


注意
转到末尾 下载完整的示例代码。
强化学习(PPO)使用 TorchRL 教程#
创建日期:2023 年 3 月 15 日 | 最后更新:2025 年 9 月 17 日 | 最后验证:2024 年 11 月 5 日
本教程演示了如何使用 PyTorch 和 torchrl 训练参数化策略网络,以解决 OpenAI-Gym/Farama-Gymnasium 控制库中的倒立摆任务。

倒立摆#
主要学习内容
如何在 TorchRL 中创建环境,转换其输出,并从该环境中收集数据;
如何使用
TensorDict让您的类之间进行通信;使用 TorchRL 构建训练循环的基础知识
如何为策略梯度方法计算优势信号;
如何使用概率神经网络创建随机策略;
如何创建动态回放缓冲区并从中不重复地采样。
我们将介绍 TorchRL 的六个关键组件
如果您在 Google Colab 中运行此代码,请确保安装以下依赖项
!pip3 install torchrl
!pip3 install gym[mujoco]
!pip3 install tqdm
近端策略优化(PPO)是一种策略梯度算法,它收集并直接消耗一批数据,以在存在某些近端约束的情况下最大化预期回报来训练策略。您可以将其视为 REINFORCE(基础策略优化算法)的复杂版本。有关更多信息,请参阅 近端策略优化算法论文。
PPO 通常被认为是一种快速有效的在线、on-policy 强化算法。TorchRL 提供了一个为您完成所有工作的损失模块,这样您就可以依赖此实现,专注于解决您的问题,而不是每次想训练策略时都重新发明轮子。
为了完整起见,这里简要概述了损失的计算方法,尽管这由我们的 ClipPPOLoss 模块处理—算法如下:1. 我们将通过在环境中运行策略一定步数来采样一批数据。2. 然后,我们将使用裁剪版的 REINFORCE 损失,通过随机子批次对该批次进行一定次数的优化。3. 裁剪将对我们的损失设置一个悲观的界限:与更高的回报估计相比,更低的回报估计将受到青睐。损失的精确公式是
该损失中有两个组成部分:在最小算子第一部分,我们计算了 REINFORCE 损失的加权版本(例如,我们已根据当前策略配置滞后于用于数据收集的配置的事实进行了校正的 REINFORCE 损失)。该最小算子的第二部分是一个类似的损失,我们在其中裁剪了超出或低于给定阈值对的比例。
此损失确保无论优势是正数还是负数,都会抑制那些会导致与先前配置发生重大偏移的策略更新。
本教程结构如下
首先,我们将定义一组将在训练中使用的超参数。
接下来,我们将专注于使用 TorchRL 的包装器和变换来创建我们的环境或模拟器。
接下来,我们将设计策略网络和价值模型,这对于损失函数是必不可少的。这些模块将用于配置我们的损失模块。
接下来,我们将创建回放缓冲区和数据加载器。
最后,我们将运行训练循环并分析结果。
在本教程中,我们将使用 tensordict 库。TensorDict 是 TorchRL 的通用语言:它帮助我们抽象出模块读取和写入的内容,让我们更少关注具体的数据描述,而更多关注算法本身。
import warnings
warnings.filterwarnings("ignore")
from torch import multiprocessing
from collections import defaultdict
import matplotlib.pyplot as plt
import torch
from tensordict.nn import TensorDictModule
from tensordict.nn.distributions import NormalParamExtractor
from torch import nn
from torchrl.collectors import SyncDataCollector
from torchrl.data.replay_buffers import ReplayBuffer
from torchrl.data.replay_buffers.samplers import SamplerWithoutReplacement
from torchrl.data.replay_buffers.storages import LazyTensorStorage
from torchrl.envs import (Compose, DoubleToFloat, ObservationNorm, StepCounter,
TransformedEnv)
from torchrl.envs.libs.gym import GymEnv
from torchrl.envs.utils import check_env_specs, ExplorationType, set_exploration_type
from torchrl.modules import ProbabilisticActor, TanhNormal, ValueOperator
from torchrl.objectives import ClipPPOLoss
from torchrl.objectives.value import GAE
from tqdm import tqdm
定义超参数#
我们为算法设置了超参数。根据可用资源,可以选择在 GPU 或其他设备上执行策略。frame_skip 将控制单个动作执行多少帧。其余计算帧数的参数必须针对此值进行校正(因为一个环境步骤实际上将返回 frame_skip 帧)。
is_fork = multiprocessing.get_start_method() == "fork"
device = (
torch.device(0)
if torch.cuda.is_available() and not is_fork
else torch.device("cpu")
)
num_cells = 256 # number of cells in each layer i.e. output dim.
