LLM 接口¶
TorchRL 为 LLM 的训练后和微调提供了全面的框架。LLM API 基于五个核心概念构建,这些概念共同作用,为语言模型创建完整的强化学习管道。
数据表示 (数据结构):用于处理对话、文本解析和 LLM 输出类。这包括用于管理对话上下文的
History类,以及用于 token、对数概率和文本的结构化输出类。LLM 包装器 API (模块):用于不同 LLM 后端的统一接口,包括用于 Hugging Face 模型的
TransformersWrapper,用于 vLLM 推理的vLLMWrapper,以及用于高性能分布式 vLLM 推理(推荐)的AsyncVLLM。这些包装器在不同后端之间提供了一致的输入/输出格式,并为损失计算、数据存储、评分、权重同步等提供了一个集成的接口。环境 (环境):负责数据加载、工具执行、奖励计算和格式化的编排层。这包括用于对话管理的
ChatEnv、数据集环境以及用于工具集成的各种转换。目标 (目标):用于 LLM 训练的专用损失函数,包括用于组相对策略优化(Group Relative Policy Optimization)的
GRPOLoss和用于监督微调(supervised fine-tuning)的SFTLoss。收集器 (收集器):收集器用于从环境中收集数据并将其存储为可用于训练的格式。这包括用于从环境中收集数据的
LLMCollector和使用 Ray 在分布式环境中收集数据的RayLLMCollector。
这些组件协同工作,构建一个完整的管道:环境负责加载和格式化数据,LLM 包装器负责推理,数据结构负责维护对话上下文,目标负责计算训练损失。模块化设计允许您根据具体用例混合搭配组件。
在 sota-implementations/grpo/ 目录中可以找到一个使用 LLM API 的完整示例。训练编排涉及三个主要组件:
数据收集器:持有对环境和推理模型或引擎的引用。它收集数据,放入缓冲区,并处理权重更新。
回放缓冲区:存储收集到的数据并执行任何预处理或后处理步骤。这些可能包括:- 使用基于蒙特卡罗的方法进行优势估计(使用
MCAdvantage转换);- 对输出进行评分;- 日志记录等。训练器:处理训练循环,包括优化步骤、序列化、日志记录和权重更新初始化。
警告
LLM API 仍在开发中,未来可能会发生变化。欢迎提供反馈、报告问题和提交 PR!
数据结构¶
数据表示层为以结构化的方式处理对话和 LLM 输出奠定了基础。
History 类¶
与 Transformers 中通常存在的聊天格式(请参阅 Hugging Face 聊天文档)相比,History 类是 TensorClass 的版本。它提供了一个全面的 API 来管理对话数据,功能包括:
文本解析和格式化:使用
from_text()和apply_chat_template()在文本和结构化对话格式之间进行转换。动态对话构建:使用
append()和extend()方法追加和扩展对话。多模型支持:自动检测不同模型系列(Qwen、DialoGPT、Falcon、DeepSeek 等)的模板。
助手 token 屏蔽:识别为强化学习应用而由助手生成的 token。
工具调用支持:在对话中处理函数调用和工具响应。
批处理操作:用于同时处理多个对话的高效张量操作。
|
|
|
支持的模型系列¶
我们目前支持以下模型系列进行字符串到 History 的解析或助手 token 屏蔽:
Qwen 系列(例如,Qwen/Qwen2.5-0.5B):具有完整工具调用支持的自定义模板。
DialoGPT 系列(例如,microsoft/DialoGPT-medium):用于对话格式的自定义模板。
Falcon 系列(例如,tiiuae/falcon-7b-instruct):用于指令格式的自定义模板。
DeepSeek 系列(例如,deepseek-ai/deepseek-coder-6.7b-base):具有原生格式的自定义模板。
其他模型也得到支持,但您需要为它们提供自定义模板。LLAMA、Mistral、OPT、GPT、MPT、BLOOM、Pythia、Phi 等将使用默认的 chatml_format 模板。
用法¶
>>> from torchrl.data.llm.chat import History
>>> from transformers import AutoTokenizer
>>>
>>> # Create a conversation history
>>> history = History.from_chats([[
... {"role": "user", "content": "Hello"},
... {"role": "assistant", "content": "Hi there!"},
... {"role": "user", "content": "How are you?"},
... {"role": "assistant", "content": "I'm doing well, thanks!"}
... ]])
>>>
>>> # Load any supported tokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-0.5B")
>>>
>>> # Apply chat template with assistant token masking
>>> result = history.apply_chat_template(
... chat_template_name="qwen",
... add_generation_prompt=False,
... return_dict=True,
... return_assistant_tokens_mask=True,
... )
>>>
>>> # The result contains an assistant_masks tensor
>>> assistant_masks = result["assistant_masks"]
>>> print(f"Assistant tokens: {assistant_masks.sum().item()}")
添加自定义模板¶
您可以使用 torchrl.data.llm.chat.add_chat_template() 函数为新模型系列添加自定义聊天模板。
用法示例¶
添加 Llama 模板¶
>>> from torchrl.data.llm.chat import add_chat_template, History
>>> from transformers import AutoTokenizer
>>>
>>> # Define the Llama chat template
>>> llama_template = '''
... {% for message in messages %}
... {%- if message['role'] == 'user' %}
... {{ '<s>[INST] ' + message['content'] + ' [/INST]' }}
... {%- elif message['role'] == 'assistant' %}
... {% generation %}{{ message['content'] + '</s>' }}{% endgeneration %}
... {%- endif %}
... {% endfor %}
... {%- if add_generation_prompt %}
... {% generation %}{{ ' ' }}{% endgeneration %}
... {%- endif %}
... '''
>>>
>>> # Define the inverse parser for Llama format
>>> def parse_llama_text(text: str) -> History:
... import re
... pattern = r'<s>\[INST\]\s*(.*?)\s*\[/INST\]\s*(.*?)</s>'
... matches = re.findall(pattern, text, re.DOTALL)
... messages = []
