Backends and Delegates¶
受众:供应商、后端代理开发人员,他们有兴趣将自己的编译器和硬件作为 ExecuTorch 的一部分进行集成
后端代理是一个入口点,供后端处理和执行 PyTorch 程序,以利用专用后端和硬件的性能和效率优势,同时仍为 PyTorch 用户提供接近 PyTorch 运行时体验的体验。
Backend Interfaces: Overview¶
从宏观上看,后端的入口点由 2 个组件定义
表示程序的 IR:Edge Dialect(通过
to_edgeAPI 生成)供后端实现的几个接口
Ahead-of-Time (AOT)
程序预处理(例如,提前编译、转换、优化…)。
运行时
程序初始化(例如,运行时编译)。
程序执行。
(optional) Program destroy(例如,释放后端拥有的资源)。
代理后端实现由以下部分组成:
一个提前预处理接口
一个运行时初始化和执行接口
图示如下:
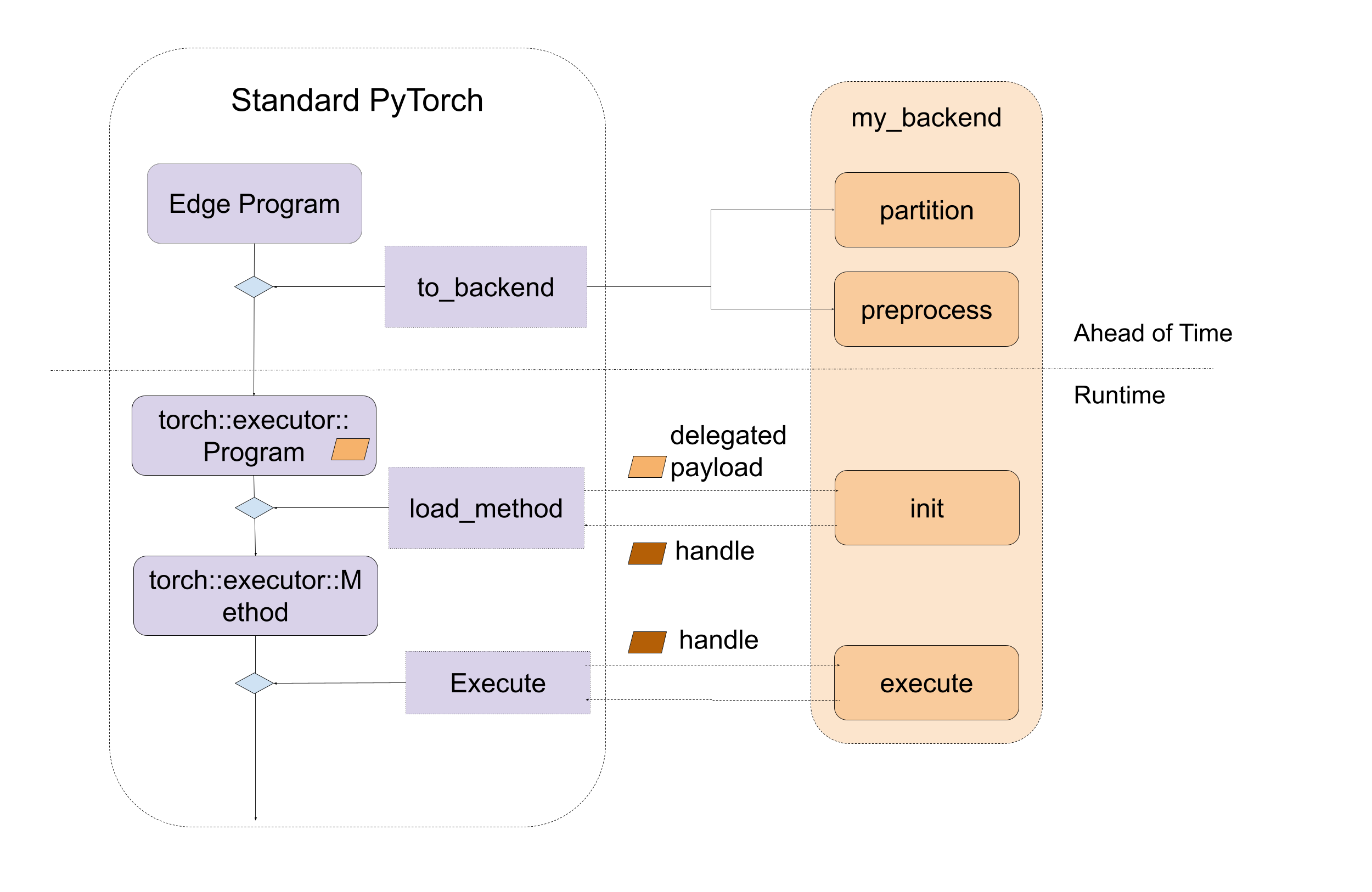
图 1. 后端接口的宏观入口点,包括提前和运行时。
Backend Interfaces: Ahead-of-Time Preprocessing¶
后端主要有两个提前的入口点需要实现:partition 和 preprocess。
partitioner 是由后端实现的算法,用于标记要下推到后端的节点。to_backend API 将应用分区算法,并将每个子图(由连接的标记节点组成)下推到目标后端。每个子图将被发送到后端提供的 preprocess 部分进行编译成二进制 blob。
在分区期间,不允许 exported_program 修改程序,它应该为每个节点应用标签。PartitionResult 包括标记的导出程序和分区标签字典,供 to_backend 查找标签并链接到 backend_id 和 compile_spec。
def partition(
exported_program: ExportedProgram,
) -> PartitionResult:
在预处理期间,后端会收到一个 edge dialect 程序,一个指定编译所需值的编译规范列表,并且需要返回一个编译后的 blob,或者包含将在后端运行的所需程序的二进制文件。在序列化过程中,编译后的 blob 将被序列化为 .pte 文件的一部分,并直接加载到设备上。此过程的 API 是:
def preprocess(
edge_program: ExportedProgram,
compile_specs: List[CompileSpec],
) -> PreprocessResult:
预处理函数的演示在此处实现。该演示遍历 edge_program 的图模块中的节点,并将 add、mul 和 sin 指令序列化为一个字符串,该字符串稍后在运行时进行解析和执行。
图示如下:
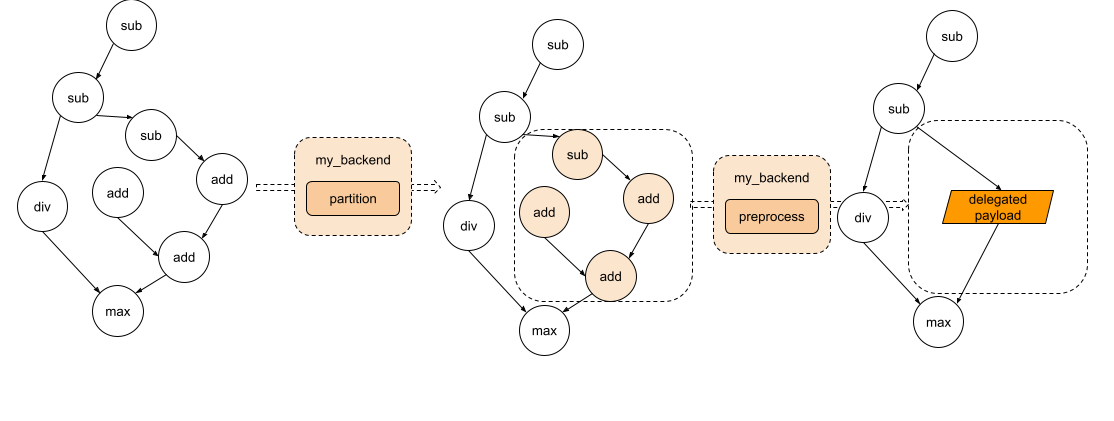
图 2. 图经过分区,每个子图将被发送到预处理部分。
Backend Interfaces: Runtime Initialization and Execution¶
在运行时,来自 preprocess 函数的编译 blob 将被加载并直接传递给后端的自定义 init 函数。此函数负责进一步处理编译单元,并执行任何后端初始化。init 生成的句柄将通过后端的自定义 execute 函数进行调用以执行。execute 函数将用于执行 init 生成的句柄。最后,如果某些后端需要销毁,后端可以实现一个 destroy 函数,该函数将在程序生命周期结束时被调用。
// Runtime check
ET_NODISCARD bool is_available();
// Runtime initialization
ET_NODISCARD virtual Result<DelegateHandle*> init(
BackendInitContext& context,
FreeableBuffer* processed,
ArrayRef<CompileSpec> compile_specs);
// Runtime execution
