


注意
跳转到末尾 下载完整示例代码。
PyTorch Profiler With TensorBoard#
创建日期:2021年4月20日 | 最后更新:2024年10月31日 | 最后验证:2024年11月05日
本教程演示如何使用 TensorBoard 插件与 PyTorch Profiler 结合,检测模型的性能瓶颈。
警告
PyTorch profiler 与 TensorBoard 的集成现已弃用。请改用 Perfetto 或 Chrome trace 来查看 trace.json 文件。在 生成 trace 后,只需将 trace.json 文件拖入 Perfetto UI 或 chrome://tracing 即可可视化您的 profile。
简介#
PyTorch 1.8 包含了一个更新的 profiler API,能够记录 CPU 端的操作以及 GPU 端的 CUDA kernel 启动。Profiler 可以在 TensorBoard 插件中可视化这些信息,并提供性能瓶颈的分析。
在本教程中,我们将使用一个简单的 Resnet 模型来演示如何使用 TensorBoard 插件分析模型性能。
设置#
使用以下命令安装 torch 和 torchvision
pip install torch torchvision
步骤#
准备数据和模型
使用 profiler 记录执行事件
运行 profiler
使用 TensorBoard 查看结果并分析模型性能
在 profiler 的帮助下提升性能
使用其他高级功能分析性能
额外实践:在 AMD GPU 上进行 PyTorch profiling
1. 准备数据和模型#
首先,导入所有必需的库
import torch
import torch.nn
import torch.optim
import torch.profiler
import torch.utils.data
import torchvision.datasets
import torchvision.models
import torchvision.transforms as T
然后准备输入数据。本教程使用 CIFAR10 数据集。将其转换为所需格式,并使用 DataLoader 加载每个批次。
transform = T.Compose(
[T.Resize(224),
T.ToTensor(),
T.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_set = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=32, shuffle=True)
接下来,创建 Resnet 模型、损失函数和优化器对象。要在 GPU 上运行,请将模型和损失移至 GPU 设备。