... for user_content, assistant_content in matches:
... messages.append(History(role="user", content=user_content.strip()))
... messages.append(History(role="assistant", content=assistant_content.strip()))
... return lazy_stack(messages)
>>>
>>> # Add the template with auto-detection
>>> add_chat_template(
... template_name="llama",
... template=llama_template,
... inverse_parser=parse_llama_text,
... model_family_keywords=["llama", "meta-llama"]
... )
>>>
>>> # Now you can use it with auto-detection
>>> tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
>>> history = History.from_chats([[
... {"role": "user", "content": "Hello"},
... {"role": "assistant", "content": "Hi there!"}
... ]])
>>>
>>> # Auto-detection will use the llama template
>>> result = history.apply_chat_template(
... tokenizer=tokenizer,
... add_generation_prompt=False,
... return_dict=True,
... return_assistant_tokens_mask=True,
... )
测试您的自定义模板¶
在添加自定义模板时,您应该对其进行测试以确保其正常工作。以下是建议的测试:
助手 token 屏蔽测试¶
测试您的模板是否支持助手 token 屏蔽。
import pytest
from torchrl.data.llm.chat import History, add_chat_template
from transformers import AutoTokenizer
def test_my_model_assistant_masking():
"""Test that your model supports assistant token masking."""
# Add your template first
add_chat_template(
template_name="my_model",
template="your_template_here",
model_family_keywords=["my_model"]
)
tokenizer = AutoTokenizer.from_pretrained("your/model/name")
history = History.from_chats([[
{'role': 'user', 'content': 'Hello'},
{'role': 'assistant', 'content': 'Hi there!'}
]])
result = history.apply_chat_template(
tokenizer=tokenizer,
chat_template_name="my_model",
add_generation_prompt=False,
return_dict=True,
return_assistant_tokens_mask=True,
)
# Verify assistant mask is present
assert 'assistant_masks' in result
assert result['assistant_masks'].shape[0] == 1, "Should have batch dimension of 1"
assert result['assistant_masks'].shape[1] > 0, "Should have sequence length > 0"
# Verify some assistant tokens are masked
assistant_token_count = result['assistant_masks'].sum().item()
assert assistant_token_count > 0, "Should have assistant tokens masked"
print(f"✓ {assistant_token_count} assistant tokens masked")
模板等价性测试¶
测试您的自定义模板是否产生与模型默认模板相同的输出(不包括屏蔽)。
def test_my_model_template_equivalence():
"""Test that your template matches the model's default template."""
tokenizer = AutoTokenizer.from_pretrained("your/model/name")
history = History.from_chats([[
{'role': 'user', 'content': 'Hello'},
{'role': 'assistant', 'content': 'Hi there!'},
{'role': 'user', 'content': 'How are you?'},
{'role': 'assistant', 'content': 'I\'m good, thanks!'},
]])
# Get output with model's default template
try:
default_out = history.apply_chat_template(
tokenizer=tokenizer,
add_generation_prompt=False,
chat_template=tokenizer.chat_template,
tokenize=False,
)
except Exception as e:
default_out = None
print(f"[WARN] Could not get default template: {e}")
# Get output with your custom template
custom_out = history.apply_chat_template(
tokenizer=tokenizer,
add_generation_prompt=False,
chat_template_name="my_model",
tokenize=False,
)
if default_out is not None:
# Normalize whitespace for comparison
import re
def norm(s):
return re.sub(r"\s+", " ", s.strip())
assert norm(default_out) == norm(custom_out), (
f"Custom template does not match default!\n"
f"Default: {default_out}\nCustom: {custom_out}"
)
print("✓ Template equivalence verified")
else:
print("[INFO] Skipped equivalence check (no default template available)")
反向解析测试¶
如果您提供了反向解析器,请测试其是否正常工作。
def test_my_model_inverse_parsing():
"""Test that your inverse parser works correctly."""