lr = 3e-4
max_grad_norm = 1.0
数据收集参数#
在收集数据时,我们将能够通过定义 frames_per_batch 参数来选择每个批次的大小。我们还将定义允许使用的帧数(例如与模拟器的交互次数)。一般来说,RL 算法的目标是学会尽快解决任务(就环境交互而言):total_frames 越低越好。
frames_per_batch = 1000
# For a complete training, bring the number of frames up to 1M
total_frames = 50_000
PPO 参数#
在每次数据收集(或批次收集)时,我们将在一定数量的“epoch”上运行优化,每次都通过内部训练循环消耗我们刚刚获取的全部数据。这里,sub_batch_size 与上面的 frames_per_batch 不同:请记住,我们正在处理来自收集器的“批次数据”,其大小由 frames_per_batch 定义,并且我们将在内部训练循环中将其进一步划分为更小的子批次。这些子批次的大小由 sub_batch_size 控制。
sub_batch_size = 64 # cardinality of the sub-samples gathered from the current data in the inner loop
num_epochs = 10 # optimization steps per batch of data collected
clip_epsilon = (
0.2 # clip value for PPO loss: see the equation in the intro for more context.
)
gamma = 0.99
lmbda = 0.95
entropy_eps = 1e-4
定义环境#
在 RL 中,*环境* 通常是我们对模拟器或控制系统的称呼。各种库都提供强化学习的模拟环境,包括 Gymnasium(以前称为 OpenAI Gym)、DeepMind 控制套件等。作为一个通用库,TorchRL 的目标是为大量 RL 模拟器提供可互换的接口,让您轻松地将一个环境替换为另一个。例如,使用几个字符就可以创建一个包装好的 gym 环境。
Gym has been unmaintained since 2022 and does not support NumPy 2.0 amongst other critical functionality.
Please upgrade to Gymnasium, the maintained drop-in replacement of Gym, or contact the authors of your software and request that they upgrade.
Users of this version of Gym should be able to simply replace 'import gym' with 'import gymnasium as gym' in the vast majority of cases.
See the migration guide at https://gymnasium.org.cn/introduction/migration_guide/ for additional information.
这段代码有几点需要注意:首先,我们通过调用 GymEnv 包装器来创建环境。如果传递了额外的关键字参数,它们将被传输到 gym.make 方法,从而涵盖最常见的环境创建命令。或者,您也可以直接使用 gym.make(env_name, **kwargs) 创建一个 gym 环境,并将其包装在 GymWrapper 类中。
还有 device 参数:对于 gym,这仅控制存储输入动作和观察状态的设备,但执行始终在 CPU 上进行。原因很简单,gym 不支持设备上执行,除非另有说明。对于其他库,我们可以控制执行设备,并且在可能的情况下,我们会尽量在存储和执行后端方面保持一致。
转换#
我们将向环境添加一些变换,以准备好策略的数据。在 Gym 中,这通常通过包装器实现。TorchRL 采用不同的方法,更类似于其他 PyTorch 领域库,通过使用变换。要向环境添加变换,只需将其包装在 TransformedEnv 实例中,并将其变换序列附加到其中。转换后的环境将继承被包装环境的设备和元数据,并根据其包含的变换序列对其进行转换。
归一化#
首先编码的是一个归一化变换。经验法则,最好使数据大致匹配单位高斯分布:为了实现这一点,我们将执行一定数量的随机步骤,并计算这些观察的统计摘要。
我们将附加另外两个变换:DoubleToFloat 变换会将双精度条目转换为单精度数字,以便策略读取。StepCounter 变换将用于计算环境终止之前的步数。我们将使用此度量作为补充性能度量。
正如我们稍后将看到的,TorchRL 的许多类依赖于 TensorDict 进行通信。您可以将其视为具有一些额外张量功能的 Python 字典。在实践中,这意味着我们将处理的许多模块需要被告知要读取什么键(in_keys)以及在它们将接收的 tensordict 中写入什么键(out_keys)。通常,如果省略 out_keys,则假定 in_keys 条目将被原地更新。对于我们的变换,我们感兴趣的唯一条目是 "observation",我们的变换层将被告知修改此条目,仅此而已。
env = TransformedEnv(
base_env,
Compose(
# normalize observations
ObservationNorm(in_keys=["observation"]),
DoubleToFloat(),
StepCounter(),
),
)
您可能已经注意到,我们创建了一个归一化层,但没有设置其归一化参数。要做到这一点,ObservationNorm 可以自动收集我们环境的统计摘要。
env.transform[0].init_stats(num_iter=1000, reduce_dim=0, cat_dim=0)
现在,ObservationNorm 变换已填充了用于归一化数据的均值和方差。
让我们对我们的统计摘要的形状进行一些健全性检查。
print("normalization constant shape:", env.transform[0].loc.shape)
normalization constant shape: torch.Size([11])
环境不仅由其模拟器和变换定义,还由一系列元数据定义,这些元数据描述了在执行期间可以预期什么。出于效率原因,TorchRL 在环境规范方面非常严格,但您可以轻松检查您的环境规范是否足够。在我们的示例中,GymWrapper 和继承自它的 GymEnv 已经负责为您的环境设置正确的规范,所以您不必担心这一点。
不过,让我们通过查看转换后的环境的规范来具体看一下。有三个规范需要查看:observation_spec 定义了在环境中执行动作时可以预期什么,reward_spec 指示了奖励域,最后是 input_spec(其中包含 action_spec),它代表了环境执行单个步骤所需的一切。
print("observation_spec:", env.observation_spec)
print("reward_spec:", env.reward_spec)
print("input_spec:", env.input_spec)
print("action_spec (as defined by input_spec):", env.action_spec)
observation_spec: Composite(
observation: UnboundedContinuous(