ET_NODISCARD virtual Error execute(
BackendExecutionContext& context,
DelegateHandle* handle,
EValue** args);
// [optional] Runtime destroy. Destroy the resource held by the backend
virtual void destroy(ET_UNUSED DelegateHandle* handle);
图示如下:
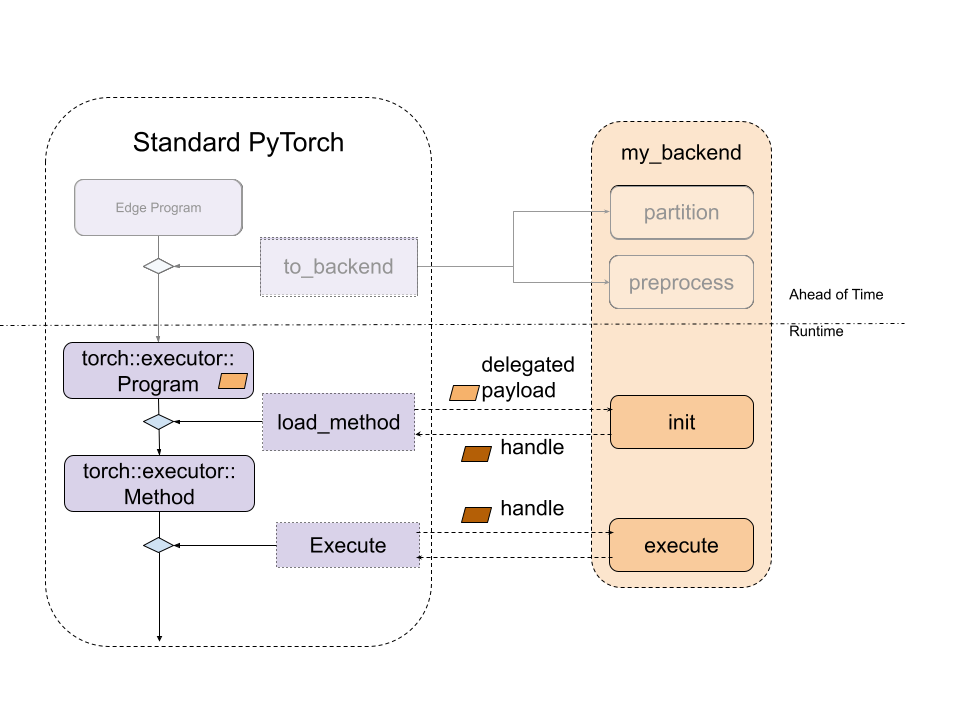
图 3. 标准 ExecuTorch Runtime 与后端入口点之间的关系。
为了使后端可供 ExecuTorch 运行时使用,必须通过 register_backend API 进行注册。
ET_NODISCARD Error register_backend(const Backend& backend);
可以通过以下方式实现后端的静态注册,即在库初始化或加载时:
namespace {
auto cls = BackendWithCompiler();
Backend backend{"BackendWithCompilerDemo", &cls};
static auto success_with_compiler = register_backend(backend);
} // namespace
Developer Tools Integration: Debuggability¶
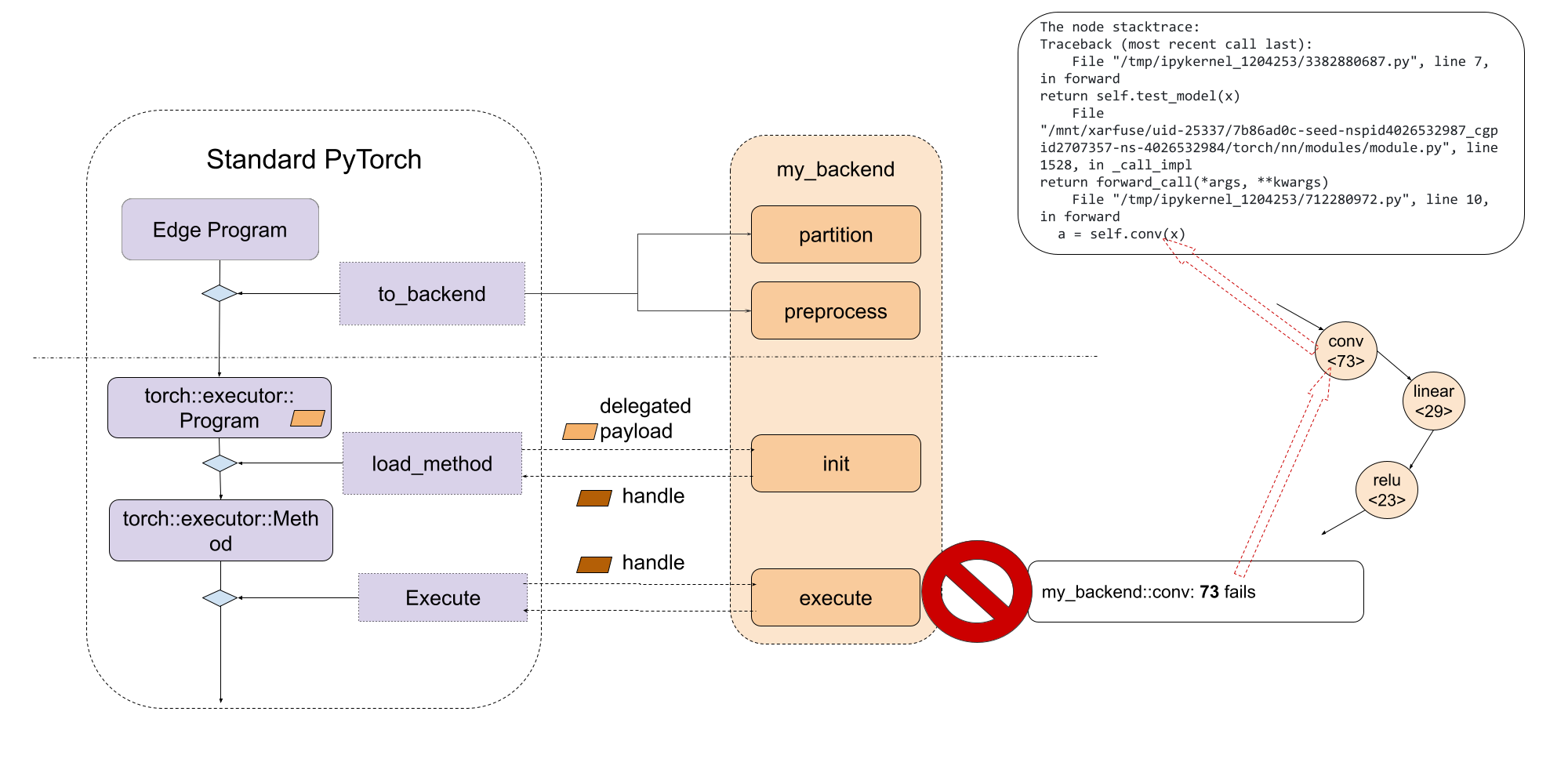
提供一致的调试体验,无论是运行时故障还是性能分析,都很重要。ExecuTorch 使用原生开发者工具来实现此目的,该工具可以通过调试句柄将程序指令与原始 PyTorch 代码关联起来。您可以在这里阅读更多相关信息。
