


注意
跳至末尾 下载完整的示例代码。
autograd 保存张量的钩子#
创建时间: 2021年11月03日 | 最后更新: 2024年08月27日 | 最后验证: 未验证
PyTorch 通常使用反向传播来计算梯度。然而,某些操作需要保存中间结果才能执行反向传播。本教程将介绍这些张量如何被保存/检索,以及如何定义钩子来控制打包/解包过程。
本教程假定您熟悉反向传播的理论。如果不熟悉,请先阅读这里。
保存的张量#
训练模型通常比推理模型消耗更多内存。广义上说,这是因为“PyTorch 需要保存计算图,以便调用 backward”,因此会增加内存使用量。本教程的目标之一就是精细化这个理解。
事实上,计算图本身有时并不占用大量内存,因为它从不复制任何张量。然而,计算图可以持有原本可能已超出作用域的张量的引用:这些被称为 **保存的张量**。
为什么训练模型(通常)比评估模型需要更多内存?#
我们从一个简单的例子开始:\(y = a \cdot b\),我们知道 \(y\) 相对于 \(a\) 和 \(b\) 的梯度
import torch
a = torch.randn(5, requires_grad=True)
b = torch.ones(5, requires_grad=True)
y = a * b
使用 torchviz,我们可以可视化计算图

在这个例子中,PyTorch 保存中间值 \(a\) 和 \(b\) 以便在反向传播期间计算梯度。

这些中间值(上图中的橙色部分)可以通过查找 y 的 grad_fn 的属性来访问(用于调试目的),这些属性以 _saved 前缀开头。
tensor([ 0.2396, -1.6239, 0.9282, 0.0359, 0.2160], requires_grad=True)
tensor([1., 1., 1., 1., 1.], requires_grad=True)
随着计算图的深度增加,它将存储更多保存的张量。同时,如果不是因为计算图,这些张量本来可能已经超出作用域了。
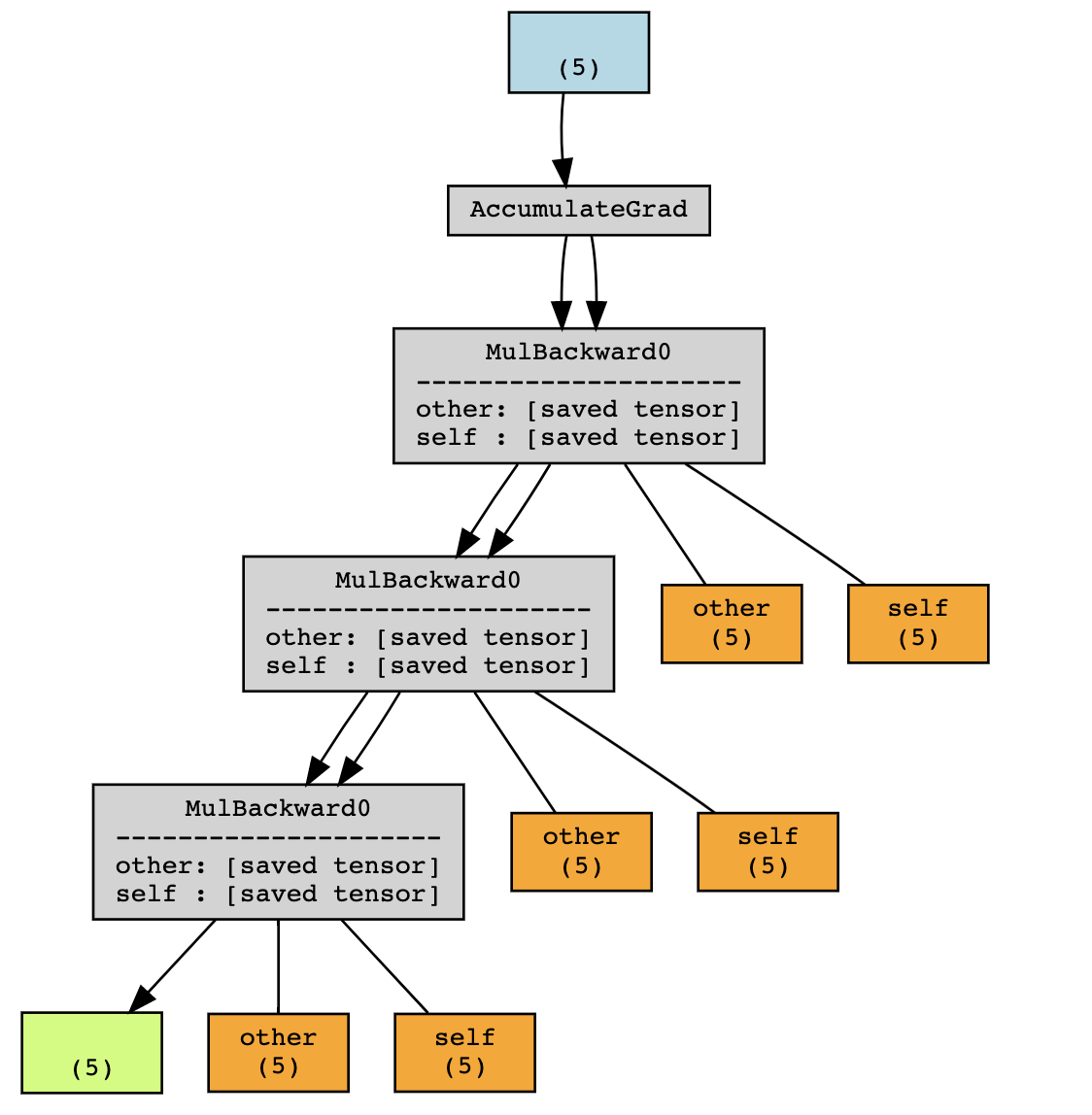
在上面的例子中,不使用 grad 执行只会将 x 和 y 保存在作用域中,但计算图额外存储了 f(x) 和 f(f(x))。因此,在训练期间运行前向传播比在评估期间(更准确地说,当不需要 autograd 时)的内存使用成本更高。
打包/解包的概念#
回到第一个例子:y.grad_fn._saved_self 和 y.grad_fn._saved_other 分别指向原始张量 a 和 b。
True
True
但是,情况并非总是如此。
True
False
在底层,PyTorch 已经**打包**并**解包**了张量 y 以防止引用循环。
经验法则:您不应依赖于访问为反向传播保存的张量会产生与原始张量相同的张量对象的这一事实。但是,它们将共享相同的存储。
保存的张量钩子#
PyTorch 提供了一个 API 来控制保存的张量应如何打包/解包。
def pack_hook(x):
print("Packing", x)
return x
def unpack_hook(x):
print("Unpacking", x)
return x
a = torch.ones(5, requires_grad=True)
b = torch.ones(5, requires_grad=True) * 2
with torch.autograd.graph.saved_tensors_hooks(pack_hook, unpack_hook):
y = a * b
y.sum().backward()
Packing tensor([2., 2., 2., 2., 2.], grad_fn=<MulBackward0>)
Packing tensor([1., 1., 1., 1., 1.], requires_grad=True)
Unpacking tensor([2., 2., 2., 2., 2.], grad_fn=<MulBackward0>)
Unpacking tensor([1., 1., 1., 1., 1.], requires_grad=True)
pack_hook 函数将在每次操作保存用于反向传播的张量时被调用。pack_hook 的输出随后被存储在计算图中,而不是原始张量。unpack_hook 使用该返回值来计算一个新张量,该张量是在反向传播过程中实际使用的张量。总的来说,您希望 unpack_hook(pack_hook(t)) 等于 t。
需要注意的是,pack_hook 的输出可以是任何 Python 对象,只要 unpack_hook 可以从中派生出一个具有正确值的张量即可。
一些非传统示例#
首先,一些愚蠢的例子来说明可能但您可能永远不想做的事情。
返回一个 int#
