ExecuTorch Runtime 概述¶
本文档讨论了 ExecuTorch runtime 的设计,该 runtime 在智能手机、可穿戴设备和嵌入式设备等边缘设备上执行 ExecuTorch 程序文件。主要执行 API 的代码位于 executorch/runtime/executor/。
在阅读本文档之前,我们建议您阅读 ExecuTorch 如何工作。
从最高层面来看,ExecuTorch runtime 负责
加载由模型降低过程的
to_executorch()步骤生成的二进制.pte程序文件。执行实现降低后的模型的指令序列。
请注意,截至 2023 年底,ExecuTorch runtime 仅支持模型推理,尚不支持训练。
此图显示了导出和执行 ExecuTorch 程序的最高层流程和涉及的组件
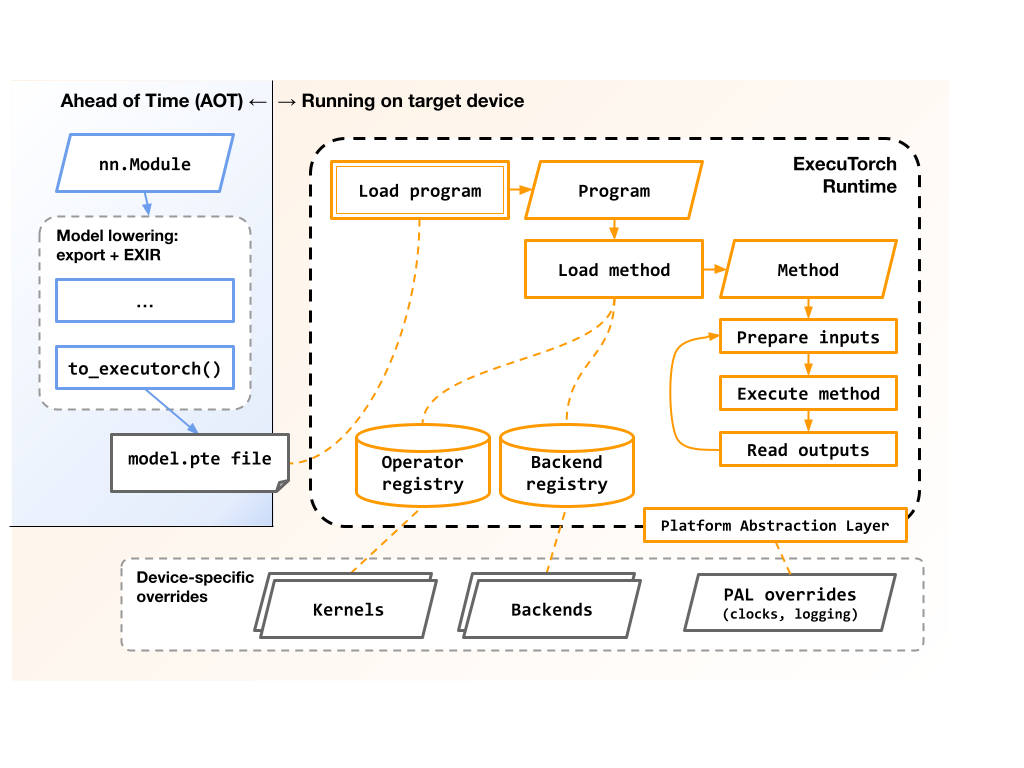
runtime 还负责
管理加载和执行期间使用的内存,可能跨越 SRAM 和 DRAM 等多个内存バンク。
将符号运算符名称(如
"aten::add.out")映射到实现这些运算符语义的具体 C++ 函数或 kernels。将模型的预定部分分派给 后端代理 以进行加速。
在加载和执行期间可选地收集 分析数据。
设计目标¶
ExecuTorch runtime 被设计用于在各种边缘设备上运行,从现代智能手机 CPU 到资源受限的微控制器和 DSP。它对将执行 委托 给一个或多个后端以利用特定于架构的优化和现代异构架构提供了头等支持。它足够小且可移植,可以直接在没有操作系统、动态内存或线程的裸金属嵌入式环境中运行。
低执行开销¶
内存¶
核心 runtime 库在不构建 kernels 或 backends 的情况下小于 50KB。
常量张量直接指向
.pte文件数据,避免了对该数据的复制。这些数据块的对齐可以在创建.pte文件时进行调整。后端代理可以选择在模型初始化后卸载其预编译的数据,从而减少峰值内存使用量。
可变张量的内存布局会提前规划,并打包到少量用户分配的缓冲区中,从而提供对内存位置的细粒度控制。这在具有异构内存层次结构的系统上尤其有用,允许将数据放置在(例如)SRAM 或 DRAM 中,靠近将要操作数据的核心。
CPU¶
模型执行是一个简单的指令数组循环,其中大部分是函数指针,指向 kernels 和后端代理。这使得执行开销很小,每个操作大约在微秒到纳秒之间。
操作(如“add”或“conv3d”)的实现可以针对特定目标系统进行完全定制,而无需修改原始模型或生成的
.pte文件。
熟悉的 PyTorch 语义¶
ExecuTorch 是 PyTorch 堆栈中的一等组件,并在可能的情况下重用 API 和语义。
ExecuTorch 使用的 C++ 类型与核心 PyTorch 的
c10::和at::库中的相应类型在源代码上兼容,并且 ExecuTorch 提供了aten_bridge以在两者之间进行转换。这对于已经使用 PyTorch C++ 类型的项目可能很有帮助。像