被委托的程序或子图对 ExecuTorch 运行时来说是不透明的,它们显示为一个特殊的 call_delegate 指令,该指令要求相应的后端处理子图或程序的执行。由于后端代理的性质是不透明的,原生开发者工具无法看到被委托的程序。因此,与非委托执行相比,被委托执行的调试(功能或性能)体验会显着受到影响。
为了向用户提供一致的调试体验,无论是否对模型使用委托,开发者工具都提供了一个接口来关联委托的(子)图与原始(子)图。开发者工具通过调试句柄映射来实现这一点,该映射允许代理生成内部句柄,这些句柄可以与代理使用的原始(子)图关联起来。然后在运行时,后端开发人员可以使用内部句柄报告错误或性能信息,这些信息将通过调试句柄映射到原始(子)图。有关更多信息,请参阅Delegate Debugging。
通过利用调试标识符,后端开发人员可以将调试信息嵌入到委托的 blob 中。
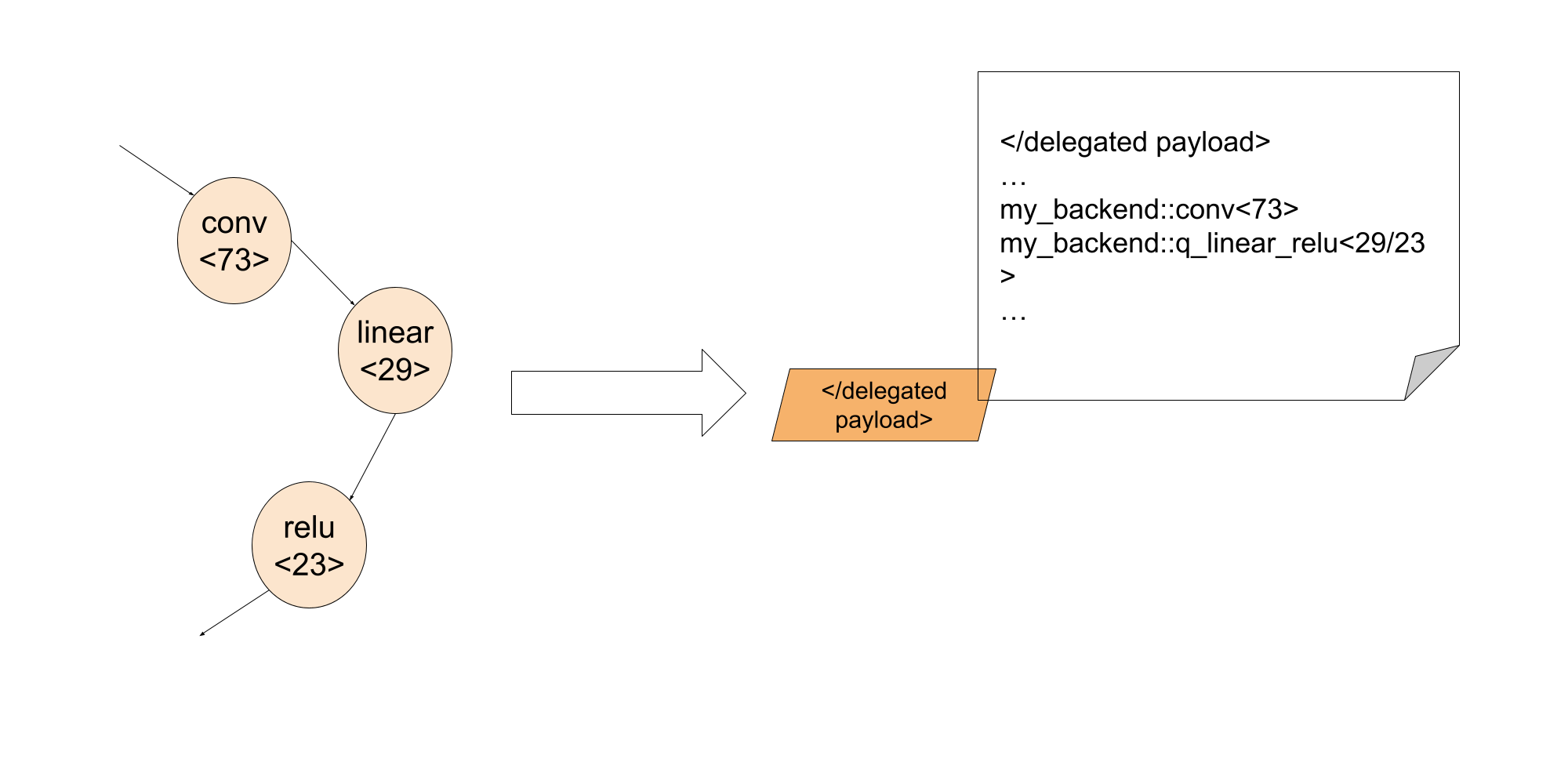
这样,在执行阶段,后端开发人员可以通过调试标识符将委托内部的失败指令关联到确切的 Python 代码行。
Common Questions¶
1. How can we get data in backend.preprocess?
正在预处理的图模块是一个提升的图,这意味着像权重和偏差这样的静态数据作为输入提供给图。但是,我们可以提前通过导出程序访问权重和偏差。要从给定节点访问这些参数,我们可以使用 torch/_export/utils.py 中提供的 get_params 函数。
2. How can we embed the data (like weight/bias) to the backend?
后端通常有某种方法来优化常量数据。在这种情况下,我们需要标记占位符节点,这些节点也是分区器中的状态,并且在 backend.preprocess 期间,我们可以按照第一个问题的描述来获取权重。
3. How can we run the lowered module in Python with the specific backend?
我们还没有添加支持,但这是计划中的!
4. Should we expect to see get_attr nodes in the edge dialect program?