device = torch.device("cuda:0")
model = torchvision.models.resnet18(weights='IMAGENET1K_V1').cuda(device)
criterion = torch.nn.CrossEntropyLoss().cuda(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
model.train()
定义每个输入数据批次的训练步骤。
def train(data):
inputs, labels = data[0].to(device=device), data[1].to(device=device)
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
2. 使用 profiler 记录执行事件#
Profiler 通过上下文管理器启用,并接受几个参数,其中一些最有用的参数是
schedule- 一个可调用对象,它以步骤(整数)作为单个参数,并在每个步骤返回要执行的 profiler 操作。在此示例中,使用
wait=1, warmup=1, active=3, repeat=1,profiler 将跳过第一个步骤/迭代,在第二个步骤开始预热,记录接下来的三个迭代,之后 trace 将可用,并调用 on_trace_ready(如果已设置)。总共,该循环重复一次。每次循环在 TensorBoard 插件中称为一个“span”。在
wait步骤期间,profiler 被禁用。在warmup步骤期间,profiler 开始跟踪,但结果将被丢弃。这是为了减少 profiling 开销。Profiling 开始时的开销很高,容易导致 profiling 结果失真。在active步骤期间,profiler 工作并记录事件。on_trace_ready- 每个周期结束时调用的可调用对象;在此示例中,我们使用torch.profiler.tensorboard_trace_handler为 TensorBoard 生成结果文件。Profiling 结束后,结果文件将保存在./log/resnet18目录中。将此目录指定为logdir参数,可以在 TensorBoard 中分析 profile。record_shapes- 是否记录算子输入的形状。profile_memory- 跟踪张量内存的分配/释放。注意,对于低于 1.10 版本的旧版 PyTorch,如果您遇到长时间的 profiling 时间,请禁用此选项或升级到新版本。with_stack- 记录算子的源信息(文件名和行号)。如果在 VS Code 中启动 TensorBoard(参考),单击堆栈帧将导航到特定代码行。
with torch.profiler.profile(