aten::add和aten::sigmoid这样的运算符的语义在 ExecuTorch 和核心 PyTorch 之间是相同的。ExecuTorch 提供了一个测试框架来确保这一点,并帮助测试这些运算符的未来实现。
可移植代码和架构¶
ExecuTorch runtime 的实现考虑了可移植性,以便用户可以为各种目标系统构建它。
C++ 语言注意事项¶
代码兼容 C++17,以支持较旧的工具链。
runtime 不使用异常或 RTTI,尽管它并不排斥它们。
代码与 GCC 和 Clang 兼容,并且也使用多个专有嵌入式工具链进行了构建。
该仓库提供了 CMake 构建系统,以简化集成。
操作系统注意事项¶
runtime 不进行直接的系统调用。所有对内存、文件、日志记录和时钟的访问都通过 Runtime Platform Abstraction Layer (PAL) 以及 DataLoader 和 MemoryAllocator 等注入的接口进行了抽象。请参阅 runtime api 参考 以了解更多信息。
应用程序可以通过 MemoryManager、MemoryAllocator、HierarchicalAllocator 和 DataLoader 类来控制所有内存分配。核心 runtime 不会直接调用 malloc() 或 new,也不会调用 std::vector 等在后台分配的类型。这使得以下操作成为可能:
在没有堆的环境中运行,但仍然可以使用堆(如果需要)。
在模型加载和执行期间避免对堆进行同步。
控制为不同类型的数据使用哪个内存区域。例如,一组可变张量可以位于 SRAM 中,而另一组则位于 DRAM 中。
轻松监视 runtime 使用的内存量。
但是,请注意,特定的 kernel 或后端实现可能使用任意的 runtime 或操作系统功能。用户应仔细检查他们使用的 kernel 和后端库的文档。
线程注意事项¶
核心 runtime 不执行线程或锁定,也不使用线程局部变量。但是,它与更高级别的同步配合良好。
每个
Program实例都是不可变的,因此是完全线程安全的。多个线程可以并发访问单个Program实例。每个
Method实例是可变的但自包含的,因此是条件线程安全的。多个线程可以并发访问和执行独立的Method实例,但对单个实例的访问和执行必须进行串行化。
但是,请注意
在
Program::load_method()期间可能会读取两个全局表:kernel 注册表和 backend 注册表。实际上,这些表只在进程/系统加载时被修改,并在加载第一个
Program之前被有效冻结。但某些应用程序可能需要了解这些表,尤其是在它们在进程/系统加载后手动修改它们的情况下。
特定的 kernel 或 backend 实现可能有自己的线程限制。用户应仔细检查他们使用的 kernel 和 backend 库的文档。
延伸阅读¶
有关 ExecuTorch runtime 的更多详细信息,请参阅
