torchaudio.transforms¶
torchaudio.transforms 模块包含常见的音频处理和特征提取。下图显示了可用的部分变换之间的关系。
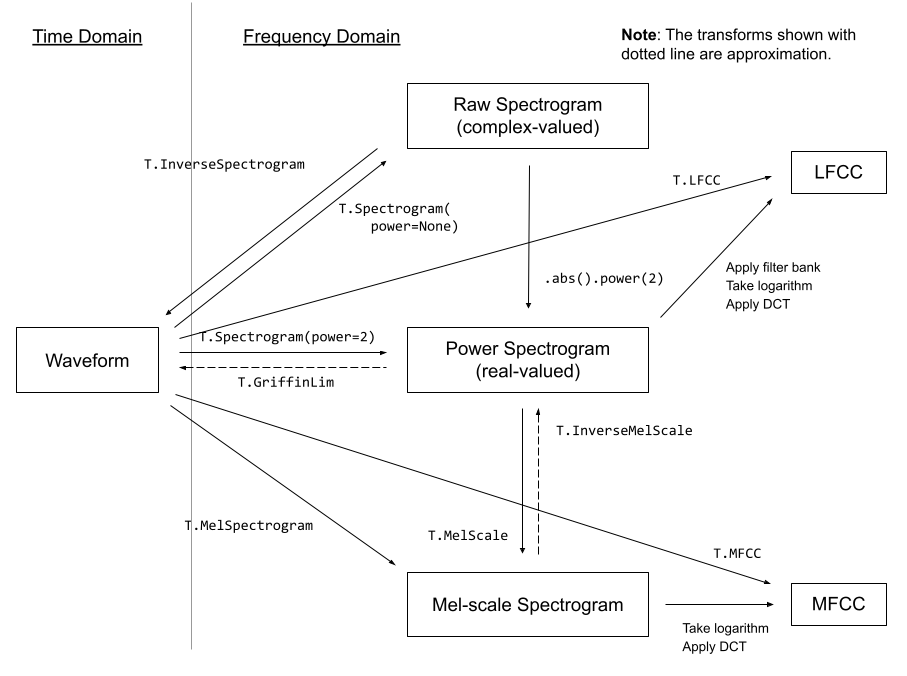
变换是使用 torch.nn.Module 实现的。构建处理管道的常用方法是定义自定义 Module 类或使用 torch.nn.Sequential 将 Modules 链接在一起,然后将其移动到目标设备和数据类型。
# Define custom feature extraction pipeline.
#
# 1. Resample audio
# 2. Convert to power spectrogram
# 3. Apply augmentations
# 4. Convert to mel-scale
#
class MyPipeline(torch.nn.Module):
def __init__(
self,
input_freq=16000,
resample_freq=8000,
n_fft=1024,
n_mel=256,
stretch_factor=0.8,
):
super().__init__()
self.resample = Resample(orig_freq=input_freq, new_freq=resample_freq)
self.spec = Spectrogram(n_fft=n_fft, power=2)
self.spec_aug = torch.nn.Sequential(
TimeStretch(stretch_factor, fixed_rate=True),
FrequencyMasking(freq_mask_param=80),
TimeMasking(time_mask_param=80),
)
self.mel_scale = MelScale(
n_mels=n_mel, sample_rate=resample_freq, n_stft=n_fft // 2 + 1)
def forward(self, waveform: torch.Tensor) -> torch.Tensor:
# Resample the input
resampled = self.resample(waveform)
# Convert to power spectrogram
spec = self.spec(resampled)
# Apply SpecAugment
spec = self.spec_aug(spec)
# Convert to mel-scale
mel = self.mel_scale(spec)
return mel
# Instantiate a pipeline
pipeline = MyPipeline()
# Move the computation graph to CUDA
pipeline.to(device=torch.device("cuda"), dtype=torch.float32)
# Perform the transform
features = pipeline(waveform)
请查看涵盖变换深度用法的教程。
实用程序¶
将张量从功率/幅度尺度转换为分贝尺度。 |
|
基于 mu-law 压扩对信号进行编码。 |
|
解码 mu-law 编码信号。 |
|
将信号从一个频率重采样到另一个频率。 |
|
为波形添加淡入和/或淡出。 |
|
调整波形的音量。 |
|
根据 ITU-R BS.1770-4 建议测量音频响度。 |
|
根据信噪比缩放波形并添加噪声。 |
|
使用直接方法沿最后一个维度卷积输入。 |
|
使用 FFT 沿最后一个维度卷积输入。 |
|
调整波形速度。 |
|
应用《语音识别音频增强》中介绍的速度扰动增强 [Ko et al., 2015]。 |
|
沿最后一个维度对波形进行去加重。 |
|
沿最后一个维度对波形进行预加重。 |
特征提取¶
从音频信号创建频谱图。 |
|
创建反向频谱图以从频谱图中恢复音频信号。 |
|
将标准的 STFT 转换为具有三角滤波器组的 Mel 频率 STFT。 |
|
从 Mel 频率域估计标准频率域中的 STFT。 |
|
为原始音频信号创建 Mel 频谱图。 |
|
使用 Griffin-Lim 变换从线性幅度频谱图计算波形。 |
|
从音频信号创建 Mel 频率倒谱系数。 |
|
从音频信号创建线性频率倒谱系数。 |
|
计算张量(通常是频谱图)的 delta 系数。 |
|
将波形的音高移动 |
|
按话语应用滑动窗口倒谱均值(和可选方差)归一化。 |
|
沿时间轴计算每个通道的谱质心。 |
|
语音活动检测器。 |
增强¶
以下变换实现了流行的增强技术,称为 SpecAugment [Park et al., 2019]。
在频率域中对频谱图应用掩码。 |
|
在时间域中对频谱图应用掩码。 |
|
以给定速率拉伸 STFT 的时间而不改变音高。 |
Loss¶
已弃用 |
多通道¶
计算跨通道功率谱密度 (PSD) 矩阵。 |
|
最小方差无失真响应 (MVDR) 模块,它使用时频掩码执行 MVDR 波束成形。 |
|
基于相对传递函数 (RTF) 和噪声的功率谱密度 (PSD) 矩阵的最小方差无失真响应(MVDR [Capon, 1969])模块。 |
|
基于 Souden et, al. 方法的最小方差无失真响应(MVDR [Capon, 1969])模块 [Souden et al., 2009]。 |