schedule=torch.profiler.schedule(wait=1, warmup=1, active=3, repeat=1),
on_trace_ready=torch.profiler.tensorboard_trace_handler('./log/resnet18'),
record_shapes=True,
profile_memory=True,
with_stack=True
) as prof:
for step, batch_data in enumerate(train_loader):
prof.step() # Need to call this at each step to notify profiler of steps' boundary.
if step >= 1 + 1 + 3:
break
train(batch_data)
或者,也支持以下非上下文管理器 start/stop 方法。
prof = torch.profiler.profile(
schedule=torch.profiler.schedule(wait=1, warmup=1, active=3, repeat=1),
on_trace_ready=torch.profiler.tensorboard_trace_handler('./log/resnet18'),
record_shapes=True,
with_stack=True)
prof.start()
for step, batch_data in enumerate(train_loader):
prof.step()
if step >= 1 + 1 + 3:
break
train(batch_data)
prof.stop()
3. 运行 profiler#
运行上述代码。Profiling 结果将保存在 ./log/resnet18 目录下。
4. 使用 TensorBoard 查看结果并分析模型性能#
注意
TensorBoard 插件支持已弃用,因此其中一些功能可能无法按预期工作。请查看替代方案 HTA。
安装 PyTorch Profiler TensorBoard 插件。
pip install torch_tb_profiler
启动 TensorBoard。
tensorboard --logdir=./log
在 Google Chrome 浏览器或 Microsoft Edge 浏览器中打开 TensorBoard profile URL(Safari 不支持)。
http://localhost:6006/#pytorch_profiler
您将看到如下所示的 Profiler 插件页面。
概述
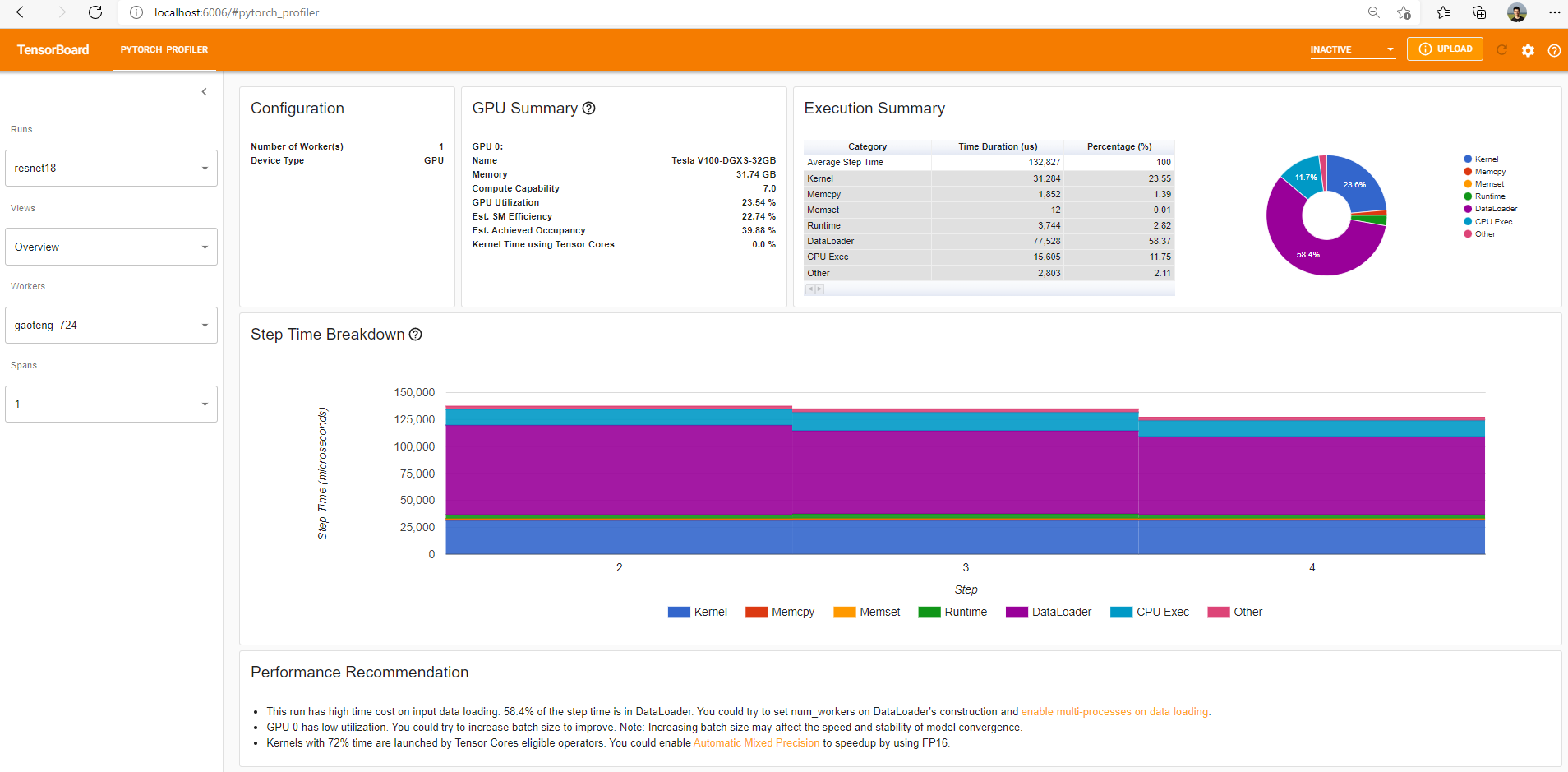