shape=torch.Size([11]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([11]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([11]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
step_count: BoundedDiscrete(
shape=torch.Size([1]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.int64, contiguous=True),
high=Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.int64, contiguous=True)),
device=cpu,
dtype=torch.int64,
domain=discrete),
device=cpu,
shape=torch.Size([]),
data_cls=None)
reward_spec: UnboundedContinuous(
shape=torch.Size([1]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous)
input_spec: Composite(
full_state_spec: Composite(
step_count: BoundedDiscrete(
shape=torch.Size([1]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.int64, contiguous=True),
high=Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.int64, contiguous=True)),
device=cpu,
dtype=torch.int64,
domain=discrete),
device=cpu,
shape=torch.Size([]),
data_cls=None),
full_action_spec: Composite(
action: BoundedContinuous(
shape=torch.Size([1]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
device=cpu,
shape=torch.Size([]),
data_cls=None),
device=cpu,
shape=torch.Size([]),
data_cls=None)
action_spec (as defined by input_spec): BoundedContinuous(
shape=torch.Size([1]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous)
该 check_env_specs() 函数运行一个小的回滚,并将其输出与环境规范进行比较。如果没有引发错误,我们可以确信规范已正确定义。
2025-10-15 19:17:32,789 [torchrl][INFO] check_env_specs succeeded! [END]
为了好玩,让我们看看简单的随机回滚是什么样的。您可以调用 env.rollout(n_steps) 并获取环境输入和输出的概览。动作将自动从动作规范域中抽取,因此您不必担心设计一个随机采样器。
通常,在每一步,RL 环境都会接收一个动作作为输入,并输出一个观察、一个奖励和一个完成状态。观察可能是复合的,这意味着它可能由多个张量组成。这对于 TorchRL 来说不是问题,因为整个观察集会自动打包到输出的 TensorDict 中。在执行完给定步数的回滚(例如,一系列环境步骤和随机动作生成)后,我们将检索一个 TensorDict 实例,其形状与此轨迹长度匹配。
rollout = env.rollout(3)
print("rollout of three steps:", rollout)
print("Shape of the rollout TensorDict:", rollout.batch_size)
rollout of three steps: TensorDict(
fields={
action: Tensor(shape=torch.Size([3, 1]), device=cpu, dtype=torch.float32, is_shared=False),
done: Tensor(shape=torch.Size([3, 1]), device=cpu, dtype=torch.bool, is_shared=False),
next: TensorDict(
fields={
done: Tensor(shape=torch.Size([3, 1]), device=cpu, dtype=torch.bool, is_shared=False),
observation: Tensor(shape=torch.Size([3, 11]), device=cpu, dtype=torch.float32, is_shared=False),
reward: Tensor(shape=torch.Size([3, 1]), device=cpu, dtype=torch.float32, is_shared=False),
step_count: Tensor(shape=torch.Size([3, 1]), device=cpu, dtype=torch.int64, is_shared=False),
terminated: Tensor(shape=torch.Size([3, 1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([3, 1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([3]),
device=cpu,
is_shared=False),
observation: Tensor(shape=torch.Size([3, 11]), device=cpu, dtype=torch.float32, is_shared=False),
step_count: Tensor(shape=torch.Size([3, 1]), device=cpu, dtype=torch.int64, is_shared=False),
terminated: Tensor(shape=torch.Size([3, 1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([3, 1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([3]),
device=cpu,
is_shared=False)
Shape of the rollout TensorDict: torch.Size([3])
我们的回滚数据的形状为 torch.Size([3]),这与我们运行它的步数相符。"next" 条目指向当前步骤之后的数据。在大多数情况下,时间 t 的 "next" 数据与 t+1 的数据匹配,但如果我们使用某些特定变换(例如,多步),则情况可能并非如此。
策略#
PPO 使用随机策略来处理探索。这意味着我们的神经网络将必须输出分布的参数,而不是对应于所采取动作的单个值。
由于数据是连续的,我们使用 Tanh-Normal 分布来尊重动作空间边界。TorchRL 提供了这种分布,我们只需要关心构建一个输出正确数量参数的神经网络,以便策略可以与之配合(均值和方差)。
这里唯一的额外难点是将我们的输出分成两部分,并将第二部分映射到严格正的空间。
我们分三个步骤设计策略
定义一个神经网络
D_obs->2 * D_action。确实,我们的loc(均值)和scale(方差)的维度都是D_action。附加一个
