


注意
转到末尾 下载完整的示例代码。
训练一个玩马里奥的强化学习代理#
创建日期:2020 年 12 月 17 日 | 最后更新:2024 年 2 月 5 日 | 最后验证:未验证
作者: Yuansong Feng, Suraj Subramanian, Howard Wang, Steven Guo。
本教程将带您了解深度强化学习的基础知识。最后,您将实现一个能够自主玩游戏的、由 AI 驱动的马里奥(使用 双深度 Q 网络)。
虽然本教程不需要任何先验的 RL 知识,但您可以熟悉这些 RL 概念,并准备好这份 备忘单 作为您的助手。完整的代码可在 此处 获取。

%%bash
pip install gym-super-mario-bros==7.4.0
pip install tensordict==0.3.0
pip install torchrl==0.3.0
import torch
from torch import nn
from torchvision import transforms as T
from PIL import Image
import numpy as np
from pathlib import Path
from collections import deque
import random, datetime, os
# Gym is an OpenAI toolkit for RL
import gym
from gym.spaces import Box
from gym.wrappers import FrameStack
# NES Emulator for OpenAI Gym
from nes_py.wrappers import JoypadSpace
# Super Mario environment for OpenAI Gym
import gym_super_mario_bros
from tensordict import TensorDict
from torchrl.data import TensorDictReplayBuffer, LazyMemmapStorage
Gym has been unmaintained since 2022 and does not support NumPy 2.0 amongst other critical functionality.
Please upgrade to Gymnasium, the maintained drop-in replacement of Gym, or contact the authors of your software and request that they upgrade.
Users of this version of Gym should be able to simply replace 'import gym' with 'import gymnasium as gym' in the vast majority of cases.
See the migration guide at https://gymnasium.org.cn/introduction/migration_guide/ for additional information.
/usr/local/lib/python3.10/dist-packages/torchrl/__init__.py:43: UserWarning:
failed to set start method to spawn, and current start method for mp is fork.
RL 定义#
环境:代理与之交互并从中学习的世界。
动作 \(a\) :代理如何响应环境。所有可能动作的集合称为*动作空间*。
状态 \(s\) :环境的当前特征。环境可能处于的所有可能状态的集合称为*状态空间*。
奖励 \(r\) :奖励是环境给代理的关键反馈。它驱动代理学习并改变其未来的动作。多个时间步的奖励总和称为**回报**。
最优动作-值函数 \(Q^*(s,a)\) :给出从状态 \(s\) 开始,采取任意动作 \(a\),然后在每个未来时间步采取使回报最大化的动作时,预期的回报。可以说 \(Q\) 代表了状态下动作的“质量”。我们尝试逼近这个函数。
环境#
初始化环境#
在马里奥游戏中,环境由管道、蘑菇和其他组件组成。
当马里奥执行一个动作时,环境会响应以改变后的(下一个)状态、奖励和其他信息。
# Initialize Super Mario environment (in v0.26 change render mode to 'human' to see results on the screen)
if gym.__version__ < '0.26':
env = gym_super_mario_bros.make("SuperMarioBros-1-1-v0", new_step_api=True)
else:
env = gym_super_mario_bros.make("SuperMarioBros-1-1-v0", render_mode='rgb', apply_api_compatibility=True)
# Limit the action-space to
# 0. walk right
# 1. jump right
env = JoypadSpace(env, [["right"], ["right", "A"]])
env.reset()
next_state, reward, done, trunc, info = env.step(action=0)
print(f"{next_state.shape},\n {reward},\n {done},\n {info}")
/usr/local/lib/python3.10/dist-packages/gym/envs/registration.py:555: UserWarning:
WARN: The environment SuperMarioBros-1-1-v0 is out of date. You should consider upgrading to version `v3`.
/usr/local/lib/python3.10/dist-packages/gym/envs/registration.py:627: UserWarning:
WARN: The environment creator metadata doesn't include `render_modes`, contains: ['render.modes', 'video.frames_per_second']
/usr/local/lib/python3.10/dist-packages/gym/utils/passive_env_checker.py:233: DeprecationWarning:
`np.bool8` is a deprecated alias for `np.bool_`. (Deprecated NumPy 1.24)
(240, 256, 3),
0.0,
False,
{'coins': 0, 'flag_get': False, 'life': 2, 'score': 0, 'stage': 1, 'status': 'small', 'time': 400, 'world': 1, 'x_pos': 40, 'y_pos': 79}
预处理环境#
环境数据以 next_state 的形式返回给代理。如上所示,每个状态由一个大小为 [3, 240, 256] 的数组表示。通常,这比代理所需的信息多;例如,马里奥的动作不取决于管道或天空的颜色!