概览显示了模型性能的高层摘要。
“GPU Summary”面板显示了 GPU 配置、GPU 使用率和 Tensor Cores 使用率。在此示例中,GPU 利用率较低。这些指标的详细信息 在此处。
“Step Time Breakdown”(步骤时间细分)显示了每个步骤花费的时间在不同执行类别上的分布。在此示例中,您可以看到 DataLoader 开销相当显著。
底部的“Performance Recommendation”(性能建议)利用 profiling 数据自动突出显示可能的瓶颈,并为您提供可行的优化建议。
您可以在左侧的“Views”(视图)下拉列表中更改视图页面。
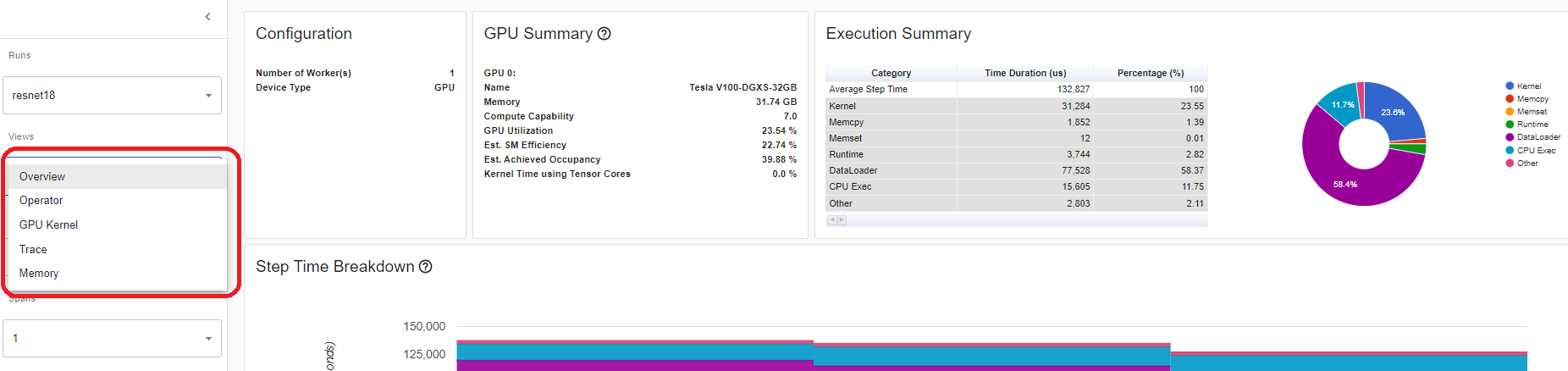
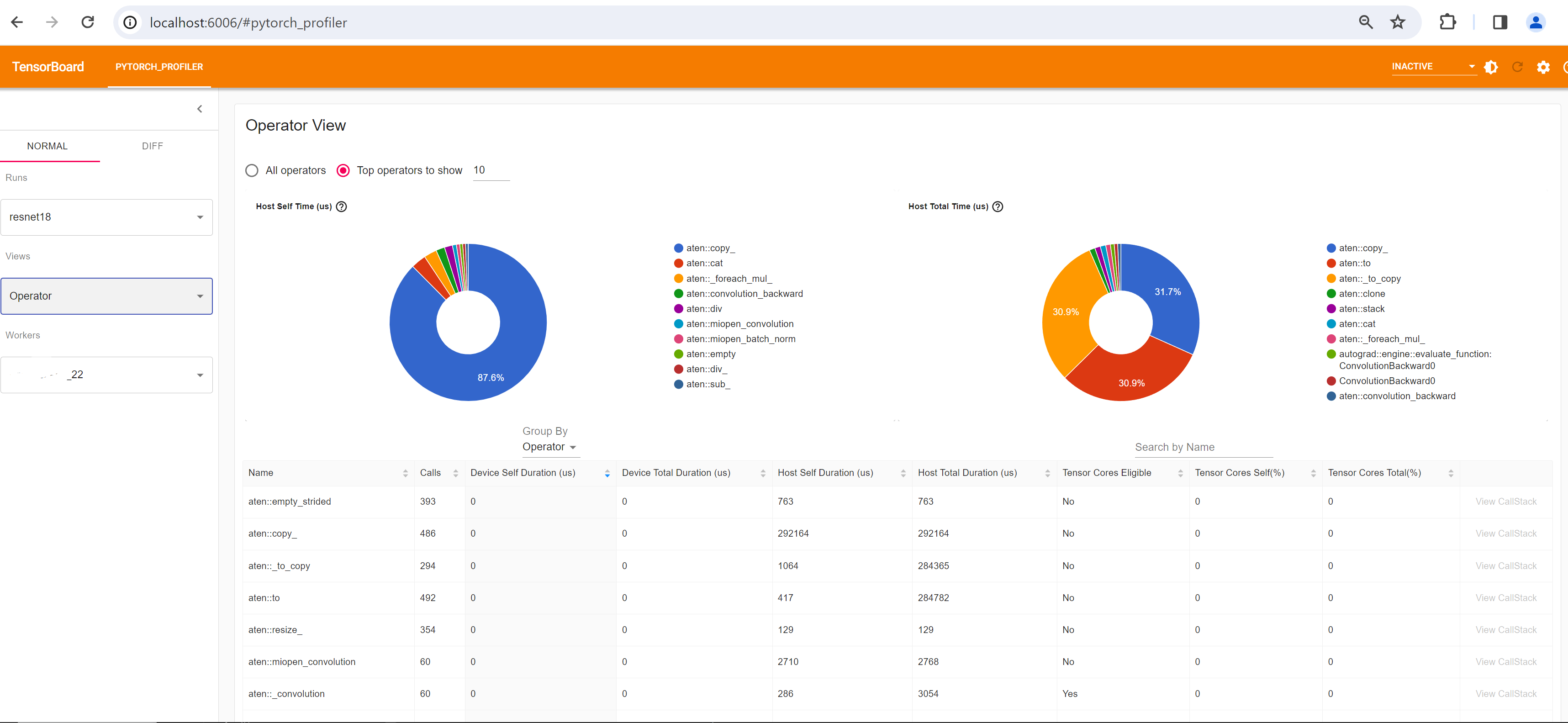
Operator view(算子视图)
算子视图显示在主机或设备上执行的每个 PyTorch 算子的性能。
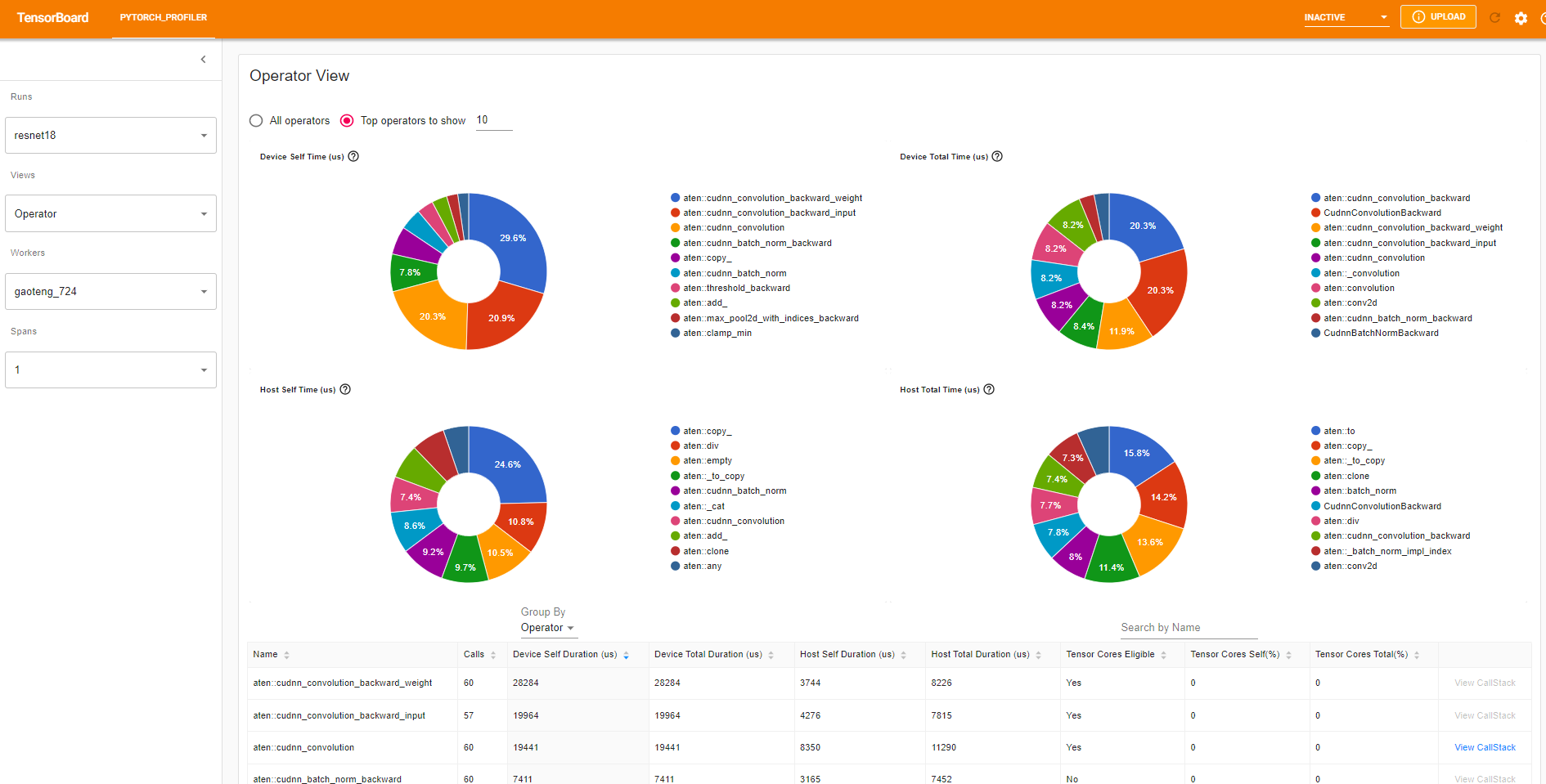
“Self” duration(自身持续时间)不包括其子算子所花费的时间。“Total” duration(总持续时间)包括其子算子所花费的时间。
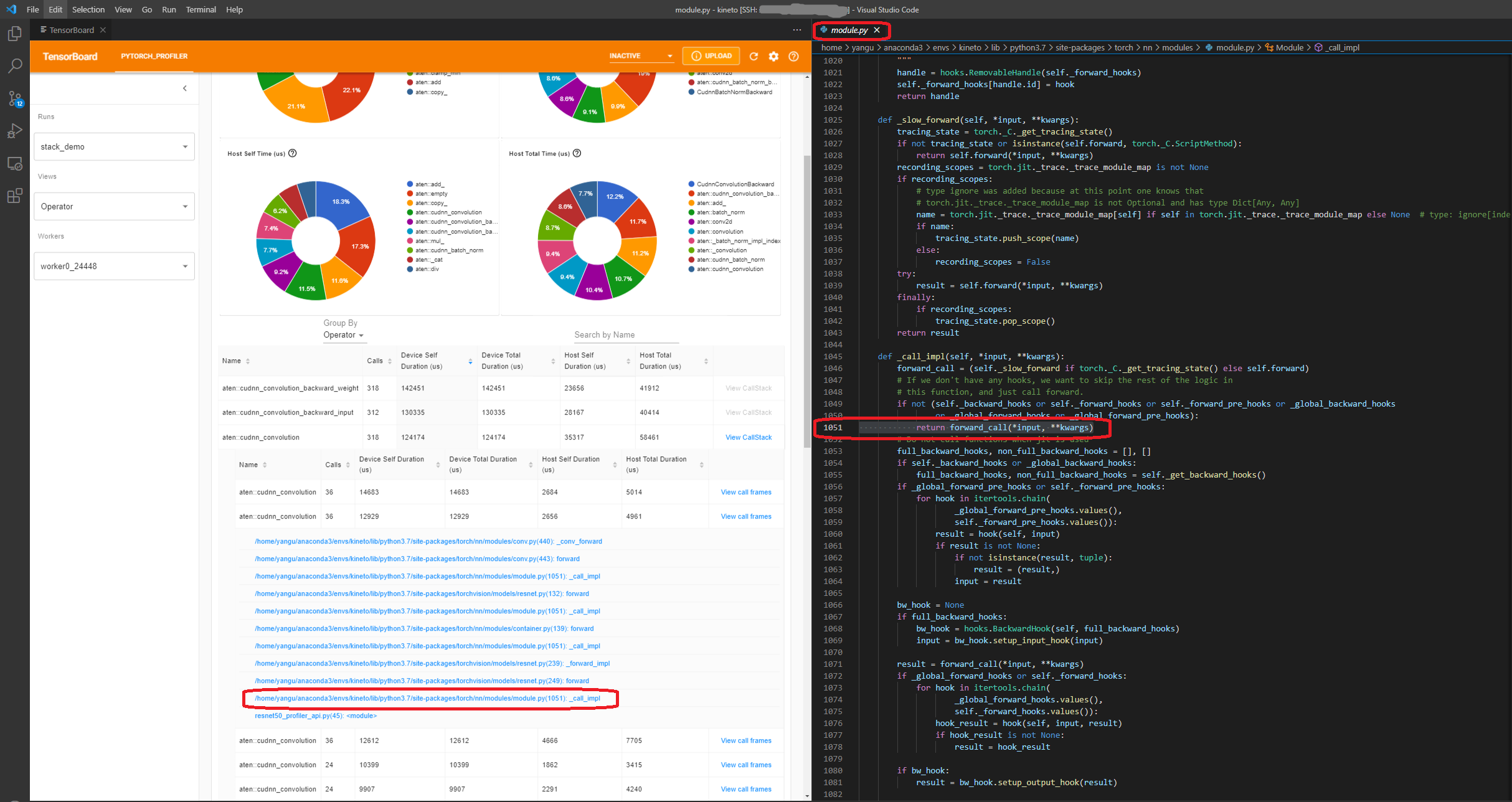
View call stack(查看调用堆栈)
点击算子的 View Callstack,将显示名称相同但调用堆栈不同的算子。然后点击此子表中的 View Callstack,将显示调用堆栈帧。
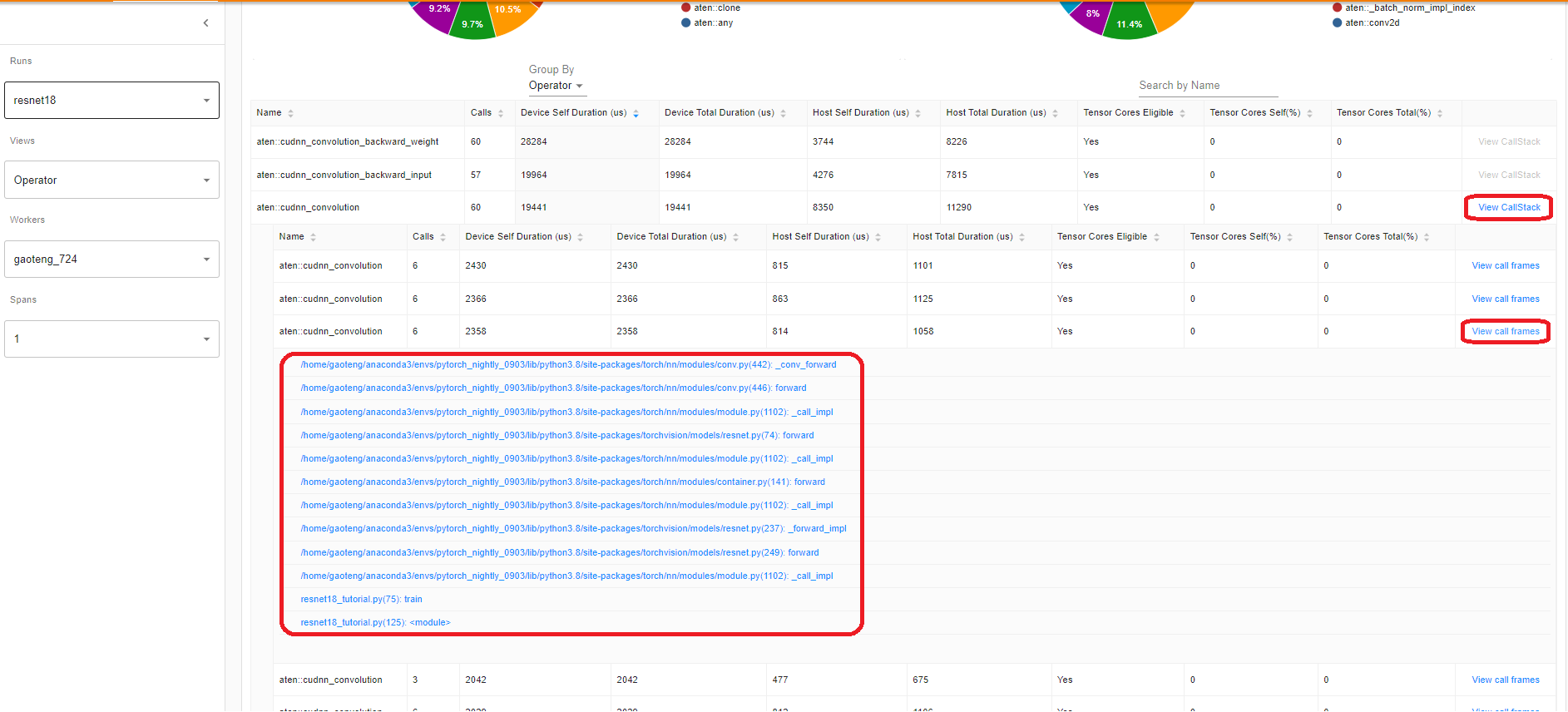
如果在 VS Code 中启动 TensorBoard(启动指南),单击调用堆栈帧将导航到特定的代码行。
Kernel view(Kernel 视图)
GPU kernel 视图显示所有 kernel 在 GPU 上花费的时间。
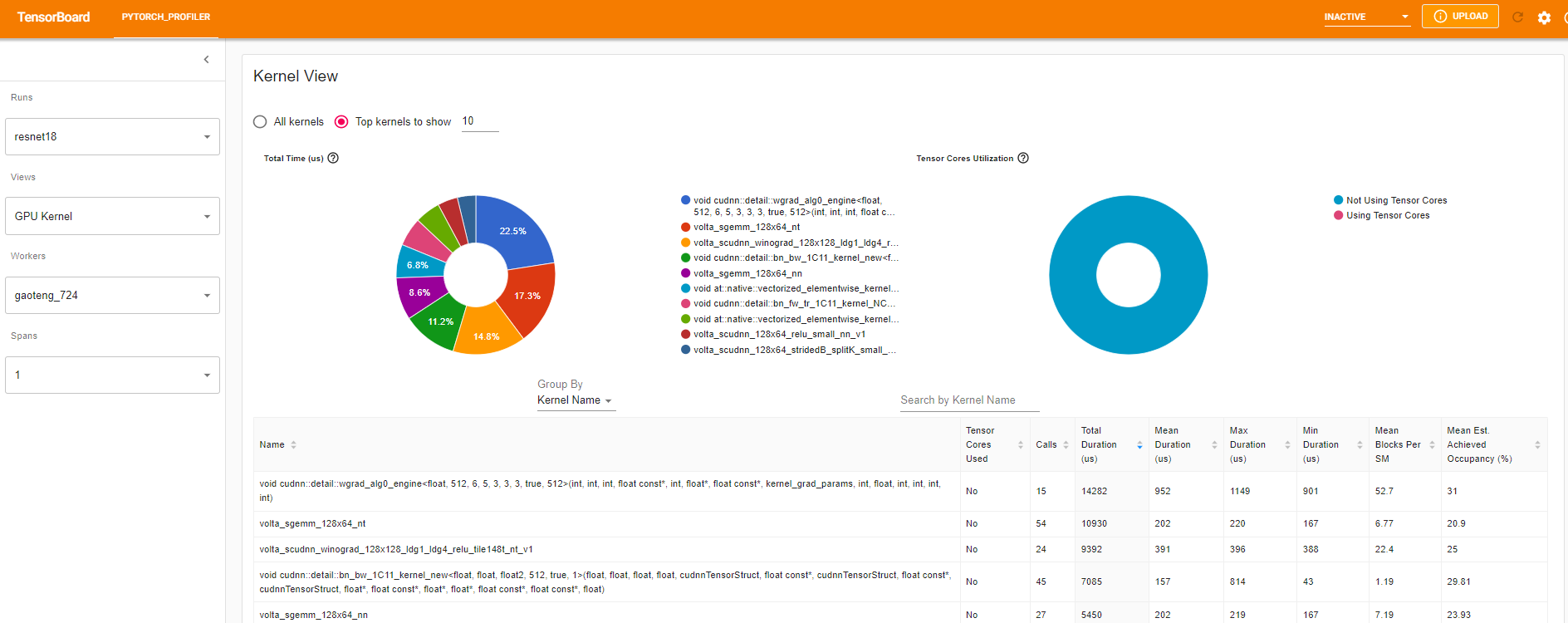
Tensor Cores Used(使用的 Tensor Cores):该 kernel 是否使用 Tensor Cores。
Mean Blocks per SM(每 SM 的平均 Blocks):Blocks per SM = 该 kernel 的 Blocks / 该 GPU 的 SM 数量。如果此数字小于 1,则表示 GPU 的多处理器未得到充分利用。“Mean Blocks per SM”是该 kernel 名称所有运行的加权平均值,以每次运行的持续时间作为权重。
Mean Est. Achieved Occupancy(平均估计的达到占用率):Est. Achieved Occupancy 在此列的工具提示中定义。对于大多数情况,如内存带宽受限的 kernel,越高越好。“Mean Est. Achieved Occupancy”是该 kernel 名称所有运行的加权平均值,以每次运行的持续时间作为权重。