返回 Python 列表的索引 相对无害但实用性可疑
返回一个元组#
返回一个张量和一个如何解包它的函数 这种形式不太可能有用
def pack(x):
delta = torch.randn(*x.size())
return x - delta, lambda x: x + delta
def unpack(packed):
x, f = packed
return f(x)
x = torch.randn(5, requires_grad=True)
with torch.autograd.graph.saved_tensors_hooks(pack, unpack):
y = x * x
y.sum().backward()
assert(torch.allclose(x.grad, 2 * x))
返回一个 str#
返回张量的 __repr__ 字符串 Probably never do this
虽然这些例子在实践中可能没有用,但它们说明了 pack_hook 的输出可以是任何 Python 对象,只要它包含足够的信息来检索原始张量的内容。在接下来的部分,我们将重点介绍更有用的应用。
将张量保存到 CPU#
计算图涉及的张量经常驻留在 GPU 上。在计算图中保留这些张量的引用是导致许多模型在训练期间耗尽 GPU 内存而评估时却表现良好的原因。
钩子提供了一种非常简单的方法来实现这一点。
def pack_hook(x):
return (x.device, x.cpu())
def unpack_hook(packed):
device, tensor = packed
return tensor.to(device)
x = torch.randn(5, requires_grad=True)
with torch.autograd.graph.saved_tensors_hooks(pack, unpack):
y = x * x
y.sum().backward()
torch.allclose(x.grad, (2 * x))
True
事实上,PyTorch 提供了一个 API 来方便地使用这些钩子(以及使用固定内存的能力)。
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super().__init__()
self.w = nn.Parameter(torch.randn(5))
def forward(self, x):
with torch.autograd.graph.save_on_cpu(pin_memory=True):
# some computation
return self.w * x
x = torch.randn(5)
model = Model()
loss = model(x).sum()
loss.backward()
在实践中,在一台 A100 GPU 上,对于一个 batch size 为 256 的 ResNet-152 模型,这相当于 GPU 内存使用量从 48GB 减少到 5GB,代价是速度减慢 6 倍。
当然,您可以通过仅将网络的某些部分保存到 CPU 来调整权衡。
例如,您可以定义一个特殊的 nn.Module,它包装任何模块并将张量保存到 CPU。
class SaveToCpu(nn.Module):
def __init__(self, module):
super().__init__()
self.module = module
def forward(self, *args, **kwargs):
with torch.autograd.graph.save_on_cpu(pin_memory=True):
return self.module(*args, **kwargs)
model = nn.Sequential(
nn.Linear(10, 100),
SaveToCpu(nn.Linear(100, 100)),
nn.Linear(100, 10),
)
x = torch.randn(10)
loss = model(x).sum()
loss.backward()
将张量保存到磁盘#
类似地,您可能希望将这些张量保存到磁盘。同样,这可以通过这些钩子来实现。
一个朴素的版本如下所示。
# Naive version - HINT: Don't do this
import uuid
tmp_dir = "temp"
def pack_hook(tensor):
name = os.path.join(tmp_dir, str(uuid.uuid4()))
torch.save(tensor, name)
return name
def unpack_hook(name):
return torch.load(name, weights_only=True)
