概念¶
本页面提供了 ExecuTorch 文档中使用的关键概念和术语的概述。旨在帮助读者理解 PyTorch Edge 和 ExecuTorch 中使用的术语和概念。
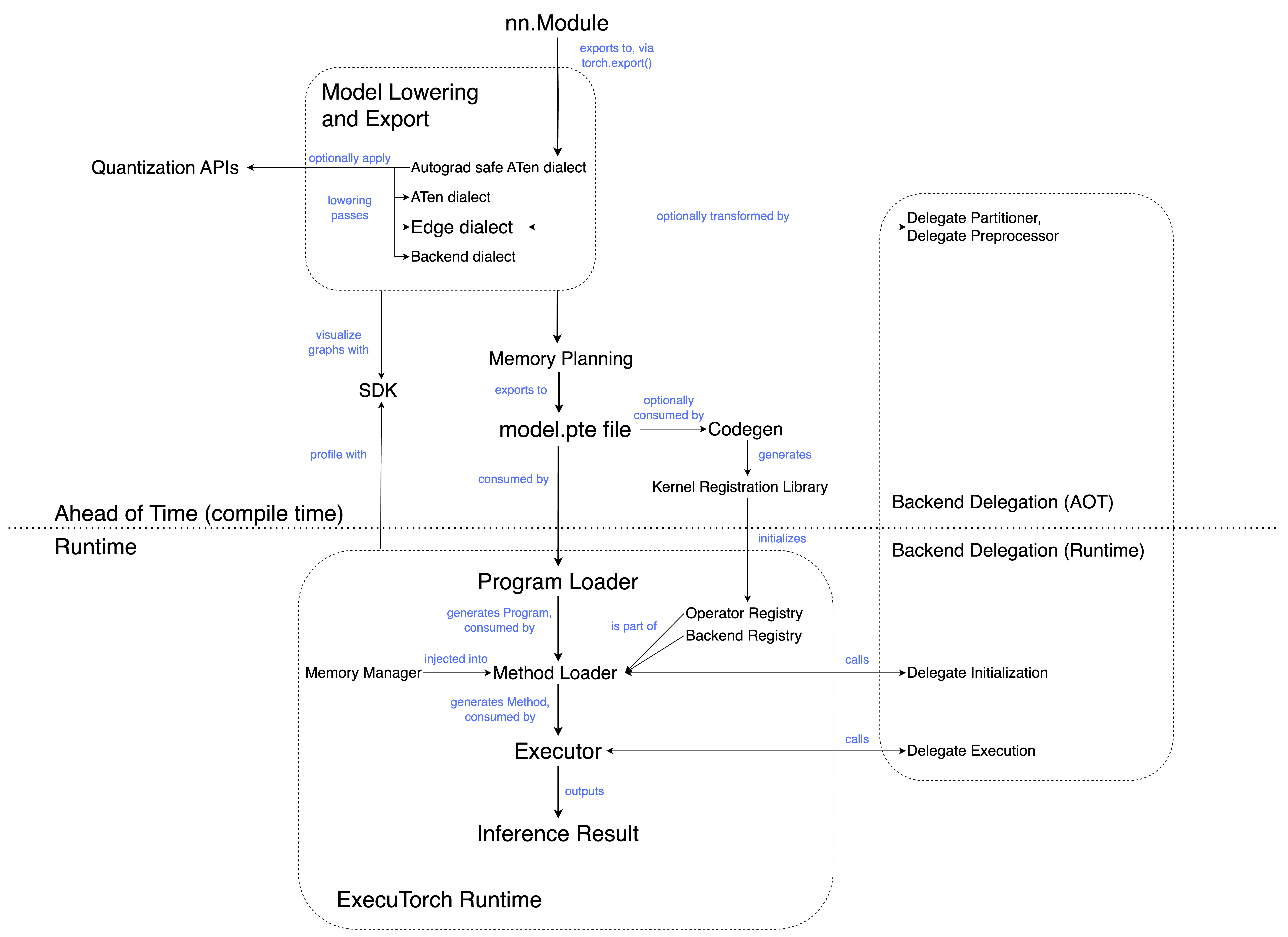
AOT (Ahead of Time)¶
AOT 通常指在执行之前发生的程序准备。从高层次来看,ExecuTorch 工作流分为 AOT 编译和运行时。AOT 步骤包括编译成中间表示 (IR),以及可选的转换和优化。
ATen Dialect¶
ATen Dialect 是将 eager 模块导出为图表示的直接结果。它是 ExecuTorch 编译管道的入口点;导出到 ATen Dialect 后,后续的传递可以降低到 Core ATen Dialect 和 Edge Dialect。
ATen Dialect 是一个有效的 EXIR,具有附加属性。它包含函数式 ATen 运算符、高阶运算符(如控制流运算符)和已注册的自定义运算符。
ATen Dialect 的目标是尽可能忠实地捕获用户的程序。
ATen 模式¶
ATen 模式使用 PyTorch 核心的 Tensor (at::Tensor) 和相关类型的 ATen 实现,如 ScalarType。这与 ETensor 模式相反,ETensor 模式使用 ExecuTorch 更小的张量实现 (executorch::runtime::etensor::Tensor) 和相关类型,如 executorch::runtime::etensor::ScalarType。
在此配置中,依赖于完整的
at::TensorAPI 的 ATen 内核是可用的。ATen 内核倾向于进行动态内存分配,并且通常具有额外的灵活性(以及由此带来的开销)来处理移动/嵌入式客户端不需要的场景。例如,CUDA 支持、稀疏张量支持和 dtype 提升。
注意:ATen 模式目前正在开发中。
Autograd 安全 ATen Dialect¶
Autograd 安全 ATen Dialect 只包含可微分的 ATen 运算符,以及高阶运算符(控制流 ops)和已注册的自定义运算符。
后端¶
消耗图或图的一部分的特定硬件(如 GPU、NPU)或软件堆栈(如 XNNPACK),并带来性能和效率优势。
Backend Dialect¶
Backend Dialect 是将 Edge Dialect 导出到特定后端的直接结果。它具有目标感知性,可能包含仅对目标后端有意义的运算符或子模块。此 Dialect 允许引入不符合 Core ATen Operator Set 中定义的模式且不在 ATen 或 Edge Dialect 中显示的特定于目标的运算符。
Backend registry¶
一个将后端名称映射到后端接口的表。这允许在运行时通过名称调用后端。
Backend Specific Operator¶
这些运算符不属于 ATen Dialect 或 Edge Dialect。Backend Specific Operator 仅由 Edge Dialect 之后的传递引入(参见 Backend Dialect)。这些运算符特定于目标后端,通常执行速度更快。
Codegen¶
从高层次来看,codegen 执行两项任务;生成 内核注册 库,以及可选地运行 选择性构建。
内核注册库将模型中引用的运算符名称与相应的内核实现(来自内核库)进行连接。
选择性构建 API 从模型和/或其他来源收集运算符信息,并且仅包含它们所需的运算符。这可以减小二进制文件大小。
codegen 的输出是一组 C++ 绑定(各种 .h、.cpp 文件),它们将内核库和 ExecuTorch 运行时连接起来。
Core ATen Dialect¶
Core ATen Dialect 包含核心 ATen 运算符,以及高阶运算符(控制流)和已注册的自定义运算符。
Core ATen operators / Canonical ATen operator set¶