Trace view(Trace 视图)
Trace 视图显示了被 profiling 的算子和 GPU kernel 的时间线。您可以选择它来查看如下详细信息。
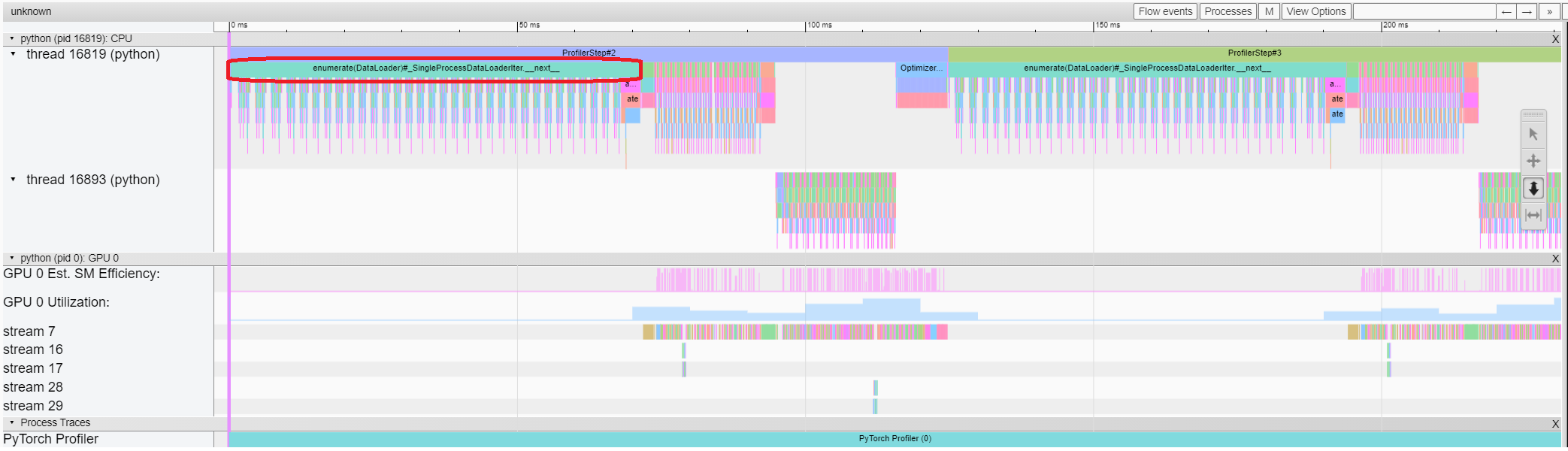
您可以使用右侧工具栏来移动和缩放图形。您还可以使用键盘在时间线内进行缩放和平移。'w' 和 's' 键以鼠标为中心缩放,'a' 和 'd' 键将时间线向左或向右移动。您可以多次按下这些键,直到看到可读的表示。
如果 backward 算子的“Incoming Flow”(传入流)字段值为“forward correspond to backward”(前向对应后向),则可以单击该文本以获取其启动的前向算子。
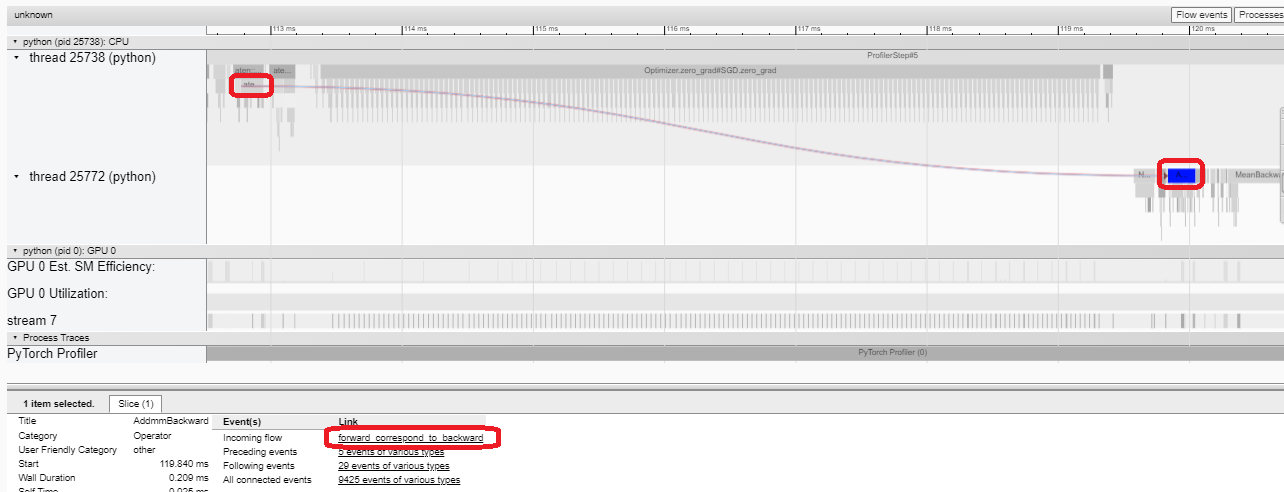
在本例中,我们可以看到带有 enumerate(DataLoader) 前缀的事件花费了大量时间。在这段时间的大部分时间里,GPU 是空闲的。因为此函数在主机端加载数据和转换数据,在此期间 GPU 资源被浪费了。
5. 在 profiler 的帮助下提升性能#
在“Overview”(概览)页面的底部,“Performance Recommendation”(性能建议)中的建议提示瓶颈是 DataLoader。PyTorch 的 DataLoader 默认使用单进程。用户可以通过设置 num_workers 参数启用多进程数据加载。更多细节在此。
在本例中,我们遵循“Performance Recommendation”(性能建议),将 num_workers 设置为如下所示,将 ./log/resnet18_4workers 这样的不同名称传递给 tensorboard_trace_handler,然后再次运行。
train_loader = torch.utils.data.DataLoader(train_set, batch_size=32, shuffle=True, num_workers=4)
然后,我们在左侧的“Runs”(运行)下拉列表中选择最近 profiling 的运行。
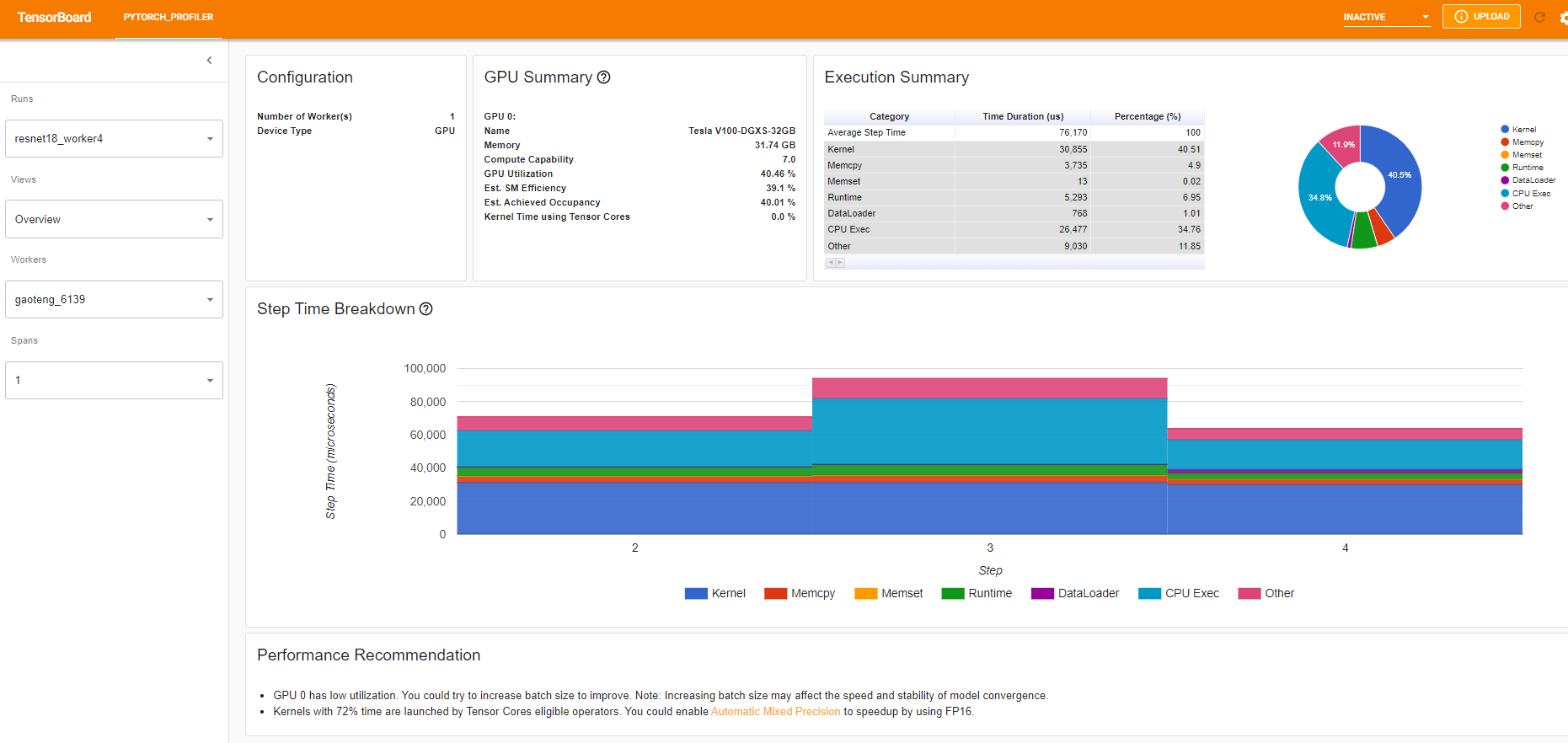
从上面的视图中,我们可以发现步骤时间已减少到大约 76ms,而之前的运行时间为 132ms,DataLoader 时间的减少是主要原因。
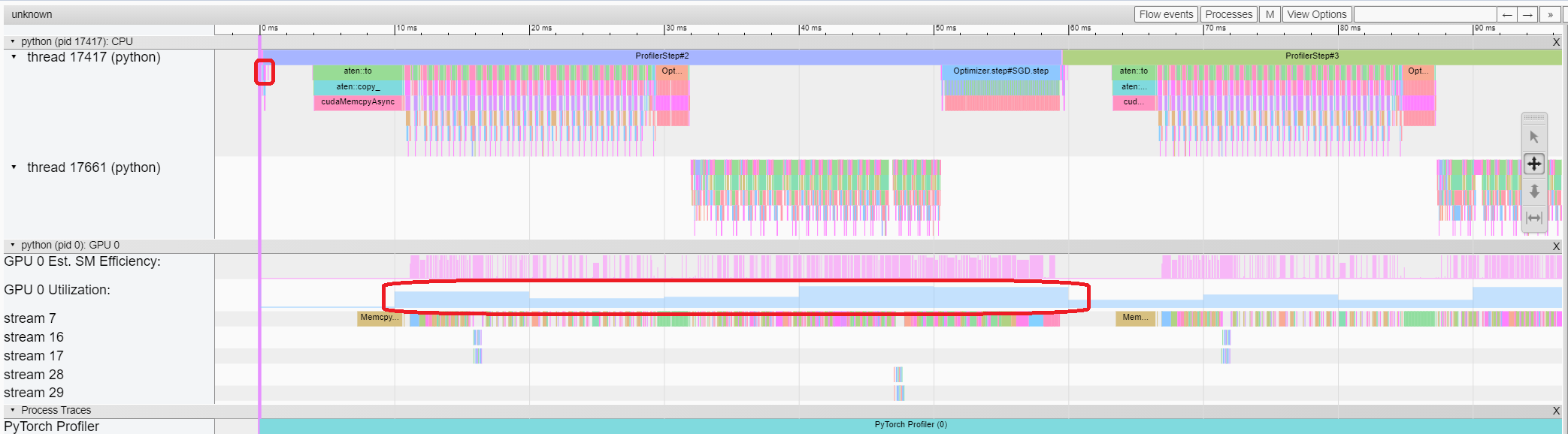
从上面的视图中,我们可以看到 enumerate(DataLoader) 的运行时已减少,GPU 利用率已提高。
6. 使用其他高级功能分析性能#