NormalParamExtractor以提取均值和方差(例如,将输入分成两部分,并对方差参数应用正变换)。创建一个概率性的
TensorDictModule,它可以生成此分布并从中采样。
actor_net = nn.Sequential(
nn.LazyLinear(num_cells, device=device),
nn.Tanh(),
nn.LazyLinear(num_cells, device=device),
nn.Tanh(),
nn.LazyLinear(num_cells, device=device),
nn.Tanh(),
nn.LazyLinear(2 * env.action_spec.shape[-1], device=device),
NormalParamExtractor(),
)
为了使策略能够通过 tensordict 数据载体与环境“交流”,我们将 nn.Module 包装在 TensorDictModule 中。此类将简单地读取其提供的 in_keys,并将输出原地写入已注册的 out_keys。
policy_module = TensorDictModule(
actor_net, in_keys=["observation"], out_keys=["loc", "scale"]
)
现在我们需要从我们的正态分布的均值和方差构建一个分布。为此,我们指示 ProbabilisticActor 类从均值和方差参数构建一个 TanhNormal。我们还提供了此分布的最小值和最大值,这些值是从环境规范中获取的。
in_keys 的名称(因此也是上面 TensorDictModule 的 out_keys 的名称)不能随意设置,因为 TanhNormal 分布构造函数将期望 loc 和 scale 关键字参数。话虽如此,ProbabilisticActor 还接受 Dict[str, str] 类型的 in_keys,其中键值对指示了将用于每个要使用的关键字参数的 in_key 字符串。
policy_module = ProbabilisticActor(
module=policy_module,
spec=env.action_spec,
in_keys=["loc", "scale"],
distribution_class=TanhNormal,
distribution_kwargs={
"low": env.action_spec.space.low,
"high": env.action_spec.space.high,
},
return_log_prob=True,
# we'll need the log-prob for the numerator of the importance weights
)
价值网络#
价值网络是 PPO 算法的关键组成部分,尽管它不会在推理时使用。此模块将读取观察值并返回后续轨迹的折扣回报估计。这允许我们依赖在训练期间即时学习的效用估计来分摊学习成本。我们的价值网络与策略具有相同的结构,但为简单起见,我们为其分配了自己的一组参数。
value_net = nn.Sequential(
nn.LazyLinear(num_cells, device=device),
nn.Tanh(),
nn.LazyLinear(num_cells, device=device),
nn.Tanh(),
nn.LazyLinear(num_cells, device=device),
nn.Tanh(),
nn.LazyLinear(1, device=device),
)
value_module = ValueOperator(
module=value_net,
in_keys=["observation"],
)
让我们试试我们的策略和价值模块。如前所述,TensorDictModule 的使用使得可以直接读取环境的输出来运行这些模块,因为它们知道要读取哪些信息以及在哪里写入。
print("Running policy:", policy_module(env.reset()))
print("Running value:", value_module(env.reset()))
Running policy: TensorDict(
fields={
action: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, is_shared=False),
action_log_prob: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
loc: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, is_shared=False),
observation: Tensor(shape=torch.Size([11]), device=cpu, dtype=torch.float32, is_shared=False),
scale: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, is_shared=False),
step_count: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.int64, is_shared=False),
terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([]),
device=cpu,
is_shared=False)
Running value: TensorDict(
fields={
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
observation: Tensor(shape=torch.Size([11]), device=cpu, dtype=torch.float32, is_shared=False),
state_value: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, is_shared=False),
step_count: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.int64, is_shared=False),
terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([]),
device=cpu,
is_shared=False)
数据收集器#
TorchRL 提供了一组 数据收集器类。简而言之,这些类执行三个操作:重置环境,根据最新观察计算动作,在环境中执行一步,然后重复最后两个步骤,直到环境发出停止信号(或达到完成状态)。
它们允许您控制每次迭代收集多少帧(通过 frames_per_batch 参数),何时重置环境(通过 max_frames_per_traj 参数),策略应该在哪个 device 上执行,等等。它们还设计为与批处理和多进程环境高效配合。
最简单的数据收集器是 SyncDataCollector:它是一个迭代器,您可以用来获取指定长度的数据批次,并在收集完总帧数(total_frames)后停止。其他数据收集器(MultiSyncDataCollector 和 MultiaSyncDataCollector)将在多个进程的计算节点上以同步和异步方式执行相同的操作。
与之前的策略和环境一样,数据收集器将返回 TensorDict 实例,其总元素数量将匹配 frames_per_batch。使用 TensorDict 将数据传递给训练循环,允许您编写 100% 忽略回滚内容实际特异性的数据加载管道。
collector = SyncDataCollector(