history = History.from_chats([[
{'role': 'user', 'content': 'Hello'},
{'role': 'assistant', 'content': 'Hi there!'}
]])
# Format using your template
formatted = history.apply_chat_template(
tokenizer=tokenizer,
chat_template_name="my_model",
add_generation_prompt=False,
tokenize=False,
)
# Parse back using your inverse parser
parsed = History.from_text(formatted, chat_template_name="my_model")
# Verify the parsing worked
assert parsed.role == history.role
assert parsed.content == history.content
print("✓ Inverse parsing verified")
LLM 包装器 API¶
LLM 包装器 API 提供了不同 LLM 后端的统一接口,确保了训练和推理管道之间一致的输入/输出格式。主要的包装器是用于 Hugging Face 模型的 TransformersWrapper 和用于 vLLM 推理的 vLLMWrapper。
数据结构类
包装器使用结构化的 TensorClass 对象来表示 LLM 数据的不同方面:
:class:`~torchrl.modules.llm.policies.Text`:包含具有 prompt、response 和 full 字段的文本数据。
:class:`~torchrl.modules.llm.policies.ChatHistory`:包含具有 prompt、response 和 full 字段的
History对象。:class:`~torchrl.modules.llm.policies.Tokens`:包含具有 prompt、response 和 full 字段的 token 化数据。
:class:`~torchrl.modules.llm.policies.LogProbs`:包含具有 prompt、response 和 full 字段的对数概率。
:class:`~torchrl.modules.llm.policies.Masks`:包含注意力掩码和助手掩码。
API 流程
包装器在两种不同的模式下运行:
生成模式 (`generate=True`):- 输入:从 prompt 字段读取(例如,history.prompt、text.prompt、tokens.prompt)- 输出:写入 response 和 full 字段。
response:仅包含新生成的内容。
full:包含完整的序列(prompt + response)。
对数概率模式 (`generate=False`):- 输入:从 full 字段读取(例如,history.full、text.full、tokens.full)- 输出:将对数概率写入相应的 full 字段。
LLM-环境交互循环
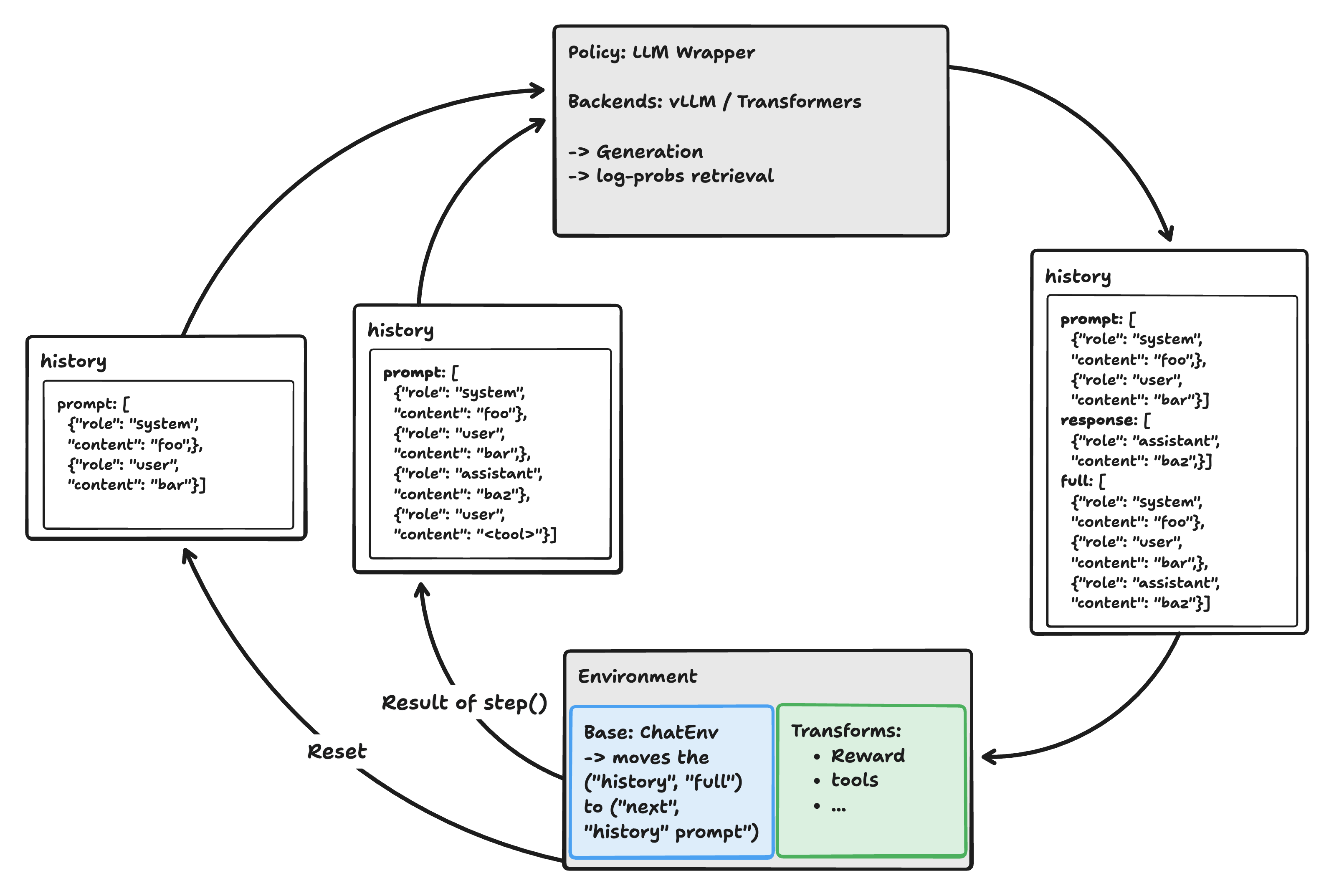
LLM-环境交互:LLM 生成响应,环境更新对话,转换可以注入新消息或工具。¶
在典型的 RL 或工具增强设置中,LLM 和环境在一个循环中交互:
LLM 生成:LLM 包装器接收 prompt(当前对话历史),生成 response,并输出一个 full 字段。
包含 prompt 和 response 的连接。
环境步进:环境将 full 字段作为下一个 prompt 提供给 LLM。这确保了对话
上下文随着每次轮次而增长。更多详细信息请参阅 ref_env_llm_step。
转换:在下一个 LLM 步进之前,转换可以修改对话,例如,通过插入新的用户消息、工具调用
或奖励注释。
重复:此过程重复进行所需的轮次数,从而实现多轮对话、工具使用和 RL 训练。
这种设计允许在每一步对对话进行灵活的增强,支持高级 RL 和工具使用场景。
典型的伪代码循环
# Get the first prompt out of an initial query
obs = env.reset(TensorDict({"query": "Hello!"}, batch_size=env.batch_size, device=env.device))
while not done:
# LLM generates a response given the current prompt
llm_output = llm(obs)
# Environment steps: creates a ("next", "history") field with the new prompt (from the previous `"full"` field)
obs = env.step(llm_output)
与 History 集成
当使用 input_mode="history" 时,包装器可以与 History 类无缝集成。
输入:接收包含 prompt 字段中 History 的
ChatHistory对象。生成:应用聊天模板将 History 转换为 token,生成响应,然后将完整的文本解析回 History 对象。
输出:返回一个 ChatHistory,其中包含:- prompt:原始对话历史- response:仅包含助手响应的新 History 对象- full:包含新响应已追加的完整对话历史。
此设计允许自然的对话流程,其中每个生成步骤都会扩展对话历史,使其成为多轮对话系统的理想选择。
Prompt 与 Response 及填充¶

LLM 输出结构:Token、LogProbs 和 Mask 的填充与稀疏表示。¶
上图说明了 TorchRL LLM API 中使用的主要输出类的结构:
Tokens(以及扩展的 LogProbs):- 填充格式:批次中的所有序列都填充到相同的长度(使用特殊的 pad token),使其适合张量操作。prompt 和 response 被连接起来形成 tokens.full,掩码指示有效位置与填充位置。- 稀疏格式:每个序列保留其原始长度(无填充),表示为张量列表。这对于可变长度数据更节省内存。