Memory view(内存视图)
要进行内存 profiling,必须在 torch.profiler.profile 的参数中将 profile_memory 设置为 True。
您可以在 Azure 上使用现有示例进行尝试
pip install azure-storage-blob
tensorboard --logdir=https://torchtbprofiler.blob.core.windows.net/torchtbprofiler/demo/memory_demo_1_10
Profiler 在 profiling 期间记录所有内存分配/释放事件以及分配器的内部状态。内存视图由三个组件组成,如下所示。
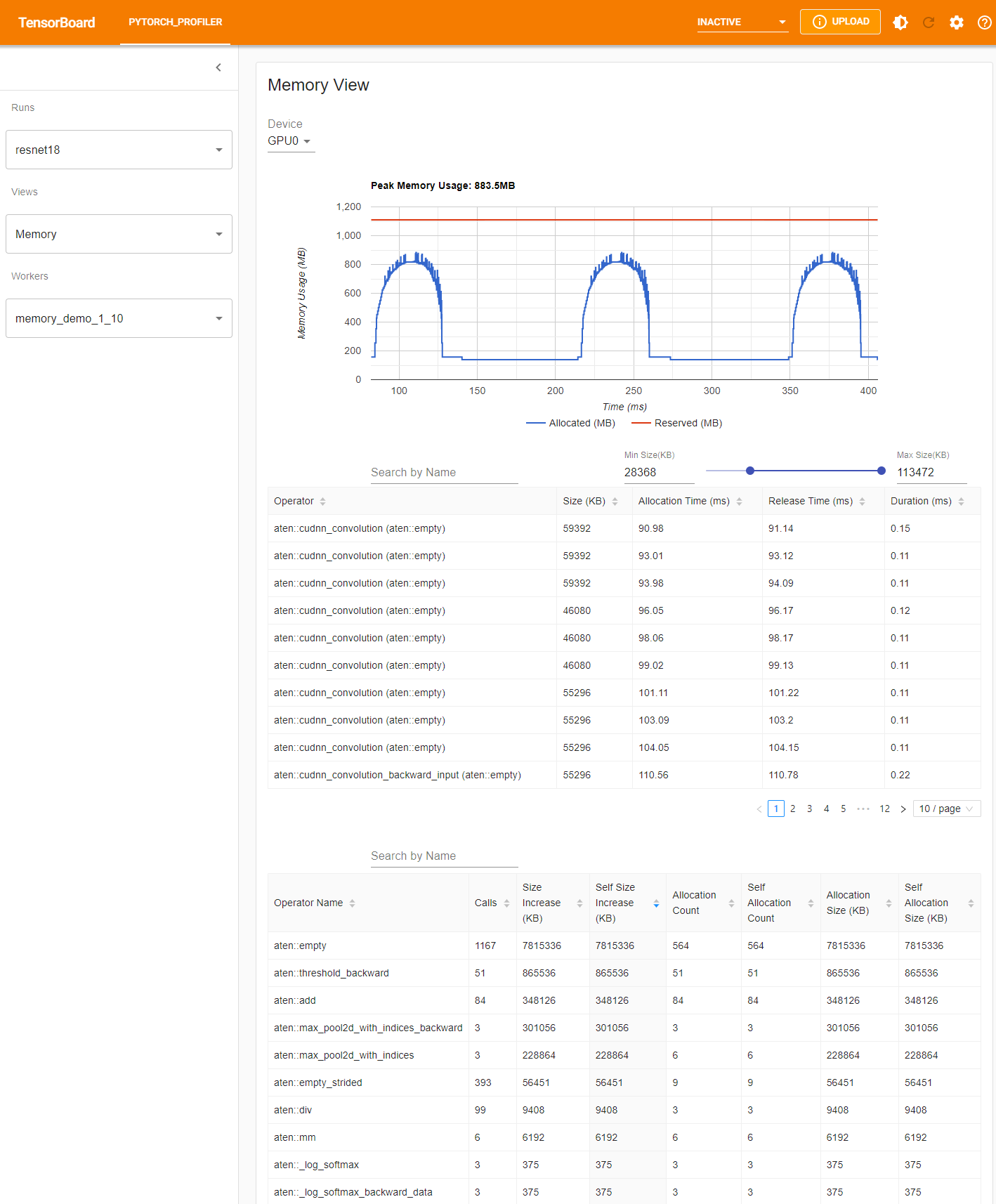
这些组件分别是内存曲线图、内存事件表和内存统计表,从上到下依次排列。
可以在“Device”(设备)选择框中选择内存类型。例如,“GPU0”表示下表仅显示 GPU 0 上每个算子的内存使用情况,不包括 CPU 或其他 GPU。
内存曲线显示了内存消耗的趋势。“Allocated”(已分配)曲线显示了实际使用的总内存,例如张量。在 PyTorch 中,CUDA 分配器和其他一些分配器采用了缓存机制。“Reserved”(已保留)曲线显示了分配器已保留的总内存。您可以左键单击并拖动图表以选择所需范围内的事件。
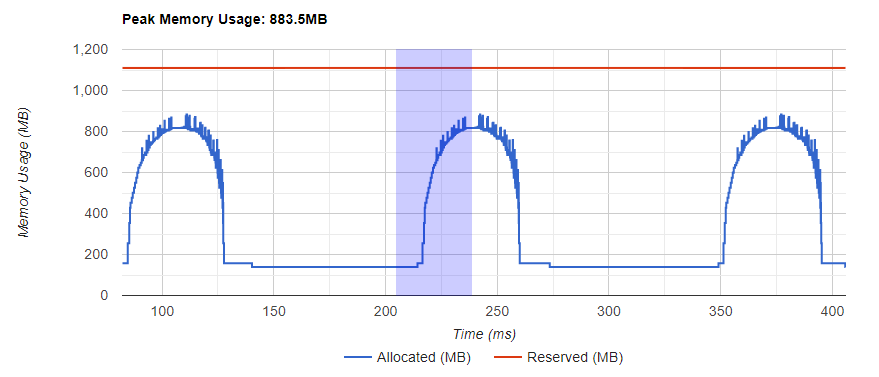
选择后,这三个组件将针对受限时间范围进行更新,以便您获得更多关于它的信息。通过重复此过程,您可以放大到非常精细粒度的细节。右键单击图表将图表重置到初始状态。
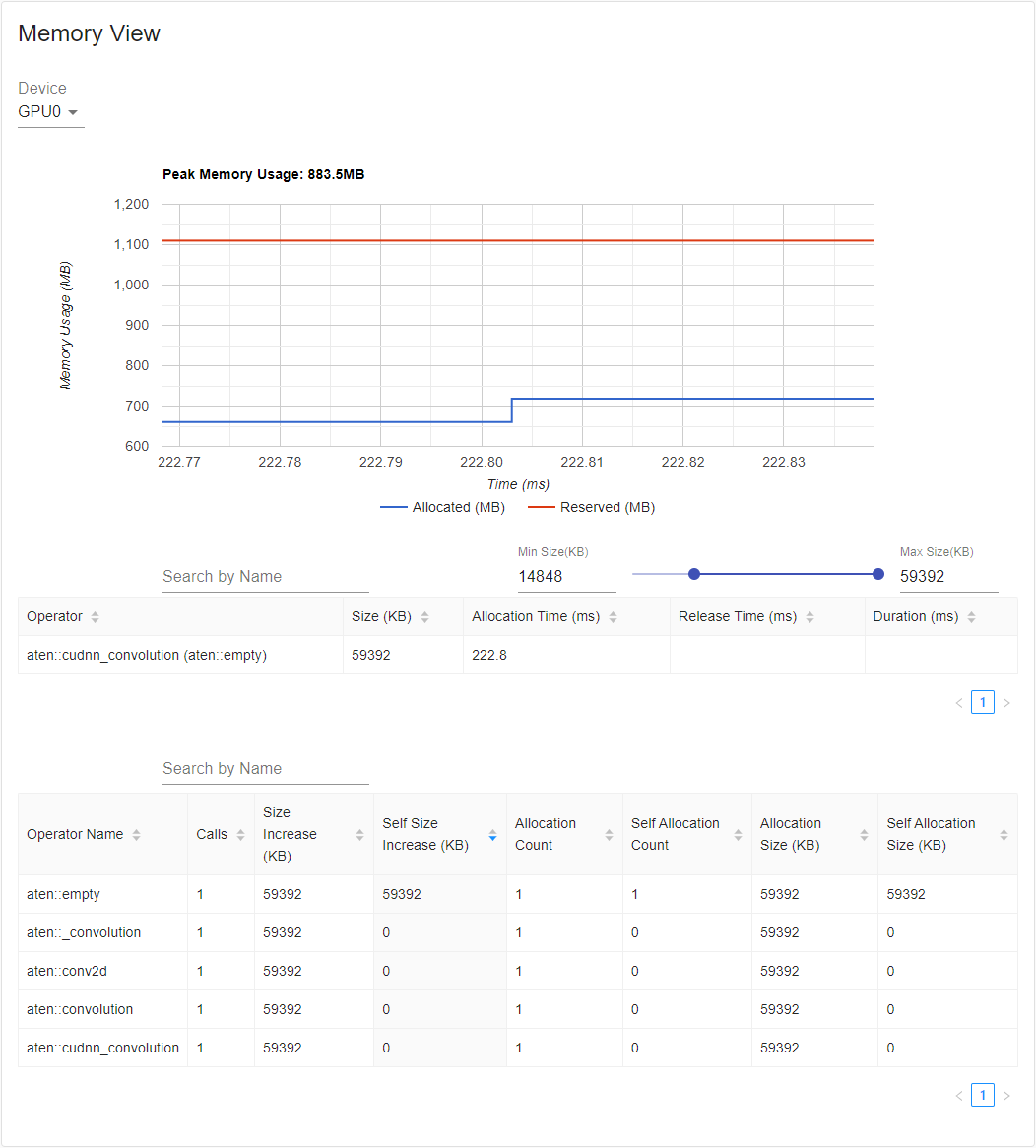
在内存事件表中,分配和释放事件配对成一条记录。“operator”(算子)列显示导致分配的直接 ATen 算子。请注意,在 PyTorch 中,ATen 算子通常使用 aten::empty 来分配内存。例如,aten::ones 实现为 aten::empty 后跟一个 aten::fill_。仅仅显示 aten::empty 算子名称帮助不大。在这种特殊情况下,它将显示为 aten::ones (aten::empty)。“Allocation Time”(分配时间)、“Release Time”(释放时间)和“Duration”(持续时间)列的数据可能丢失,如果事件发生在所选时间范围之外。
在内存统计表中,“Size Increase”(大小增加)列将所有分配大小相加并减去所有内存释放大小,即此算子后内存使用量的净增加。“Self Size Increase”(自身大小增加)列类似于“Size Increase”,但它不计算子算子的分配。关于 ATen 算子的实现细节,某些算子可能会调用其他算子,因此内存分配可能发生在调用堆栈的任何级别。也就是说,“Self Size Increase”仅计算当前调用堆栈级别的内存使用量增加。最后,“Allocation Size”(分配大小)列将所有分配相加,而不考虑内存释放。