PyTorch ATen 运算符库的一个精选子集。核心 ATen 运算符在导出时不会被分解(使用核心 ATen 分解表)。它们作为后端或编译器应从上游期望的基线 ATen 运算符的参考。
Core ATen Decomposition Table¶
分解运算符意味着将其表示为其他运算符的组合。在 AOT 过程中,会采用默认的分解列表,将 ATen 运算符分解为核心 ATen 运算符。这被称为核心 ATen 分解表。
Custom operator¶
这些运算符不属于 ATen 库,但出现在 eager mode 中。已注册的自定义运算符被注册到当前的 PyTorch eager 模式运行时,通常使用 TORCH_LIBRARY 调用。它们最有可能与特定的目标模型或硬件平台相关。例如,torchvision::roi_align 是 torchvision 广泛使用的自定义运算符(不针对特定硬件)。
DataLoader¶
一个接口,使 ExecuTorch 运行时能够从文件或其他数据源读取,而无需直接依赖于文件或内存分配等操作系统概念。
Delegation¶
在特定后端(例如 XNNPACK)上运行程序的部分(或全部)代码,而程序的其余部分(如果有)在基本的 ExecuTorch 运行时上运行。委托使我们能够利用专用后端和硬件的性能和效率优势。
Dim Order¶
ExecuTorch 引入了 Dim Order 来描述张量的内存格式,通过返回维度排列,从最外层到最内层。
例如,对于内存格式为 [N, C, H, W] 或 contiguous 内存格式的张量,其维度顺序将是 [0, 1, 2, 3]。
同样,对于内存格式为 [N, H, W, C] 或 channels_last 内存格式 的张量,我们返回其维度顺序为 [0, 2, 3, 1]。
目前 ExecuTorch 只支持 contiguous 和 channels_last 内存格式的维度顺序表示。
DSP (Digital Signal Processor)¶
专门的微处理器芯片,其架构针对数字信号处理进行了优化。
dtype¶
数据类型,即张量中数据的类型(例如,浮点数、整数等)。
Dynamic Quantization¶
一种量化方法,其中张量在推理过程中即时量化。这与 static quantization 不同,后者在推理之前量化张量。
Dynamic shapes¶
指模型在推理过程中接受不同形状输入的 L能力。例如,ATen 运算符 unique_consecutive 和自定义运算符 MaskRCNN 具有依赖于数据的输出形状。这类运算符的内存规划很难进行,因为每次调用都可能产生不同的输出形状,即使输入形状相同。为了在 ExecuTorch 中支持动态形状,内核可以使用客户端提供的 MemoryAllocator 来分配张量数据。
Eager mode¶
Python 执行环境,其中模型中的运算符在遇到时立即执行。例如,Jupyter / Colab 笔记本在 eager 模式下运行。这与图模式(graph mode)相反,后者先将运算符合成为一个图,然后进行编译和执行。
Edge Dialect¶
EXIR 的一个 Dialect,具有以下特性:
所有运算符都来自预定义的运算符集“Edge Operators”,或者为已注册的自定义运算符。
图的输入和输出,以及每个节点的输入和输出都必须是 Tensor。所有标量类型都转换为 Tensor。
Edge Dialect 引入了对 Edge 设备有用的专门化,但不一定对通用(服务器)导出有益。但是,Edge Dialect 不包含除原始 Python 程序中已有的专门化之外的特定于硬件的专门化。
Edge operator¶
具有 dtype 专门化的 ATen 运算符。
ExecuTorch¶
PyTorch Edge 平台内的一个统一 ML 软件堆栈,专为高效的设备端推理而设计。ExecuTorch 定义了一个工作流程,用于在移动、可穿戴设备和嵌入式设备等 Edge 设备上准备(导出和转换)和执行 PyTorch 程序。
ExecuTorch Method¶