Masks:显示了两种主要掩码:- mask.attention_mask_all 标记有效(非 pad)token。- mask.assistant_mask_all 标记由助手生成的 token(对于 RLHF 和 SFT 训练有用)。
Text:未详细显示,因为它只是 prompt、response 或完整序列的解码字符串表示。
此格式确保所有 LLM 输出(Tokens、LogProbs、Masks、Text)都是一致的且易于操作,无论您使用填充批处理还是稀疏批处理。
总的来说,我们建议使用未填充的数据,因为它更节省内存且易于操作。例如,当从缓冲区收集多个填充元素时,很难清楚地理解如何重新填充它们以将它们组合成一个连贯的批次。使用未填充的数据更直接。
模块¶
LLM 包装器 API 提供了不同 LLM 后端的统一接口,确保了训练和推理管道之间一致的输入/输出格式。
包装器¶
这些原语的主要目标是:
统一训练和推理管道的输入/输出数据格式。
统一后端之间的输入/输出数据格式(以便在不同的损失和收集器中使用不同的后端)。
提供适当的工具来在典型的 RL 环境中构建这些对象(资源分配、异步执行、权重更新等)。
|
LLM 包装器基类。 |
|
Hugging Face Transformers 模型的包装器类,为文本生成和对数概率计算提供了一致的接口。 |
|
vLLM 模型的包装器类,为文本生成和对数概率计算提供了一致的接口。 |
|
一个用于 TransformersWrapper 的远程 Ray actor 包装器,提供了一个简化的接口。 |
|
一个管理多个异步 vLLM 引擎 actor 以进行分布式推理的服务。 |
|
|
|
|
|
|
|
|
|
异步 vLLM 引擎(推荐)¶
AsyncVLLM 是 TorchRL 中高性能 vLLM 推理的推荐方法。它提供了一个基于 Ray 的分布式、异步推理服务,与同步 vLLM 引擎相比,具有更高的性能和资源利用率。
主要特性
分布式架构:将多个 vLLM 引擎副本作为 Ray actor 运行,以实现水平扩展。
负载均衡:自动将请求分发到可用副本。
原生 vLLM 批处理:利用 vLLM 的优化批处理来实现最大吞吐量。您代码中的每个线程或 actor 都可以向 vLLM 引擎发出请求,将查询放入队列,然后由引擎处理批处理。
资源管理:通过 Ray 放置组(placement groups)实现自动 GPU 分配和清理。
简单的 API:通过
from_pretrained()提供一键式导入的便利。
基本用法
from torchrl.modules.llm import AsyncVLLM, vLLMWrapper
from vllm import SamplingParams
# Create async vLLM service (recommended)
async_engine = AsyncVLLM.from_pretrained(
"Qwen/Qwen2.5-7B",
num_devices=2, # Use 2 GPUs per replica (tensor parallel)
num_replicas=2, # Create 2 replicas for higher throughput
max_model_len=4096
)
# Use with vLLMWrapper for TorchRL integration
wrapper = vLLMWrapper(async_engine, input_mode="history", generate=True)
# Direct generation (also supported)
sampling_params = SamplingParams(temperature=0.7, max_tokens=100)
result = async_engine.generate("Hello, world!", sampling_params)
# Cleanup when done
async_engine.shutdown()
这些对象(AsyncVLLM 和 vLLMWrapper)可以跨多个收集器、环境或 worker 高效共享。它们可以直接从一个 worker 传递到另一个 worker:底层通过 Ray 处理句柄共享和远程执行。
性能优势
更高的吞吐量:多个副本并发处理请求。
更好的 GPU 利用率:Ray 确保最佳的 GPU 分配和共定位。
降低延迟:原生批处理可减少每个请求的开销。
容错性:Ray 提供自动错误恢复和资源管理。
资源共享
AsyncVLLM 实例可以跨多个收集器、环境或 worker 高效共享。
from torchrl.modules.llm import AsyncVLLM, vLLMWrapper
from torchrl.collectors.llm import LLMCollector
# Create a shared AsyncVLLM service
shared_async_engine = AsyncVLLM.from_pretrained(
"Qwen/Qwen2.5-7B",
num_devices=2,
num_replicas=4, # High throughput for multiple consumers
max_model_len=4096
)
# Multiple wrappers can use the same AsyncVLLM service
wrapper1 = vLLMWrapper(shared_async_engine, input_mode="history")
wrapper2 = vLLMWrapper(shared_async_engine, input_mode="text")
# Multiple collectors can share the same service
collector1 = LLMCollector(env1, policy=wrapper1)
collector2 = LLMCollector(env2, policy=wrapper2)