env,
policy_module,
frames_per_batch=frames_per_batch,
total_frames=total_frames,
split_trajs=False,
device=device,
)
回放缓冲区#
回放缓冲区是离策略 RL 算法的常见构建模块。在策略环境中,每当收集一批数据时,回放缓冲区就会被重新填充,并且其数据会在一定数量的 epoch 中被重复消耗。
TorchRL 的回放缓冲区是使用通用的容器 ReplayBuffer 构建的,它接受缓冲区组件作为参数:存储、写入器、采样器以及可能的变换。只有存储(指示回放缓冲区容量)是强制性的。我们还指定了一个无重复采样器,以避免在一个 epoch 中多次采样同一个项目。使用回放缓冲区进行 PPO 不是强制性的,我们可以直接从收集的批次中采样子批次,但使用这些类可以方便我们以可重现的方式构建内部训练循环。
replay_buffer = ReplayBuffer(
storage=LazyTensorStorage(max_size=frames_per_batch),
sampler=SamplerWithoutReplacement(),
)
损失函数#
PPO 损失可以直接从 TorchRL 导入,以方便地使用 ClipPPOLoss 类。这是使用 PPO 最简单的方法:它隐藏了 PPO 的数学运算以及与之相关的控制流。
PPO 需要计算一些“优势估计”。简而言之,优势是一个值,它反映了在处理偏差/方差权衡时对回报值的预期。要计算优势,只需(1)构建优势模块,该模块利用我们的价值运算符,(2)在每个 epoch 之前将每个数据批次通过它。GAE 模块将使用新的 "advantage" 和 "value_target" 条目更新输入的 tensordict。"value_target" 是一个无梯度张量,表示价值网络应以输入观察值表示的经验值。这两者都将由 ClipPPOLoss 用于返回策略和价值损失。
advantage_module = GAE(
gamma=gamma, lmbda=lmbda, value_network=value_module, average_gae=True, device=device,
)
loss_module = ClipPPOLoss(
actor_network=policy_module,
critic_network=value_module,
clip_epsilon=clip_epsilon,
entropy_bonus=bool(entropy_eps),
entropy_coef=entropy_eps,
# these keys match by default but we set this for completeness
critic_coef=1.0,
loss_critic_type="smooth_l1",
)
optim = torch.optim.Adam(loss_module.parameters(), lr)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
optim, total_frames // frames_per_batch, 0.0
)
/usr/local/lib/python3.10/dist-packages/torchrl/objectives/ppo.py:384: DeprecationWarning:
'critic_coef' is deprecated and will be removed in torchrl v0.11. Please use 'critic_coeff' instead.
/usr/local/lib/python3.10/dist-packages/torchrl/objectives/ppo.py:450: DeprecationWarning:
'entropy_coef' is deprecated and will be removed in torchrl v0.11. Please use 'entropy_coeff' instead.
训练循环#
现在我们有了编写训练循环所需的所有组件。步骤包括
收集数据
计算优势
循环遍历收集的数据以计算损失值
反向传播
优化
重复
重复
重复
logs = defaultdict(list)
pbar = tqdm(total=total_frames)
eval_str = ""
# We iterate over the collector until it reaches the total number of frames it was
# designed to collect:
for i, tensordict_data in enumerate(collector):
# we now have a batch of data to work with. Let's learn something from it.
for _ in range(num_epochs):
# We'll need an "advantage" signal to make PPO work.
# We re-compute it at each epoch as its value depends on the value
# network which is updated in the inner loop.
advantage_module(tensordict_data)
data_view = tensordict_data.reshape(-1)
replay_buffer.extend(data_view.cpu())
for _ in range(frames_per_batch // sub_batch_size):
subdata = replay_buffer.sample(sub_batch_size)
loss_vals = loss_module(subdata.to(device))
loss_value = (
loss_vals["loss_objective"]
+ loss_vals["loss_critic"]
+ loss_vals["loss_entropy"]
)
# Optimization: backward, grad clipping and optimization step
loss_value.backward()
# this is not strictly mandatory but it's good practice to keep
# your gradient norm bounded
torch.nn.utils.clip_grad_norm_(loss_module.parameters(), max_grad_norm)
optim.step()
optim.zero_grad()
logs["reward"].append(tensordict_data["next", "reward"].mean().item())
pbar.update(tensordict_data.numel())
cum_reward_str = (
f"average reward={logs['reward'][-1]: 4.4f} (init={logs['reward'][0]: 4.4f})"
)
logs["step_count"].append(tensordict_data["step_count"].max().item())
stepcount_str = f"step count (max): {logs['step_count'][-1]}"
logs["lr"].append(optim.param_groups[0]["lr"])
lr_str = f"lr policy: {logs['lr'][-1]: 4.4f}"
if i % 10 == 0:
# We evaluate the policy once every 10 batches of data.
# Evaluation is rather simple: execute the policy without exploration
# (take the expected value of the action distribution) for a given
# number of steps (1000, which is our ``env`` horizon).
# The ``rollout`` method of the ``env`` can take a policy as argument:
# it will then execute this policy at each step.
with set_exploration_type(ExplorationType.DETERMINISTIC), torch.no_grad():
# execute a rollout with the trained policy
eval_rollout = env.rollout(1000, policy_module)
logs["eval reward"].append(eval_rollout["next", "reward"].mean().item())
logs["eval reward (sum)"].append(
eval_rollout["next", "reward"].sum().item()
)
logs["eval step_count"].append(eval_rollout["step_count"].max().item())
eval_str = (
f"eval cumulative reward: {logs['eval reward (sum)'][-1]: 4.4f} "
f"(init: {logs['eval reward (sum)'][0]: 4.4f}), "
f"eval step-count: {logs['eval step_count'][-1]}"
)
del eval_rollout
pbar.set_description(", ".join([eval_str, cum_reward_str, stepcount_str, lr_str]))
# We're also using a learning rate scheduler. Like the gradient clipping,
# this is a nice-to-have but nothing necessary for PPO to work.
scheduler.step()
0%| | 0/50000 [00:00<?, ?it/s]
2%|▏ | 1000/50000 [00:03<02:37, 310.41it/s]
eval cumulative reward: 82.8892 (init: 82.8892), eval step-count: 8, average reward= 9.0941 (init= 9.0941), step count (max): 14, lr policy: 0.0003: 2%|▏ | 1000/50000 [00:03<02:37, 310.41it/s]
eval cumulative reward: 82.8892 (init: 82.8892), eval step-count: 8, average reward= 9.0941 (init= 9.0941), step count (max): 14, lr policy: 0.0003: 4%|▍ | 2000/50000 [00:06<02:25, 330.59it/s]
eval cumulative reward: 82.8892 (init: 82.8892), eval step-count: 8, average reward= 9.1147 (init= 9.0941), step count (max): 14, lr policy: 0.0003: 4%|▍ | 2000/50000 [00:06<02:25, 330.59it/s]
eval cumulative reward: 82.8892 (init: 82.8892), eval step-count: 8, average reward= 9.1147 (init= 9.0941), step count (max): 14, lr policy: 0.0003: 6%|▌ | 3000/50000 [00:08<02:18, 339.71it/s]
eval cumulative reward: 82.8892 (init: 82.8892), eval step-count: 8, average reward= 9.1557 (init= 9.0941), step count (max): 17, lr policy: 0.0003: 6%|▌ | 3000/50000 [00:08<02:18, 339.71it/s]
eval cumulative reward: 82.8892 (init: 82.8892), eval step-count: 8, average reward= 9.1557 (init= 9.0941), step count (max): 17, lr policy: 0.0003: 8%|▊ | 4000/50000 [00:11<02:13, 344.80it/s]
eval cumulative reward: 82.8892 (init: 82.8892), eval step-count: 8, average reward= 9.1727 (init= 9.0941), step count (max): 22, lr policy: 0.0003: 8%|▊ | 4000/50000 [00:11<02:13, 344.80it/s]
eval cumulative reward: 82.8892 (init: 82.8892), eval step-count: 8, average reward= 9.1727 (init= 9.0941), step count (max): 22, lr policy: 0.0003: 10%|█ | 5000/50000 [00:14<02:08, 348.84it/s]
eval cumulative reward: 82.8892 (init: 82.8892), eval step-count: 8, average reward= 9.2145 (init= 9.0941), step count (max): 27, lr policy: 0.0003: 10%|█ | 5000/50000 [00:14<02:08, 348.84it/s]
eval cumulative reward: 82.8892 (init: 82.8892), eval step-count: 8, average reward= 9.2145 (init= 9.0941), step count (max): 27, lr policy: 0.0003: 12%|█▏ | 6000/50000 [00:17<02:04, 352.28it/s]
eval cumulative reward: 82.8892 (init: 82.8892), eval step-count: 8, average reward= 9.2239 (init= 9.0941), step count (max): 34, lr policy: 0.0003: 12%|█▏ | 6000/50000 [00:17<02:04, 352.28it/s]
eval cumulative reward: 82.8892 (init: 82.8892), eval step-count: 8, average reward= 9.2239 (init= 9.0941), step count (max): 34, lr policy: 0.0003: 14%|█▍ | 7000/50000 [00:20<02:03, 349.15it/s]