我们使用**包装器 (Wrappers)** 在将环境数据发送给代理之前对其进行预处理。
GrayScaleObservation 是一个常见的包装器,用于将 RGB 图像转换为灰度图像;这样做可以减小状态表示的大小,同时不丢失有用信息。现在每个状态的大小为:[1, 240, 256]。
ResizeObservation 将每个观察值缩小为方形图像。新大小:[1, 84, 84]。
SkipFrame 是一个自定义包装器,它继承自 gym.Wrapper 并实现了 step() 函数。由于连续帧的变化不大,我们可以跳过 n 帧而不丢失太多信息。第 n 帧聚合了每跳过帧累积的奖励。
FrameStack 是一个包装器,它允许我们将环境的连续帧压缩成一个单独的观察点,以馈送给我们的学习模型。这样,我们可以根据马里奥在过去几帧中的移动方向来判断他是在着陆还是在跳跃。
class SkipFrame(gym.Wrapper):
def __init__(self, env, skip):
"""Return only every `skip`-th frame"""
super().__init__(env)
self._skip = skip
def step(self, action):
"""Repeat action, and sum reward"""
total_reward = 0.0
for i in range(self._skip):
# Accumulate reward and repeat the same action
obs, reward, done, trunk, info = self.env.step(action)
total_reward += reward
if done:
break
return obs, total_reward, done, trunk, info
class GrayScaleObservation(gym.ObservationWrapper):
def __init__(self, env):
super().__init__(env)
obs_shape = self.observation_space.shape[:2]
self.observation_space = Box(low=0, high=255, shape=obs_shape, dtype=np.uint8)
def permute_orientation(self, observation):
# permute [H, W, C] array to [C, H, W] tensor
observation = np.transpose(observation, (2, 0, 1))
observation = torch.tensor(observation.copy(), dtype=torch.float)
return observation
def observation(self, observation):
observation = self.permute_orientation(observation)
transform = T.Grayscale()
observation = transform(observation)
return observation
class ResizeObservation(gym.ObservationWrapper):
def __init__(self, env, shape):
super().__init__(env)
if isinstance(shape, int):
self.shape = (shape, shape)
else:
self.shape = tuple(shape)
obs_shape = self.shape + self.observation_space.shape[2:]
self.observation_space = Box(low=0, high=255, shape=obs_shape, dtype=np.uint8)
def observation(self, observation):
transforms = T.Compose(
[T.Resize(self.shape, antialias=True), T.Normalize(0, 255)]
)
observation = transforms(observation).squeeze(0)
return observation
# Apply Wrappers to environment
env = SkipFrame(env, skip=4)
env = GrayScaleObservation(env)
env = ResizeObservation(env, shape=84)
if gym.__version__ < '0.26':
env = FrameStack(env, num_stack=4, new_step_api=True)
else:
env = FrameStack(env, num_stack=4)
将上述包装器应用于环境后,最终包装好的状态由 4 个堆叠在一起的连续灰度帧组成,如左侧图像所示。每次马里奥执行一个动作,环境都会响应一个具有此结构的状态。该结构由一个大小为 [4, 84, 84] 的 3D 数组表示。
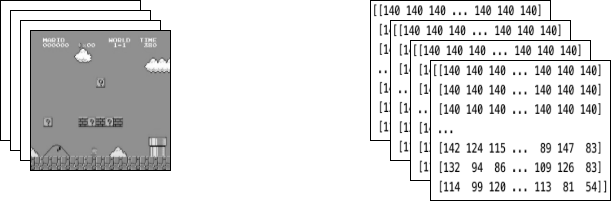
代理#
我们创建一个名为 Mario 的类来表示我们在游戏中的代理。马里奥应该能够
根据当前环境状态,基于最优动作策略**行动**(**Act**)。
**记住**经验。经验 =(当前状态,当前动作,奖励,下一个状态)。马里奥*缓存*并稍后*回忆*他的经验来更新他的动作策略。
随着时间的推移**学习**一个更好的动作策略。
class Mario:
def __init__():
pass
def act(self, state):
"""Given a state, choose an epsilon-greedy action"""
pass
def cache(self, experience):
"""Add the experience to memory"""
pass
def recall(self):
"""Sample experiences from memory"""
pass
def learn(self):
"""Update online action value (Q) function with a batch of experiences"""
pass
在接下来的部分,我们将填充马里奥的参数并定义他的函数。
行动#
对于任何给定的状态,代理可以选择执行最优动作(**利用**)或随机动作(**探索**)。
马里奥以 self.exploration_rate 的概率随机探索;当他选择利用时,他依赖 MarioNet(在 学习 部分实现)来提供最优动作。
class Mario:
def __init__(self, state_dim, action_dim, save_dir):
self.state_dim = state_dim
self.action_dim = action_dim
self.save_dir = save_dir
self.device = "cuda" if torch.cuda.is_available() else "cpu"
# Mario's DNN to predict the most optimal action - we implement this in the Learn section
self.net = MarioNet(self.state_dim, self.action_dim).float()