# The AsyncVLLM service automatically load-balances across replicas
# No additional coordination needed between consumers
这种方法比为每个消费者创建单独的 vLLM 实例更有效,因为它:
减少内存使用:跨消费者共享单个模型加载。
自动负载均衡:请求分布在不同副本之间。
更好的资源利用率:GPU 使用更高效。
简化的管理:单一服务进行监控和管理。
注意
AsyncVLLM 与传统 Actor 共享
与您手动创建命名 actor 并共享引用的传统 Ray actor 共享模式不同,AsyncVLLM 在内部处理分布式架构。您只需创建一个 AsyncVLLM 服务并将其传递给多个消费者。该服务会自动:
在内部创建和管理多个 Ray actor(副本)。
在没有手动协调的情况下,在副本之间进行请求负载均衡。
处理 actor 的生命周期和资源清理。
这消除了与先前 RemotevLLMWrapper 方法所需的手动 actor 名称管理和引用共享。
远程包装器¶
TorchRL 提供了远程包装器类,可以使用 Ray 实现 LLM 包装器的分布式执行。这些包装器提供了一个简化的接口,不需要显式的 remote() 和 get() 调用,使其易于在分布式环境中使用。
注意
对于 vLLM:请改用 AsyncVLLM
对于基于 vLLM 的推理,我们建议直接使用 AsyncVLLM 而不是远程包装器。AsyncVLLM 提供了更好的性能、资源利用率和内置负载均衡。有关详细信息,请参阅上面的 异步 vLLM 引擎(推荐) 部分。
远程包装器主要用于基于 Transformers 的模型或其他 AsyncVLLM 不适用的用例。
主要特性
简化的接口:无需显式调用 remote() 和 get()。
完整的 API 兼容性:公开了 LLMWrapperBase 基类的所有公共方法。
自动 Ray 管理:内部处理 Ray 初始化和远程执行。
属性访问:所有属性都可以通过远程包装器访问。
错误处理:从远程 actor 正确传播错误。
资源管理:支持上下文管理器以进行自动清理。
模型参数要求
RemoteTransformersWrapper:仅接受字符串模型名称/路径。Transformers 模型不可序列化。
支持的后端
目前,只有基于 Transformers 的模型通过远程包装器支持。对于 vLLM 模型,请改用 AsyncVLLM。
用法示例
import ray
from torchrl.modules.llm.policies import RemoteTransformersWrapper
from torchrl.data.llm import History
from torchrl.modules.llm.policies import ChatHistory, Text
from tensordict import TensorDict
# Initialize Ray (if not already done)
if not ray.is_initialized():
ray.init()
# Transformers wrapper (only string models supported)
# The remote wrappers implement context managers for proper resource cleanup:
with RemoteTransformersWrapper(
model="gpt2",
max_concurrency=16,
input_mode="text",
generate=True,
generate_kwargs={"max_new_tokens": 30}
) as remote_transformers:
text_input = TensorDict({"text": Text(prompt="Hello world")}, batch_size=(1,))
result = remote_transformers(text_input)
print(result["text"].response)
性能考虑
网络开销:远程执行增加了网络通信开销。
序列化:数据在发送到远程 actor 时会被序列化。
内存:每个远程 actor 都维护自己的模型副本。
并发:多个远程包装器可以并发运行。
最大并发数:使用 max_concurrency 参数控制对每个远程 actor 的并发调用次数。
清理:始终使用上下文管理器或调用 cleanup_batching() 以防止因批处理锁而挂起。
Utils¶
|
创建异步 vLLM 引擎服务。 |
为分布式通信初始化一个无状态进程组(异步版本)。 |
|
|
创建具有张量并行支持的 vLLM 推理引擎。 |
|
为分布式通信初始化一个无状态进程组。 |
收集器¶
TorchRL 提供专门的收集器类(LLMCollector 和 RayLLMCollector),这些类针对 LLM 用例进行了定制。我们还为一些推理引擎提供了专用的更新器。
有关收集器 API 的更多详细信息,请参阅 ref_collectors。简而言之,收集器的想法是将管道的推理部分隔离到一个专用类中。收集器通常以策略和环境为输入,并在两者之间交替运行。在“经典”设置中,策略类似于正在训练的策略(具有一些可选的额外探索)。在 LLM 微调的上下文中,策略通常是一个专业的推理引擎,例如 vLLM 服务器。收集器由以下参数和功能定义:
同步/异步:收集器是否应以同步或异步模式运行。在同步模式下,收集器将在优化/训练步骤之间交替运行推理步骤。在异步模式下,收集器将与优化/训练步骤并行运行推理步骤。可以向收集器传递一个回放缓冲区,这样收集器就可以直接写入它。在其他情况下,收集器可以被迭代以收集数据。
步数:收集器构建时具有一定的步数预算,以及在收集期间每次 yield 批次中要包含的步数。
权重更新器:权重更新器是更新策略权重的类。将权重更新隔离到一个专用类中,可以根据策略规范轻松实现不同的权重更新策略。
策略版本跟踪¶
LLM 收集器还允许跟踪策略的版本,这对于某些用例很有用。这通过将 PolicyVersion 转换添加到环境中来实现,然后由收集器在每次权重更新后递增。为此,可以向收集器构造函数提供转换的状态版本或一个布尔值。