get_attr 节点仅出现在用于控制流或委托的子模块中。它不包含任何数据。
5. Can we delegate to multiple backends?
可以!有两种方法可以做到:
Option 1: Run to_backend multiple times for different backends
如果我们有两个后端 backend_1 和 backend_2,并且它们有自己的分区器:backend_1_parititioner 和 backend_2_partitioner,我们可以这样运行:
# Will first lower nodes to backend_1 depending on the backend_1_parititioner depending on partitioner algorithm
exported_program_backend_1 = to_backend(exported_program, backend_1_parititioner())
# For the rest of nodes, they will be lowered to backend_2 depending on backend_2_parititioner
exported_program_backend_1_and_2 = to_backend(exported_program_backend_1, backend_2_parititioner())
一个更具体的例子可以在这里找到。在此示例中,qnnpack 是一个后端,xnnpack 是另一个后端。我们还没有开源这两个后端代理,此示例也无法开箱即用。它可以作为参考,了解如何实现。
此选项易于尝试,因为通常所有后端都会实现自己的分区器。但是,如果更改 to_backend 调用的顺序,此选项可能会得到不同的结果。如果我们想更好地控制节点,例如它们应该去哪个后端,选项 2 更好。
Option 2: Have a partitioner which partitions for different backends
另一种选择是创建一个自定义分区器,例如 partitioner backend_1_2_partitioner,并在分区器逻辑中,
class Backend_1_2_Partitioner(Partitioner):
"""
Partitions all add/mul nodes regardless of order for Backend2
"""
def __init__(self) -> None:
self.delegation_spec_1 = DelegationSpec("Backend1", [])
self.delegation_spec_2 = DelegationSpec("Backend2", [])
self.partition_tags = {}
def partition(
self, exported_program: ExportedProgram
) -> ExportedProgram:
# Tag all nodes in the first partiton to backend 1
node_to_backend_1 = ... # some logic to select the nodes from the graph
delegation_tag = f"backend2_tag{partitioner_1.id}"
node.meta["delegation_tag"] = delegation_tag
self.partition_tags[delegation_tag] = self.delegation_spec_1
# Tag all nodes in the first partiton to backend 2
node_to_backend_2 = ... # some logic to select the nodes from the graph
delegation_tag = f"backend2_tag{partitioner_2.id}"