eval cumulative reward: 82.8892 (init: 82.8892), eval step-count: 8, average reward= 9.2411 (init= 9.0941), step count (max): 34, lr policy: 0.0003: 14%|█▍ | 7000/50000 [00:20<02:03, 349.15it/s]
eval cumulative reward: 82.8892 (init: 82.8892), eval step-count: 8, average reward= 9.2411 (init= 9.0941), step count (max): 34, lr policy: 0.0003: 16%|█▌ | 8000/50000 [00:23<01:59, 352.67it/s]
eval cumulative reward: 82.8892 (init: 82.8892), eval step-count: 8, average reward= 9.2366 (init= 9.0941), step count (max): 33, lr policy: 0.0003: 16%|█▌ | 8000/50000 [00:23<01:59, 352.67it/s]
eval cumulative reward: 82.8892 (init: 82.8892), eval step-count: 8, average reward= 9.2366 (init= 9.0941), step count (max): 33, lr policy: 0.0003: 18%|█▊ | 9000/50000 [00:25<01:55, 355.66it/s]
eval cumulative reward: 82.8892 (init: 82.8892), eval step-count: 8, average reward= 9.2558 (init= 9.0941), step count (max): 63, lr policy: 0.0003: 18%|█▊ | 9000/50000 [00:25<01:55, 355.66it/s]
eval cumulative reward: 82.8892 (init: 82.8892), eval step-count: 8, average reward= 9.2558 (init= 9.0941), step count (max): 63, lr policy: 0.0003: 20%|██ | 10000/50000 [00:28<01:51, 357.59it/s]
eval cumulative reward: 82.8892 (init: 82.8892), eval step-count: 8, average reward= 9.2629 (init= 9.0941), step count (max): 63, lr policy: 0.0003: 20%|██ | 10000/50000 [00:28<01:51, 357.59it/s]
eval cumulative reward: 82.8892 (init: 82.8892), eval step-count: 8, average reward= 9.2629 (init= 9.0941), step count (max): 63, lr policy: 0.0003: 22%|██▏ | 11000/50000 [00:31<01:48, 359.10it/s]
eval cumulative reward: 212.8816 (init: 82.8892), eval step-count: 22, average reward= 9.2628 (init= 9.0941), step count (max): 50, lr policy: 0.0003: 22%|██▏ | 11000/50000 [00:31<01:48, 359.10it/s]
eval cumulative reward: 212.8816 (init: 82.8892), eval step-count: 22, average reward= 9.2628 (init= 9.0941), step count (max): 50, lr policy: 0.0003: 24%|██▍ | 12000/50000 [00:34<01:45, 358.80it/s]
eval cumulative reward: 212.8816 (init: 82.8892), eval step-count: 22, average reward= 9.2694 (init= 9.0941), step count (max): 56, lr policy: 0.0003: 24%|██▍ | 12000/50000 [00:34<01:45, 358.80it/s]
eval cumulative reward: 212.8816 (init: 82.8892), eval step-count: 22, average reward= 9.2694 (init= 9.0941), step count (max): 56, lr policy: 0.0003: 26%|██▌ | 13000/50000 [00:36<01:42, 359.92it/s]
eval cumulative reward: 212.8816 (init: 82.8892), eval step-count: 22, average reward= 9.2515 (init= 9.0941), step count (max): 39, lr policy: 0.0003: 26%|██▌ | 13000/50000 [00:36<01:42, 359.92it/s]
eval cumulative reward: 212.8816 (init: 82.8892), eval step-count: 22, average reward= 9.2515 (init= 9.0941), step count (max): 39, lr policy: 0.0003: 28%|██▊ | 14000/50000 [00:39<01:41, 355.31it/s]
eval cumulative reward: 212.8816 (init: 82.8892), eval step-count: 22, average reward= 9.2663 (init= 9.0941), step count (max): 81, lr policy: 0.0003: 28%|██▊ | 14000/50000 [00:39<01:41, 355.31it/s]
eval cumulative reward: 212.8816 (init: 82.8892), eval step-count: 22, average reward= 9.2663 (init= 9.0941), step count (max): 81, lr policy: 0.0003: 30%|███ | 15000/50000 [00:42<01:37, 357.64it/s]
eval cumulative reward: 212.8816 (init: 82.8892), eval step-count: 22, average reward= 9.2876 (init= 9.0941), step count (max): 61, lr policy: 0.0002: 30%|███ | 15000/50000 [00:42<01:37, 357.64it/s]
eval cumulative reward: 212.8816 (init: 82.8892), eval step-count: 22, average reward= 9.2876 (init= 9.0941), step count (max): 61, lr policy: 0.0002: 32%|███▏ | 16000/50000 [00:45<01:34, 359.32it/s]
eval cumulative reward: 212.8816 (init: 82.8892), eval step-count: 22, average reward= 9.2780 (init= 9.0941), step count (max): 55, lr policy: 0.0002: 32%|███▏ | 16000/50000 [00:45<01:34, 359.32it/s]