>>> from torchrl.envs.llm.transforms import PolicyVersion
>>> from torchrl.collectors.llm import LLMCollector
>>> from torchrl.collectors.llm.weight_update import vLLMUpdater
>>> env = make_env() # place your code here
>>> policy = make_policy() # place your code here
>>> collector = LLMCollector(env, policy=policy, weight_updater=vLLMUpdater(), track_policy_version=True)
>>> # init the updater
>>> collector.weight_updater.init(...)
>>> # the version is incremented after each weight update
>>> collector.update_policy_weights_(state_dict=...)
>>> print(collector.policy_version_tracker.version)
>>> # the policy version is written in the data
>>> for data in collector:
... print(data["policy_version"])
|
一个将权重发送到 vLLM worker 的类。 |
|
使用 RLvLLMEngine 接口的简化 vLLM 权重更新器。 |
|
SyncDataCollector 的简化版本,用于 LLM 推理。 |
|
LLM Collector 的轻量级 Ray 实现,可以远程扩展和采样。 |
环境¶
环境层负责数据加载、工具执行、奖励计算和格式化的编排。当使用 TorchRL 微调 LLM 时,环境是推理管道的关键组成部分,与策略和收集器并列。
ChatEnv¶
ChatEnv 是 LLM 环境的空白画布——它是一个基本工具,旨在通过添加特定功能的转换来扩展。基础 ChatEnv 提供了使用 History 格式管理对话状态的基本结构,但它故意保持最小化以实现最大的灵活性。
核心功能¶
ChatEnv 在三种主要模式下运行:- History 模式:使用 History 对象进行对话管理。- Text 模式:使用简单的文本字符串进行输入/输出。- Tokens 模式:使用 token 化数据进行输入/输出。
环境通过以下方式维护对话状态:- 重置:初始化带有可选系统 prompt 的新对话。- 步进:接收 LLM 的响应并更新对话历史,准备下一个 prompt。
基于转换的架构¶
转换是扩展 ChatEnv 以实现特定功能的主要方式:
奖励计算:用于 KL 散度奖励的
KLRewardTransform。工具执行:用于 Python 代码执行的
PythonInterpreter,用于通用工具调用的MCPToolTransform。数据加载:用于从数据集中加载 prompt 的
DataLoadingPrimer。思考 prompt:用于链式思考(chain-of-thought)推理的
AddThinkingPrompt。策略跟踪:用于版本控制的
PolicyVersion。步数计数:使用
StepCounter内置步数跟踪和重置管理。
与 LLM 包装器集成¶
ChatEnv 设计为与 TransformersWrapper 和 vLLMWrapper 无缝协同工作。环境负责管理对话状态,而包装器负责实际的 LLM 推理,实现了清晰的关注点分离。
在每次调用 step 时,环境会:
接收 LLM 的输出,特别是 full 字段,其中包含到目前为止的整个对话,包括新响应(例如,history.full、text.full、tokens.full)。
将此 full 字段设置为下一个 LLM 步进的 prompt(例如,td[“next”, “history”].prompt、td[“next”, “text”].prompt、td[“next”, “tokens”].prompt)。
可以选择应用转换以在下一个 LLM 步进之前插入新的用户消息、工具调用或其他对话修改,以优化 prompt。
这种机制支持无缝的多轮交互,并支持复杂的用例,如工具使用和奖励塑形。
特定任务的环境¶
我们提供了一些特定任务的环境,例如用于 GSM8K 数据集的 GSM8KEnv,用于 IFEval 数据集的 IFEvalEnv,以及用于 MLGym 集成的 MLGymEnv。
这些环境包装了一个 ChatEnv,并在一个 TransformedEnv 类中添加了一个 DataLoadingPrimer 转换(以及一个可选的奖励解析转换)。
|
一个用于 LLM 的聊天环境,设计为一个用于对话和 RL 的空白画布。 |
|
用于从数据集中提取查询的聊天环境的基类。 |
|
GSM8K 数据集环境。 |
|
一个基于 LLMEnv 的 GSM8K 环境的构建器。 |
|
在使用 GSM8k 作为 LLMEnv 的一部分时准备 prompt 的转换。 |
|
基于 IFEval 数据集的聊天环境。 |
|
IF-Eval 任务的评分器。 |
|
|
|
用于语言模型的文本生成环境。 |
|
一个使用哈希模块来识别唯一观测值的文本生成环境。 |
|
将 MLGymEnv 包装成 TorchRL 环境。 |
|
MLGym 环境的薄包装器。 |
|
用于 GSM8KEnv 或 make_gsm8k_env 的奖励解析器。 |
变换 (Transforms)¶
转换用于在将数据传递给 LLM 之前修改数据。工具通常作为转换实现,并附加到一个基础环境,如 ChatEnv。
一个工具转换的例子是 PythonInterpreter 转换,它用于在 LLM 响应的上下文中执行 Python 代码。
>>> from torchrl.envs.llm.transforms import PythonInterpreter
>>> from torchrl.envs.llm import ChatEnv
>>> from tensordict import TensorDict, set_list_to_stack