node.meta["delegation_tag"] = delegation_tag
self.partition_tags[delegation_tag] = self.delegation_spec_2
return exported_program
6. Is there an easy way to write a partitioner?
我们提供了一些辅助分区器在此处,以便轻松从分解的操作符中查找节点。
7. How do we link the node back to the source code? We provide an helper function
from executorch.exir.print_program import inspect_node
print(inspect_node(graph, node))
它将突出显示图中的节点,并指向源代码,例如输出如下:
_param_constant1 error_msg: Here is the node in the graph module:
graph():
%arg0_1 : [num_users=1] = placeholder[target=arg0_1]
%_param_constant0 : [num_users=1] = get_attr[target=_param_constant0]
--> %_param_constant1 : [num_users=1] = get_attr[target=_param_constant1]
%aten_convolution_default : [num_users=2] = call_function[target=executorch.exir.dialects.edge._ops.aten.convolution.default](args = (%arg0_1, %_param_constant0, %_param_constant1, [1, 1], [0, 0], [1, 1], False, [0, 0], 1), kwargs = {})
%_param_constant2 : [num_users=1] = get_attr[target=_param_constant2]
%_param_constant3 : [num_users=1] = get_attr[target=_param_constant3]
%aten_convolution_default_1 : [num_users=1] = call_function[target=executorch.exir.dialects.edge._ops.aten.convolution.default](args = (%aten_convolution_default, %_param_constant2, %_param_constant3, [1, 1], [0, 0], [1, 1], False, [0, 0], 1), kwargs = {})
%aten_add_tensor : [num_users=1] = call_function[target=executorch.exir.dialects.edge._ops.aten.add.Tensor](args = (%aten_convolution_default, %aten_convolution_default_1), kwargs = {})
%_param_constant4 : [num_users=1] = get_attr[target=_param_constant4]
%_param_constant5 : [num_users=1] = get_attr[target=_param_constant5]
%aten_convolution_default_2 : [num_users=1] = call_function[target=executorch.exir.dialects.edge._ops.aten.convolution.default](args = (%aten_add_tensor, %_param_constant4, %_param_constant5, [1, 1], [0, 0], [1, 1], False, [0, 0], 1), kwargs = {})
%aten_gelu_default : [num_users=1] = call_function[target=executorch.exir.dialects.edge._ops.aten.gelu.default](args = (%aten_convolution_default_2,), kwargs = {})
return [aten_gelu_default]
This node _param_constant1 has metadata of:
The node stacktrace:
Traceback (most recent call last):
File "/tmp/ipykernel_1204253/3382880687.py", line 7, in forward
return self.test_model(x)
File "/mnt/xarfuse/uid-25337/7b86ad0c-seed-nspid4026532987_cgpid2707357-ns-4026532984/torch/nn/modules/module.py", line 1528, in _call_impl
return forward_call(*args, **kwargs)
File "/tmp/ipykernel_1204253/712280972.py", line 10, in forward
a = self.conv1(x)