self.net = self.net.to(device=self.device)
self.exploration_rate = 1
self.exploration_rate_decay = 0.99999975
self.exploration_rate_min = 0.1
self.curr_step = 0
self.save_every = 5e5 # no. of experiences between saving Mario Net
def act(self, state):
"""
Given a state, choose an epsilon-greedy action and update value of step.
Inputs:
state(``LazyFrame``): A single observation of the current state, dimension is (state_dim)
Outputs:
``action_idx`` (``int``): An integer representing which action Mario will perform
"""
# EXPLORE
if np.random.rand() < self.exploration_rate:
action_idx = np.random.randint(self.action_dim)
# EXPLOIT
else:
state = state[0].__array__() if isinstance(state, tuple) else state.__array__()
state = torch.tensor(state, device=self.device).unsqueeze(0)
action_values = self.net(state, model="online")
action_idx = torch.argmax(action_values, axis=1).item()
# decrease exploration_rate
self.exploration_rate *= self.exploration_rate_decay
self.exploration_rate = max(self.exploration_rate_min, self.exploration_rate)
# increment step
self.curr_step += 1
return action_idx
缓存和回忆#
这两个函数充当了马里奥的“记忆”过程。
cache():每次马里奥执行一个动作时,他都会将*经验*存储到他的记忆中。他的经验包括当前的*状态*,执行的*动作*,该动作带来的*奖励*,*下一个状态*,以及游戏是否*结束*。
recall():马里奥从他的记忆中随机采样一批经验,并使用这些经验来学习游戏。
class Mario(Mario): # subclassing for continuity
def __init__(self, state_dim, action_dim, save_dir):
super().__init__(state_dim, action_dim, save_dir)
self.memory = TensorDictReplayBuffer(storage=LazyMemmapStorage(100000, device=torch.device("cpu")))
self.batch_size = 32
def cache(self, state, next_state, action, reward, done):
"""
Store the experience to self.memory (replay buffer)
Inputs:
state (``LazyFrame``),
next_state (``LazyFrame``),
action (``int``),
reward (``float``),
done(``bool``))
"""
def first_if_tuple(x):
return x[0] if isinstance(x, tuple) else x
state = first_if_tuple(state).__array__()
next_state = first_if_tuple(next_state).__array__()
state = torch.tensor(state)
next_state = torch.tensor(next_state)
action = torch.tensor([action])
reward = torch.tensor([reward])
done = torch.tensor([done])
# self.memory.append((state, next_state, action, reward, done,))
self.memory.add(TensorDict({"state": state, "next_state": next_state, "action": action, "reward": reward, "done": done}, batch_size=[]))
def recall(self):
"""
Retrieve a batch of experiences from memory
"""
batch = self.memory.sample(self.batch_size).to(self.device)
state, next_state, action, reward, done = (batch.get(key) for key in ("state", "next_state", "action", "reward", "done"))
return state, next_state, action.squeeze(), reward.squeeze(), done.squeeze()
学习#
马里奥在后台使用 DDQN 算法。DDQN 使用两个卷积神经网络 - \(Q_{online}\) 和 \(Q_{target}\) - 来独立逼近最优动作-值函数。
在我们的实现中,我们在 \(Q_{online}\) 和 \(Q_{target}\) 之间共享特征生成器 features,但为每个网络维护单独的全连接分类器。\(\theta_{target}\)(\(Q_{target}\) 的参数)被冻结以防止通过反向传播进行更新。相反,它会定期与 \(\theta_{online}\) 同步(稍后会详细介绍)。
神经网络#
class MarioNet(nn.Module):
"""mini CNN structure
input -> (conv2d + relu) x 3 -> flatten -> (dense + relu) x 2 -> output
"""
def __init__(self, input_dim, output_dim):
super().__init__()
c, h, w = input_dim
if h != 84:
raise ValueError(f"Expecting input height: 84, got: {h}")
if w != 84:
raise ValueError(f"Expecting input width: 84, got: {w}")
self.online = self.__build_cnn(c, output_dim)
self.target = self.__build_cnn(c, output_dim)
self.target.load_state_dict(self.online.state_dict())