>>> from transformers import AutoTokenizer
>>> from pprint import pprint
>>> set_list_to_stack(True).set()
>>> tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-7B-Instruct")
>>> base_env = ChatEnv(
... tokenizer=tokenizer,
... system_prompt="You are an assistant that can execute Python code. Decorate your code with ```python``` tags.",
... user_role="user",
... system_role="system",
... batch_size=[1],
... )
>>> env = base_env.append_transform(PythonInterpreter())
>>> env.set_seed(0)
>>> # Pass the reset data - the prompt - to the environment
>>> reset_data = env.reset(TensorDict(
... text="Let's write a Python function that returns the square of a number.",
... batch_size=[1])
... )
>>> # Simulate an action - i.e., a response from the LLM (as if we were an LLM)
>>> action = """Here is a block of code to be executed in python:
... ```python
... def square(x):
... return x * x
... print('testing the square function with input 2:', square(2))
... ```
... <|im_end|>
... """
>>> step_data = reset_data.set("text_response", [action])
>>> s, s_ = env.step_and_maybe_reset(reset_data)
>>> # The history is a stack of chat messages.
>>> # The python interpreter transform has executed the code in the last message.
>>> pprint(s_["history"].apply_chat_template(tokenizer=tokenizer))
['<|im_start|>system\n'
'You are an assistant that can execute Python code. Decorate your code with '
'```python``` tags.<|im_end|>\n'
'<|im_start|>user\n'
"Let's write a Python function that returns the square of a "
'number.<|im_end|>\n'
'<|im_start|>assistant\n'
'Here is a block of code to be executed in python:\n'
'```python\n'
'def square(x):\n'
' return x * x\n'
"print('testing the square function with input 2:', square(2))\n"
'```<|im_end|>\n'
'<|im_start|>user\n'
'<tool_response>\n'
'Code block 1 executed successfully:\n'
'testing the square function with input 2: 4\n'
'\n'
'</tool_response><|im_end|>\n'
'<|im_start|>assistant\n']
同样,从数据集中加载数据的环境只是 ChatEnv 的特殊实例,并增加了 DataLoadingPrimer 转换(以及一些专门的奖励解析转换)。
设计奖励转换¶
在为 LLM 环境设计奖励转换时,必须考虑几个关键因素,以确保与训练管道的正确集成。 GSM8KRewardParser 和 IfEvalScorer 的示例为奖励转换设计提供了绝佳的模板。
奖励形状要求
奖励张量必须具有与 logits 相同的维度数,这通常比环境批次大小多两个维度。
稀疏奖励:形状
(*bsz, 1, 1)- 每个序列一个奖励。密集奖励:形状
(*bsz, num_tokens, 1)- 每个 token 一个奖励。
此形状要求确保与损失计算管道兼容。例如,在 GSM8K 奖励解析器中:
# Rewards need to have shape broadcastable to [batch x tokens x 1]
tds = tds.apply(lambda t: t.unsqueeze(-1).unsqueeze(-1))
Done 状态管理
妥善管理 done 状态对于防止无限生成至关重要。常见策略包括:
完成为基础的终止:当响应完成时设置 done(例如,
History.complete=True)。基于内容的终止:检测到特定内容时设置 done(例如,
<answer>块)。基于步数的终止:使用
StepCounter来预设步数限制。
IFEvalScorer 的示例
if self.set_done_if_answer and bool(answer_blocks):
next_tensordict.set("done", torch.ones(...))
next_tensordict.set("terminated", torch.ones(...))