Python 方法 nn.Module 的可执行等价物。例如,forward() Python 方法将编译成 ExecuTorch Method。
ExecuTorch Program¶
ExecuTorch Program 将字符串名称(如 forward)映射到特定的 ExecuTorch Method 条目。
executor_runner¶
ExecuTorch 运行时的一个示例包装器,包含所有运算符和后端。
EXIR¶
来自 torch.export 的 **EX**port **I**ntermediate **R**epresentation (IR)。包含模型的计算图。所有 EXIR 图都是有效的 FX 图。
ExportedProgram¶
torch.export 的输出,它将 PyTorch 模型的计算图(通常是 nn.Module)与模型使用的参数或权重捆绑在一起。
flatbuffer¶
内存高效、跨平台的序列化库。在 ExecuTorch 的上下文中,eager 模式的 Pytorch 模型被导出为 flatbuffer,这是 ExecuTorch 运行时所使用的格式。
Framework tax¶
各种加载和初始化任务(非推理)的成本。例如;加载程序、初始化执行器、内核和后端委托调度以及运行时内存利用。
Functional ATen operators¶
没有副作用的 ATen 运算符。
Graph¶
EXIR Graph 是以 DAG(有向无环图)形式表示的 PyTorch 程序。图中的每个节点代表一个特定的计算或操作,图的边由节点之间的引用组成。注意:所有 EXIR 图都是有效的 FX 图。
Graph mode¶
在图模式下,运算符首先被合成一个图,然后作为一个整体进行编译和执行。这与 eager 模式相反,在 eager 模式下,运算符在遇到时就被执行。图模式通常提供更高的性能,因为它允许进行运算符融合等优化。
Higher Order Operators¶
高阶运算符(HOP)是一个运算符,它
接受 Python 函数作为输入,返回 Python 函数作为输出,或者两者兼有。
与所有 PyTorch 运算符一样,高阶运算符也有一个可选的后端和功能实现。这允许我们例如为高阶运算符注册 autograd 公式,或定义高阶运算符在 ProxyTensor 跟踪下的行为。
Hybrid Quantization¶
一种量化技术,其中模型的不同部分根据计算复杂度和对精度损失的敏感度采用不同的技术进行量化。模型的部分可能不会被量化以保留精度。
Intermediate Representation (IR)¶
源代码和目标语言之间的程序表示。通常,它是编译器或虚拟机用于表示源代码的内部数据结构。
Kernel¶
运算符的实现。对于不同的后端/输入/等,一个运算符可以有多个实现。
Kernel registry / Operator registry¶
一个包含内核名称及其实现映射的表。这允许 ExecuTorch 运行时在执行期间解析内核的引用。
Lowering¶
将模型转换为在各种后端上运行的过程。之所以称为“低级化”(lowering),是因为它将代码移近硬件。在 ExecuTorch 中,低级化作为后端委托的一部分执行。
Memory planning¶
为模型分配和管理内存的过程。在 ExecuTorch 中,在图被保存到 flatbuffer 之前会运行一个内存规划传递。这个传递会为每个张量分配一个内存 ID 和在 buffer 中的偏移量,标记张量存储的开始位置。
Node¶
EXIR 图中的节点代表一个特定的计算或操作,并在 Python 中使用 torch.fx.Node 类表示。
Operator¶
张量上的函数。这是抽象;内核是实现。对于不同的后端/输入/等,可以有不同的实现。
Operator fusion¶
运算符融合是将多个运算符合并成一个复合运算符的过程,由于内核启动次数减少以及内存读写次数减少,从而提高了计算速度。这是图模式相对于 eager 模式的性能优势。
Out variant¶