# Q_target parameters are frozen.
for p in self.target.parameters():
p.requires_grad = False
def forward(self, input, model):
if model == "online":
return self.online(input)
elif model == "target":
return self.target(input)
def __build_cnn(self, c, output_dim):
return nn.Sequential(
nn.Conv2d(in_channels=c, out_channels=32, kernel_size=8, stride=4),
nn.ReLU(),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=4, stride=2),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1),
nn.ReLU(),
nn.Flatten(),
nn.Linear(3136, 512),
nn.ReLU(),
nn.Linear(512, output_dim),
)
TD 估计 & TD 目标#
学习涉及两个值:
TD 估计 - 给定状态 \(s\) 的预测最优 \(Q^*\)。
TD 目标 - 当前奖励与下一个状态 \(s'\) 中的估计 \(Q^*\) 的聚合。
由于我们不知道下一个动作 \(a'\) 是什么,我们使用最大化下一个状态 \(s'\) 中 \(Q_{online}\) 的动作 \(a'\)。
请注意,我们在 td_target() 上使用了 @torch.no_grad() 装饰器来禁用此处的梯度计算(因为我们不需要对 \(\theta_{target}\) 进行反向传播)。
class Mario(Mario):
def __init__(self, state_dim, action_dim, save_dir):
super().__init__(state_dim, action_dim, save_dir)
self.gamma = 0.9
def td_estimate(self, state, action):
current_Q = self.net(state, model="online")[
np.arange(0, self.batch_size), action
] # Q_online(s,a)
return current_Q
@torch.no_grad()
def td_target(self, reward, next_state, done):
next_state_Q = self.net(next_state, model="online")
best_action = torch.argmax(next_state_Q, axis=1)
next_Q = self.net(next_state, model="target")[
np.arange(0, self.batch_size), best_action
]
return (reward + (1 - done.float()) * self.gamma * next_Q).float()
更新模型#
当马里奥从其重放缓冲区采样输入时,我们计算 \(TD_t\) 和 \(TD_e\),并将此损失反向传播到 \(Q_{online}\) 以更新其参数 \(\theta_{online}\)(\(\alpha\) 是传递给 optimizer 的学习率 lr)。
\(\theta_{target}\) 不会通过反向传播进行更新。取而代之的是,我们定期将 \(\theta_{online}\) 复制到 \(\theta_{target}\)。
class Mario(Mario):
def __init__(self, state_dim, action_dim, save_dir):
super().__init__(state_dim, action_dim, save_dir)
self.optimizer = torch.optim.Adam(self.net.parameters(), lr=0.00025)
self.loss_fn = torch.nn.SmoothL1Loss()
def update_Q_online(self, td_estimate, td_target):
loss = self.loss_fn(td_estimate, td_target)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
return loss.item()
def sync_Q_target(self):
self.net.target.load_state_dict(self.net.online.state_dict())
保存检查点#
class Mario(Mario):
def save(self):
save_path = (
self.save_dir / f"mario_net_{int(self.curr_step // self.save_every)}.chkpt"
)
torch.save(
dict(model=self.net.state_dict(), exploration_rate=self.exploration_rate),
save_path,
)
print(f"MarioNet saved to {save_path} at step {self.curr_step}")
整合所有内容#
class Mario(Mario):
def __init__(self, state_dim, action_dim, save_dir):
super().__init__(state_dim, action_dim, save_dir)
self.burnin = 1e4 # min. experiences before training
self.learn_every = 3 # no. of experiences between updates to Q_online