Distributed view(分布式视图)
该插件现在支持在 profiling DDP(使用 NCCL/GLOO 作为后端)时进行分布式视图。
您可以在 Azure 上使用现有示例进行尝试
pip install azure-storage-blob
tensorboard --logdir=https://torchtbprofiler.blob.core.windows.net/torchtbprofiler/demo/distributed_bert
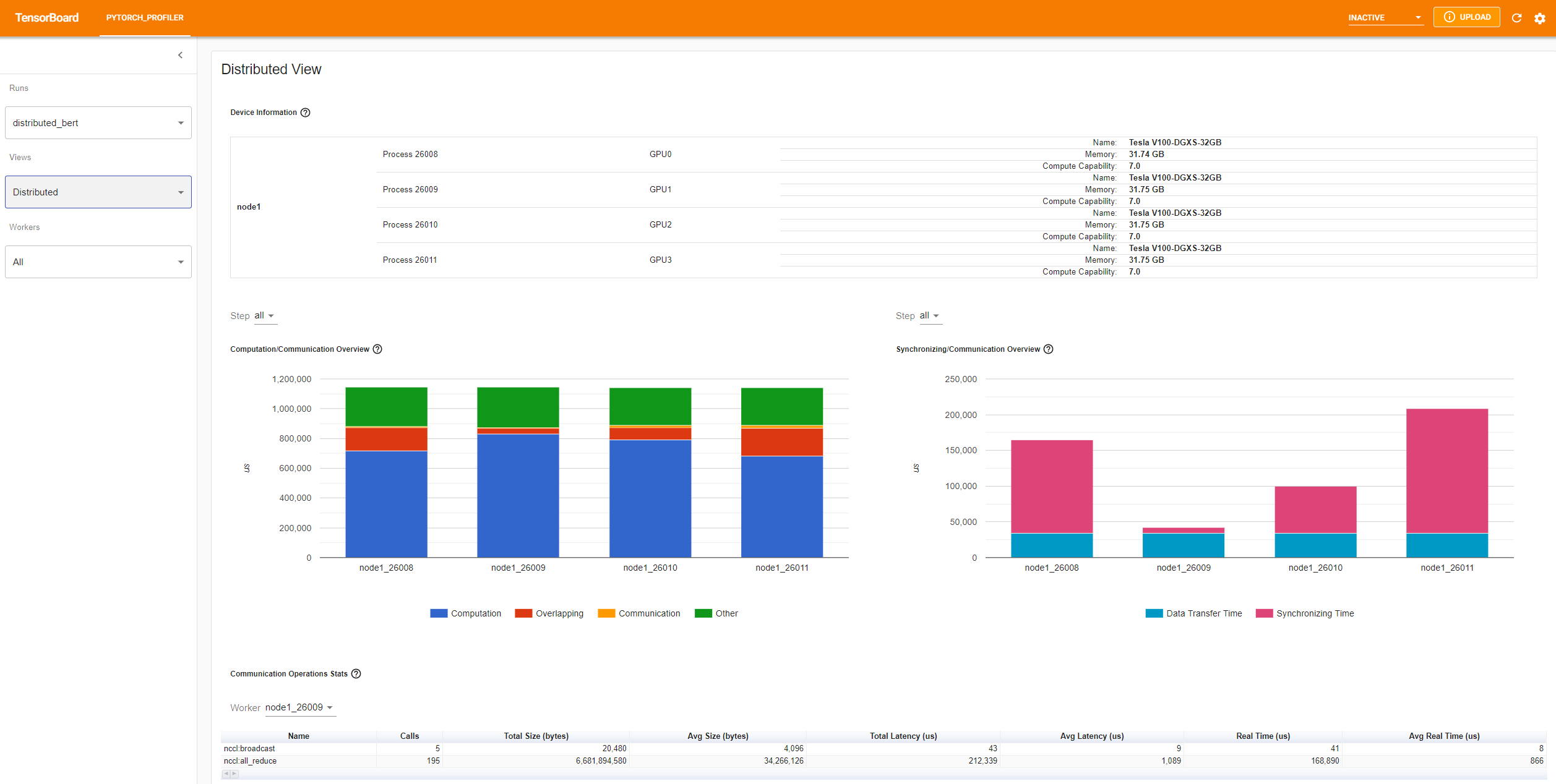
“Computation/Communication Overview”(计算/通信概览)显示了计算/通信的比例及其重叠程度。通过此视图,用户可以找出工作负载在 worker 之间的负载平衡问题。例如,如果一个 worker 的计算 + 重叠时间远大于其他 worker,则可能存在负载平衡问题,或者该 worker 可能是落后者。
“Synchronizing/Communication Overview”(同步/通信概览)显示了通信效率。“Data Transfer Time”(数据传输时间)是实际数据交换的时间。“Synchronizing Time”(同步时间)是与其他 worker 等待和同步的时间。
如果一个 worker 的“Synchronizing Time”(同步时间)比其他 worker 短很多,则该 worker 可能是落后者,它可能比其他 worker 承担了更多的计算工作负载。
“Communication Operations Stats”(通信操作统计)汇总了每个 worker 中所有通信操作的详细统计信息。
7. 额外实践:在 AMD GPU 上进行 PyTorch profiling#
AMD ROCm 平台是一个开源的 GPU 计算软件栈,包括驱动程序、开发工具和 API。我们可以在 AMD GPU 上运行上述步骤。在本节中,我们将使用 Docker 在安装 PyTorch 之前安装 ROCm 基本开发镜像。
为了举例说明,让我们创建一个名为 profiler_tutorial 的目录,并将 **步骤 1** 中的代码保存为 test_cifar10.py 在此目录中。
mkdir ~/profiler_tutorial
cd profiler_tutorial
vi test_cifar10.py
截至本文撰写之时,ROCm 平台上的 PyTorch 的稳定版(2.1.1)Linux 版本为 ROCm 5.6。