与其在内核实现中分配返回的张量,不如将运算符的 out 变体在 out kwargs 中接受一个预分配的张量,并将结果存储在那里。
这使得内存规划器更容易执行张量生命周期分析。在 ExecuTorch 中,在内存规划之前会执行一个 out 变体传递。
PAL (Platform Abstraction Layer)¶
提供了一种让执行环境能够覆盖操作的方法,例如:
获取当前时间。
打印日志语句。
使进程/系统崩溃。如果默认的 PAL 实现不适用于特定的客户端系统,则可以对其进行覆盖。
Partial kernels¶
支持部分张量 dtype 和/或维度顺序的内核。
Partitioner¶
模型的某些部分可以委托给优化的后端运行。分区器将图分割成适当的子网络,并为其打上委托标签。
ETensor mode¶
ETensor 模式使用 ExecuTorch 更小的张量实现 (executorch::runtime::etensor::Tensor) 以及相关类型(executorch::runtime::etensor::ScalarType 等)。这与 ATen 模式相反,ATen 模式使用 Tensor 的 ATen 实现(at::Tensor)和相关类型(ScalarType 等)。
executorch::runtime::etensor::Tensor,也称为 ETensor,是at::Tensor的源兼容子集。针对 ETensor 编写的代码可以针对at::Tensor进行构建。ETensor 本身不拥有或分配内存。为了支持动态形状,内核可以使用客户端提供的 MemoryAllocator 来分配 Tensor 数据。
Portable kernels¶
Portable kernels 是为兼容 ETensor 而编写的运算符实现。由于 ETensor 与 at::Tensor 兼容,因此 portable kernels 可以针对 at::Tensor 构建,并在与 ATen kernels 相同的模型中使用。Portable kernels 是:
与 ATen 运算符签名兼容
用可移植的 C++ 编写,因此可以为任何目标构建
作为参考实现编写,优先考虑清晰性和简洁性而非优化
通常比 ATen kernels 体积小
编写时避免使用 new/malloc 进行动态内存分配。
Program¶
描述 ML 模型的一组代码和数据。
Program source code¶
描述程序的 Python 源代码。它可以是一个 Python 函数,或者 PyTorch 的 eager 模式 nn.Module 中的一个方法。
PTQ (Post Training Quantization)¶
一种量化技术,其中模型在训练后进行量化(通常是为了提高性能)。PTQ 在训练后应用量化流程,与 QAT(在训练期间应用)相反。
QAT (Quantization Aware Training)¶
量化后模型可能会损失精度。QAT 通过在训练期间模拟量化的影响,可以实现比 PTQ 等方法更高的精度。在训练期间,所有权重和激活都被“假量化”;浮点值被四舍五入以模仿 int8 值,但所有计算仍然以浮点数进行。因此,训练期间的所有权重调整都“意识”到模型最终将被量化。QAT 在训练期间应用量化流程,与 PTQ(在之后应用)相反。
Quantization¶
使用较低精度数据(通常是 int8)执行张量计算和内存访问的技术。量化通过降低内存使用量和(通常)减少计算延迟来提高模型性能;根据硬件,以较低精度进行的计算通常会更快,例如 int8 矩阵乘法与 fp32 矩阵乘法。通常,量化会以牺牲模型精度为代价。
Developer Tools¶
一组用户需要用于分析、调试和可视化正在使用 ExecuTorch 运行的程序的工具。
Selective build¶
一个 API,用于通过仅链接程序使用的内核来构建更精简的运行时。这可以显著节省二进制文件大小。
Static Quantization¶
一种量化方法,其中张量被静态量化。也就是说,在推理之前将浮点数转换为低精度数据类型。