self.sync_every = 1e4 # no. of experiences between Q_target & Q_online sync
def learn(self):
if self.curr_step % self.sync_every == 0:
self.sync_Q_target()
if self.curr_step % self.save_every == 0:
self.save()
if self.curr_step < self.burnin:
return None, None
if self.curr_step % self.learn_every != 0:
return None, None
# Sample from memory
state, next_state, action, reward, done = self.recall()
# Get TD Estimate
td_est = self.td_estimate(state, action)
# Get TD Target
td_tgt = self.td_target(reward, next_state, done)
# Backpropagate loss through Q_online
loss = self.update_Q_online(td_est, td_tgt)
return (td_est.mean().item(), loss)
日志记录#
import numpy as np
import time, datetime
import matplotlib.pyplot as plt
class MetricLogger:
def __init__(self, save_dir):
self.save_log = save_dir / "log"
with open(self.save_log, "w") as f:
f.write(
f"{'Episode':>8}{'Step':>8}{'Epsilon':>10}{'MeanReward':>15}"
f"{'MeanLength':>15}{'MeanLoss':>15}{'MeanQValue':>15}"
f"{'TimeDelta':>15}{'Time':>20}\n"
)
self.ep_rewards_plot = save_dir / "reward_plot.jpg"
self.ep_lengths_plot = save_dir / "length_plot.jpg"
self.ep_avg_losses_plot = save_dir / "loss_plot.jpg"
self.ep_avg_qs_plot = save_dir / "q_plot.jpg"
# History metrics
self.ep_rewards = []
self.ep_lengths = []
self.ep_avg_losses = []
self.ep_avg_qs = []
# Moving averages, added for every call to record()
self.moving_avg_ep_rewards = []
self.moving_avg_ep_lengths = []
self.moving_avg_ep_avg_losses = []
self.moving_avg_ep_avg_qs = []
# Current episode metric
self.init_episode()
# Timing
self.record_time = time.time()
def log_step(self, reward, loss, q):
self.curr_ep_reward += reward
self.curr_ep_length += 1
if loss:
self.curr_ep_loss += loss
self.curr_ep_q += q
self.curr_ep_loss_length += 1
def log_episode(self):
"Mark end of episode"
self.ep_rewards.append(self.curr_ep_reward)
self.ep_lengths.append(self.curr_ep_length)
if self.curr_ep_loss_length == 0:
ep_avg_loss = 0
ep_avg_q = 0
else:
ep_avg_loss = np.round(self.curr_ep_loss / self.curr_ep_loss_length, 5)
ep_avg_q = np.round(self.curr_ep_q / self.curr_ep_loss_length, 5)
self.ep_avg_losses.append(ep_avg_loss)
self.ep_avg_qs.append(ep_avg_q)
self.init_episode()
def init_episode(self):
self.curr_ep_reward = 0.0
self.curr_ep_length = 0
self.curr_ep_loss = 0.0
self.curr_ep_q = 0.0
self.curr_ep_loss_length = 0
def record(self, episode, epsilon, step):
mean_ep_reward = np.round(np.mean(self.ep_rewards[-100:]), 3)
mean_ep_length = np.round(np.mean(self.ep_lengths[-100:]), 3)
mean_ep_loss = np.round(np.mean(self.ep_avg_losses[-100:]), 3)
mean_ep_q = np.round(np.mean(self.ep_avg_qs[-100:]), 3)
self.moving_avg_ep_rewards.append(mean_ep_reward)
self.moving_avg_ep_lengths.append(mean_ep_length)