从 Docker Hub 获取安装了正确用户空间 ROCm 版本的基本 Docker 镜像。
它是 rocm/dev-ubuntu-20.04:5.6。
启动 ROCm 基本 Docker 容器
docker run -it --network=host --device=/dev/kfd --device=/dev/dri --group-add=video --ipc=host --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --shm-size 8G -v ~/profiler_tutorial:/profiler_tutorial rocm/dev-ubuntu-20.04:5.6
在容器内,安装安装 wheel 包所需的任何依赖项。
sudo apt update
sudo apt install libjpeg-dev python3-dev -y
pip3 install wheel setuptools
sudo apt install python-is-python3
安装 wheels
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm5.6
安装
torch_tb_profiler,然后运行 Python 文件test_cifar10.py。
pip install torch_tb_profiler
cd /profiler_tutorial
python test_cifar10.py
现在,我们拥有在 TensorBoard 中查看所需的所有数据
tensorboard --logdir=./log
选择 **步骤 4** 中描述的不同视图。例如,以下是 **Operator** 视图。
截至本文撰写本文时,**Trace** 视图不起作用,并且不显示任何内容。您可以通过在 Chrome 浏览器中键入 chrome://tracing 来解决此问题。
将
~/profiler_tutorial/log/resnet18目录下的trace.json文件复制到 Windows。
如果文件位于远程位置,您可能需要使用 scp 复制该文件。
在浏览器中的
chrome://tracing页面上,单击 **Load** 按钮加载 trace JSON 文件。
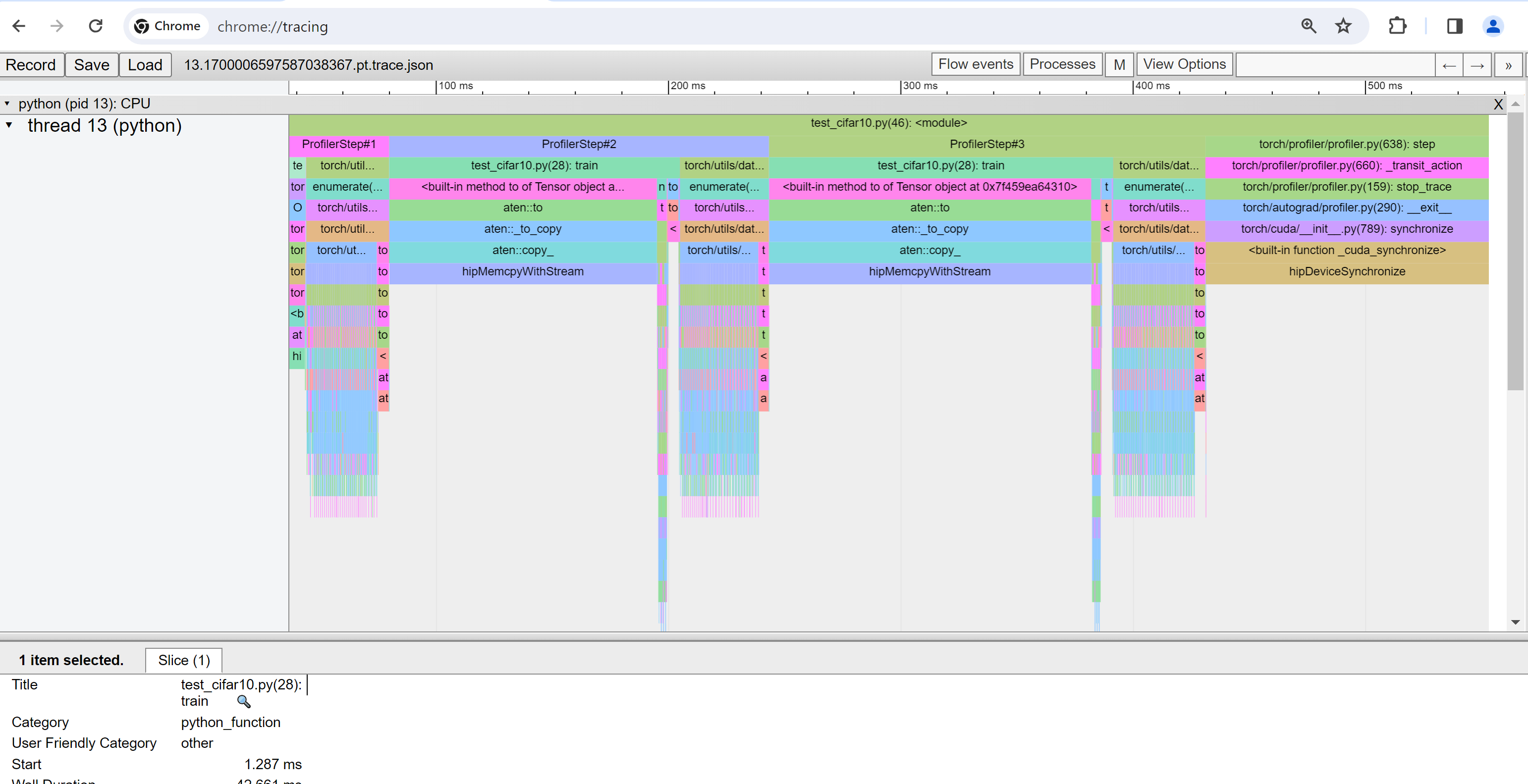
如前所述,您可以移动图形并放大/缩小。您还可以使用键盘在时间线内进行缩放和平移。'w' 和 's' 键以鼠标为中心缩放,'a' 和 'd' 键将时间线向左或向右移动。您可以多次按下这些键,直到看到可读的表示。
了解更多#
请参阅以下文档以继续您的学习,并随时在此 处 提交 issues。