上述代码很糟糕的原因是我们会在磁盘上泄漏文件,并且它们永远不会被清理。修复这个问题并不像看起来那么简单。
# Incorrect version - HINT: Don't do this
import uuid
import os
import tempfile
tmp_dir_obj = tempfile.TemporaryDirectory()
tmp_dir = tmp_dir_obj.name
def pack_hook(tensor):
name = os.path.join(tmp_dir, str(uuid.uuid4()))
torch.save(tensor, name)
return name
def unpack_hook(name):
tensor = torch.load(name, weights_only=True)
os.remove(name)
return tensor
上述代码不起作用的原因是 unpack_hook 可能被调用多次。如果我们在第一次解包时删除了文件,那么当第二次访问保存的张量时,文件将不可用,这将引发错误。
x = torch.ones(5, requires_grad=True)
with torch.autograd.graph.saved_tensors_hooks(pack_hook, unpack_hook):
y = x.pow(2)
print(y.grad_fn._saved_self)
try:
print(y.grad_fn._saved_self)
print("Double access succeeded!")
except:
print("Double access failed!")
tensor([1., 1., 1., 1., 1.], requires_grad=True)
Double access failed!
为了解决这个问题,我们可以编写一个版本的钩子,该钩子利用 PyTorch 在不再需要保存的数据时自动释放(删除)它的事实。
class SelfDeletingTempFile():
def __init__(self):
self.name = os.path.join(tmp_dir, str(uuid.uuid4()))
def __del__(self):
os.remove(self.name)
def pack_hook(tensor):
temp_file = SelfDeletingTempFile()
torch.save(tensor, temp_file.name)
return temp_file
def unpack_hook(temp_file):
return torch.load(temp_file.name, weights_only=True)
当我们调用 backward 时,pack_hook 的输出将被删除,这会导致文件被移除,因此我们不再泄漏文件。
然后可以在您的模型中使用它,如下所示
# Only save on disk tensors that have size >= 1000
SAVE_ON_DISK_THRESHOLD = 1000
def pack_hook(x):
if x.numel() < SAVE_ON_DISK_THRESHOLD:
return x
temp_file = SelfDeletingTempFile()
torch.save(tensor, temp_file.name)
return temp_file
def unpack_hook(tensor_or_sctf):
if isinstance(tensor_or_sctf, torch.Tensor):
return tensor_or_sctf
return torch.load(tensor_or_sctf.name)
class SaveToDisk(nn.Module):
def __init__(self, module):
super().__init__()
self.module = module
def forward(self, *args, **kwargs):
with torch.autograd.graph.saved_tensors_hooks(pack_hook, unpack_hook):
return self.module(*args, **kwargs)
net = nn.DataParallel(SaveToDisk(Model()))
在最后一个示例中,我们还演示了如何过滤应该保存哪些张量(在此处,元素数量大于 1000 的张量)以及如何将此功能与 nn.DataParallel 结合使用。
如果您能看到这里,恭喜您!您现在知道如何使用保存的张量钩子以及它们在某些场景下如何有助于权衡内存与计算。
脚本总运行时间: (0 分钟 0.289 秒)