self.moving_avg_ep_avg_losses.append(mean_ep_loss)
self.moving_avg_ep_avg_qs.append(mean_ep_q)
last_record_time = self.record_time
self.record_time = time.time()
time_since_last_record = np.round(self.record_time - last_record_time, 3)
print(
f"Episode {episode} - "
f"Step {step} - "
f"Epsilon {epsilon} - "
f"Mean Reward {mean_ep_reward} - "
f"Mean Length {mean_ep_length} - "
f"Mean Loss {mean_ep_loss} - "
f"Mean Q Value {mean_ep_q} - "
f"Time Delta {time_since_last_record} - "
f"Time {datetime.datetime.now().strftime('%Y-%m-%dT%H:%M:%S')}"
)
with open(self.save_log, "a") as f:
f.write(
f"{episode:8d}{step:8d}{epsilon:10.3f}"
f"{mean_ep_reward:15.3f}{mean_ep_length:15.3f}{mean_ep_loss:15.3f}{mean_ep_q:15.3f}"
f"{time_since_last_record:15.3f}"
f"{datetime.datetime.now().strftime('%Y-%m-%dT%H:%M:%S'):>20}\n"
)
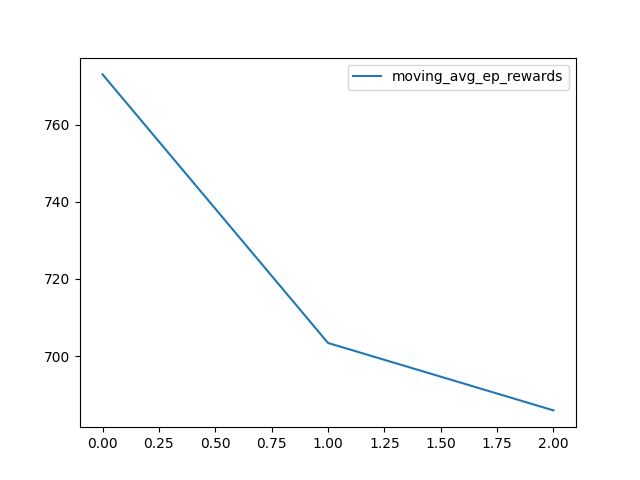
for metric in ["ep_lengths", "ep_avg_losses", "ep_avg_qs", "ep_rewards"]:
plt.clf()
plt.plot(getattr(self, f"moving_avg_{metric}"), label=f"moving_avg_{metric}")
plt.legend()
plt.savefig(getattr(self, f"{metric}_plot"))
让我们开始玩吧!#
在此示例中,我们运行了 40 个训练回合,但要让马里奥真正掌握他的世界,我们建议至少运行 40,000 个回合!
use_cuda = torch.cuda.is_available()
print(f"Using CUDA: {use_cuda}")
print()
save_dir = Path("checkpoints") / datetime.datetime.now().strftime("%Y-%m-%dT%H-%M-%S")
save_dir.mkdir(parents=True)
mario = Mario(state_dim=(4, 84, 84), action_dim=env.action_space.n, save_dir=save_dir)
logger = MetricLogger(save_dir)
episodes = 40
for e in range(episodes):
state = env.reset()
# Play the game!
while True:
# Run agent on the state
action = mario.act(state)
# Agent performs action
next_state, reward, done, trunc, info = env.step(action)
# Remember
mario.cache(state, next_state, action, reward, done)
# Learn
q, loss = mario.learn()
# Logging
logger.log_step(reward, loss, q)
# Update state
state = next_state
# Check if end of game
if done or info["flag_get"]:
break
logger.log_episode()
if (e % 20 == 0) or (e == episodes - 1):
logger.record(episode=e, epsilon=mario.exploration_rate, step=mario.curr_step)
Using CUDA: True
Episode 0 - Step 298 - Epsilon 0.9999255027657337 - Mean Reward 784.0 - Mean Length 298.0 - Mean Loss 0.0 - Mean Q Value 0.0 - Time Delta 2.485 - Time 2025-10-15T19:20:04
Episode 20 - Step 5462 - Epsilon 0.9986354317002756 - Mean Reward 692.857 - Mean Length 260.095 - Mean Loss 0.0 - Mean Q Value 0.0 - Time Delta 43.663 - Time 2025-10-15T19:20:48
Episode 39 - Step 9038 - Epsilon 0.9977430504665065 - Mean Reward 659.85 - Mean Length 225.95 - Mean Loss 0.0 - Mean Q Value 0.0 - Time Delta 30.074 - Time 2025-10-15T19:21:18
结论#
在本教程中,我们了解了如何使用 PyTorch 训练一个游戏 AI。您可以使用相同的方法训练一个 AI 来玩 OpenAI Gym 中的任何游戏。希望您喜欢本教程,欢迎随时通过 我们的 GitHub 与我们联系!
脚本总运行时间: (1 分钟 17.340 秒)
