tensor 操作将在 DTensor 内部正确分派,以跨 ranks 通信部分张量,从而保持单设备语义。
带 DTensor API 的 State Dicts#
我们展示了如何将完整的 state dict 转换为 DTensor state dict 进行加载,以及如何将其转换回完整的 state dict 进行保存。
命令:torchrun --nproc_per_node 2 train.py
第一次运行时,它会为模型和优化器创建检查点
第二次运行时,它从先前的检查点加载以恢复训练
加载 state dicts:我们在 meta device 下初始化模型,然后调用 fully_shard 将 model.parameters() 从普通的 torch.Tensor 转换为 DTensor。从 torch.load 读取完整 state dict 后,我们可以调用 distribute_tensor 将普通的 torch.Tensor 转换为 DTensor,使用与 model.state_dict() 相同的 placement 和 device mesh。最后,我们可以调用 model.load_state_dict 将 DTensor state dicts 加载到模型中。
from torch.distributed.tensor import distribute_tensor
# mmap=True reduces CPU memory usage
full_sd = torch.load(
"checkpoints/model_state_dict.pt",
mmap=True,
weights_only=True,
map_location='cpu',
)
meta_sharded_sd = model.state_dict()
sharded_sd = {}
for param_name, full_tensor in full_sd.items():
sharded_meta_param = meta_sharded_sd.get(param_name)
sharded_tensor = distribute_tensor(
full_tensor,
sharded_meta_param.device_mesh,
sharded_meta_param.placements,
)
sharded_sd[param_name] = nn.Parameter(sharded_tensor)
# `assign=True` since we cannot call `copy_` on meta tensor
model.load_state_dict(sharded_sd, assign=True)
保存 state dicts:model.state_dict() 返回一个 DTensor state dict。我们可以通过调用 full_tensor() 将 DTensor 转换为普通的 torch.Tensor。内部它会发出一个跨 ranks 的 all-gather 来获取未分片的普通 torch.Tensor 参数。对于 rank 0,full_param.cpu() 会逐个将张量卸载到 CPU,以避免因未分片参数而导致 GPU 内存峰值。
sharded_sd = model.state_dict()
cpu_state_dict = {}
for param_name, sharded_param in sharded_sd.items():
full_param = sharded_param.full_tensor()
if torch.distributed.get_rank() == 0:
cpu_state_dict[param_name] = full_param.cpu()
else:
del full_param
torch.save(cpu_state_dict, "checkpoints/model_state_dict.pt")
优化器状态字典也类似工作(代码)。用户可以自定义上述 DTensor 脚本以与第三方检查点一起使用。
如果不需要自定义,我们可以直接使用 DCP API 来支持单节点和多节点训练。
带 DCP API 的 State Dict#
命令:torchrun --nproc_per_node 2 train.py --dcp-api
第一次运行时,它会为模型和优化器创建检查点
第二次运行时,它从先前的检查点加载以恢复训练
加载 state dicts:我们可以使用 set_model_state_dict 将一个完整的 state dict 加载到一个 FSDP2 模型中。使用 broadcast_from_rank0=True,我们可以在 rank 0 上仅加载完整的 state dict,以避免 CPU 内存峰值。DCP 会分片张量并将其广播到其他 ranks。
from torch.distributed.checkpoint.state_dict import set_model_state_dict
set_model_state_dict(
model=model,
model_state_dict=full_sd,
options=StateDictOptions(
full_state_dict=True,
broadcast_from_rank0=True,
),
)
保存 state dicts:get_model_state_dict 配合 full_state_dict=True 和 cpu_offload=True 会 all-gather 张量并将其卸载到 CPU。它的工作方式与 DTensor API 类似。
from torch.distributed.checkpoint.state_dict import get_model_state_dict
model_state_dict = get_model_state_dict(
model=model,
options=StateDictOptions(
full_state_dict=True,
cpu_offload=True,
)
)
torch.save(model_state_dict, "model_state_dict.pt")
有关使用 set_optimizer_state_dict 和 get_optimizer_state_dict 加载和保存优化器状态字典,请参考 pytorch/examples。
FSDP1 到 FSDP2 迁移指南#
让我们看一个 FSDP 用法和等效的 fully_shard 用法的示例。我们将重点介绍关键差异并提出迁移步骤。
原始 FSDP() 用法
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
with torch.device("meta"):
model = Transformer()
policy = ModuleWrapPolicy({TransformerBlock})
model = FSDP(model, auto_wrap_policy=policy)
def param_init_fn(module: nn.Module) -> None: ...
model = FSDP(model, auto_wrap_policy=policy, param_init_fn=param_init_fn)
新的 fully_shard() 用法
with torch.device("meta"):
model = Transformer()
for module in model.modules():
if isinstance(module, TransformerBlock):
fully_shard(module)
fully_shard(model)
for tensor in itertools.chain(model.parameters(), model.buffers()):
assert tensor.device == torch.device("meta")
# Initialize the model after sharding
model.to_empty(device="cuda")
model.reset_parameters()
迁移步骤
替换导入
直接实现你的“策略”(将
fully_shard应用于所需的子层)使用
fully_shard而不是FSDP来包装你的根模型删除
param_init_fn并手动调用model.reset_parameters()替换其他 FSDP1 kwargs(见下文)
sharding_strategy
FULL_SHARD:
reshard_after_forward=TrueSHARD_GRAD_OP:
reshard_after_forward=FalseHYBRID_SHARD:
reshard_after_forward=True配合 2D device mesh_HYBRID_SHARD_ZERO2:
reshard_after_forward=False配合 2D device mesh
cpu_offload
CPUOffload.offload_params=False:
offload_policy=NoneCPUOffload.offload_params = True:
offload_policy=CPUOffloadPolicy()
backward_prefetch
BACKWARD_PRE: 始终使用
BACKWARD_POST: 不支持
mixed_precision
buffer_dtype被省略,因为 fully_shard 不分片 buffersfully_shard 的
cast_forward_inputs映射到 FSDP1 中的cast_forward_inputs和cast_root_forward_inputsoutput_dtype是 fully_shard 的新配置
device_id: 从 device_mesh 的 device 推断
sync_module_states=True/False: 已移至 DCP。用户可以使用 set_model_state_dict 配合 broadcast_from_rank0=True 从 rank0 广播 state dicts。
forward_prefetch: 可以通过以下方式手动控制预取:
使用这些 API 控制自动预取:set_modules_to_forward_prefetch 和 set_modules_to_backward_prefetch
limit_all_gathers: 不再需要,因为 fully_shard 移除了 CPU 同步
use_orig_params: 始终使用原始参数(不再是 flat parameter)
no_sync(): set_requires_gradient_sync
ignored_params 和 ignored_states: ignored_params