输入模式处理
奖励转换必须正确处理不同的输入模式:
History 模式:从
("history", "full")或("history", "response")中提取文本。Text 模式:直接使用
("text", "full")或("text", "response")中的文本。Tokens 模式:从
("tokens", "full")或("tokens", "response")解码 token。
GSM8K 奖励解析器演示了此模式。
if input_mode == "history":
responses = lazy_stack([r[..., -1] for r in responses.unbind(0)])
if hasattr(responses, "content"):
text_completion = responses.content
elif input_mode == "text":
text_completion = responses
elif input_mode == "tokens":
text_completion = self.tokenizer.decode(responses.flatten(0, 1).tolist())
规范管理
准确指定奖励和观察规范对于正确初始化环境至关重要。GSM8K 和 IFEval 都提供了很好的示例。
def transform_reward_spec(self, reward_spec: Composite) -> Composite:
shape = reward_spec.shape + (1, 1)
reward_spec.update(
Composite(
reward_answer=Unbounded(shape),
reward_think=Unbounded(shape),
reward_right=Unbounded(shape),
reward_contained=Unbounded(shape),
reward=Unbounded(shape),
success=Unbounded(shape, dtype=torch.bool),
)
)
return reward_spec
批处理注意事项
为了高效处理,请妥善处理批处理数据:
展平批次维度:使用
tensordict.view(-1)进行处理。重塑结果:处理后恢复原始批次结构。
处理可变长度序列:使用适当的填充和屏蔽。
奖励聚合策略
考虑不同的奖励聚合方法:
简单聚合:对多个奖励组件求和或取平均。
加权聚合:对不同组件应用不同权重。
条件奖励:基于特定条件或阈值设置奖励。
IFEvalScorer 演示了复杂的聚合策略。
def default_reward_aggregator(self, score: IFEvalScoreData, ...):
# Format score (max 1.0)
format_score = (format_components * weights).sum(dim=-1, keepdim=True)
# Structure score (max 1.0)
structure_score = think_score + answer_score
# Completion bonus (max 0.2)
completion_bonus = float(complete) * 0.2
return format_score + structure_score + completion_bonus
回放缓冲区中的后处理
奖励也可以通过将转换附加到回放缓冲区来事后计算。但是,done 状态捕获必须保留在环境转换中,因为它需要在数据收集期间即时发生。
错误处理和鲁棒性
实现鲁棒的错误处理以应对解析失败。
try:
cot, potential_answer = self.extract_tags(compl)
except ET.ParseError:
cot, potential_answer = ("", "")
性能考虑
避免冗余计算:在可能的情况下缓存解析结果。
使用高效的文本处理:根据需要利用正则表达式或 XML 解析。
最小化内存分配:重用张量并避免不必要的复制。
通过遵循这些设计原则,可以将奖励转换有效地集成到 LLM 训练管道中,同时保持性能和可靠性。
|
一个添加思考 prompt 以鼓励 LLM 重新考虑其响应的转换。 |
|
一个启用网页浏览功能的转换。 |
|
一个从数据加载器加载数据并使用 |
|
一个用于计算两个对数概率张量之间的 KL 散度,并可选地将其添加到奖励中的转换。 |
|
用于计算基于 KL 散度的奖励的旧转换。 |
|
一个在 LLM 操作响应中执行 MCP 风格工具的转换。 |
|
一个跟踪策略版本的转换。 |
|
一个在 LLM 响应中执行 Python 代码的转换。 |
|
一个 |
|
一个用于检索两个模型对数概率之间 KL 散度的转换。 |
|
一个用于从模型检索对数概率以进行 KL 散度计算的转换。 |
|
一个在正向传播期间映射应用聊天模板到输入字符串,并在反向传播期间将字符串解析回模板的转换。 |
|
对指定输入应用分词操作。 |
|
将 tensordict 列表堆叠成具有嵌套张量的单个 tensordict。 |
|
将 tensordict 列表堆叠成具有填充张量的单个 tensordict。 |
目标¶
LLM 的训练后需要专门的损失函数,这些函数经过调整以适应语言模型的独特特性。
GRPO¶
GRPOLoss 类是 PPOLoss 类的薄包装器,它封装了 LLM 特有的功能。
|
GRPO 损失。 |
|
|
|
蒙特卡罗优势计算引擎。 |
SFT¶
|
监督微调损失。 |
|
|
一个回放缓冲区转换,用于为每个 prompt 选择 top-k 奖励。 |