eval cumulative reward: 212.8816 (init: 82.8892), eval step-count: 22, average reward= 9.2780 (init= 9.0941), step count (max): 55, lr policy: 0.0002: 34%|███▍ | 17000/50000 [00:48<01:31, 360.20it/s]
eval cumulative reward: 212.8816 (init: 82.8892), eval step-count: 22, average reward= 9.2695 (init= 9.0941), step count (max): 42, lr policy: 0.0002: 34%|███▍ | 17000/50000 [00:48<01:31, 360.20it/s]
eval cumulative reward: 212.8816 (init: 82.8892), eval step-count: 22, average reward= 9.2695 (init= 9.0941), step count (max): 42, lr policy: 0.0002: 36%|███▌ | 18000/50000 [00:50<01:28, 360.82it/s]
eval cumulative reward: 212.8816 (init: 82.8892), eval step-count: 22, average reward= 9.2753 (init= 9.0941), step count (max): 61, lr policy: 0.0002: 36%|███▌ | 18000/50000 [00:50<01:28, 360.82it/s]
eval cumulative reward: 212.8816 (init: 82.8892), eval step-count: 22, average reward= 9.2753 (init= 9.0941), step count (max): 61, lr policy: 0.0002: 38%|███▊ | 19000/50000 [00:53<01:25, 361.27it/s]
eval cumulative reward: 212.8816 (init: 82.8892), eval step-count: 22, average reward= 9.2847 (init= 9.0941), step count (max): 69, lr policy: 0.0002: 38%|███▊ | 19000/50000 [00:53<01:25, 361.27it/s]
eval cumulative reward: 212.8816 (init: 82.8892), eval step-count: 22, average reward= 9.2847 (init= 9.0941), step count (max): 69, lr policy: 0.0002: 40%|████ | 20000/50000 [00:56<01:24, 356.27it/s]
eval cumulative reward: 212.8816 (init: 82.8892), eval step-count: 22, average reward= 9.2992 (init= 9.0941), step count (max): 77, lr policy: 0.0002: 40%|████ | 20000/50000 [00:56<01:24, 356.27it/s]
eval cumulative reward: 212.8816 (init: 82.8892), eval step-count: 22, average reward= 9.2992 (init= 9.0941), step count (max): 77, lr policy: 0.0002: 42%|████▏ | 21000/50000 [00:59<01:20, 358.39it/s]
eval cumulative reward: 343.8970 (init: 82.8892), eval step-count: 36, average reward= 9.2825 (init= 9.0941), step count (max): 62, lr policy: 0.0002: 42%|████▏ | 21000/50000 [00:59<01:20, 358.39it/s]
eval cumulative reward: 343.8970 (init: 82.8892), eval step-count: 36, average reward= 9.2825 (init= 9.0941), step count (max): 62, lr policy: 0.0002: 44%|████▍ | 22000/50000 [01:02<01:18, 357.41it/s]
eval cumulative reward: 343.8970 (init: 82.8892), eval step-count: 36, average reward= 9.2864 (init= 9.0941), step count (max): 55, lr policy: 0.0002: 44%|████▍ | 22000/50000 [01:02<01:18, 357.41it/s]
eval cumulative reward: 343.8970 (init: 82.8892), eval step-count: 36, average reward= 9.2864 (init= 9.0941), step count (max): 55, lr policy: 0.0002: 46%|████▌ | 23000/50000 [01:04<01:15, 358.40it/s]
eval cumulative reward: 343.8970 (init: 82.8892), eval step-count: 36, average reward= 9.3024 (init= 9.0941), step count (max): 90, lr policy: 0.0002: 46%|████▌ | 23000/50000 [01:04<01:15, 358.40it/s]
eval cumulative reward: 343.8970 (init: 82.8892), eval step-count: 36, average reward= 9.3024 (init= 9.0941), step count (max): 90, lr policy: 0.0002: 48%|████▊ | 24000/50000 [01:07<01:12, 359.93it/s]
eval cumulative reward: 343.8970 (init: 82.8892), eval step-count: 36, average reward= 9.3009 (init= 9.0941), step count (max): 84, lr policy: 0.0002: 48%|████▊ | 24000/50000 [01:07<01:12, 359.93it/s]
eval cumulative reward: 343.8970 (init: 82.8892), eval step-count: 36, average reward= 9.3009 (init= 9.0941), step count (max): 84, lr policy: 0.0002: 50%|█████ | 25000/50000 [01:10<01:09, 361.25it/s]
eval cumulative reward: 343.8970 (init: 82.8892), eval step-count: 36, average reward= 9.2990 (init= 9.0941), step count (max): 93, lr policy: 0.0002: 50%|█████ | 25000/50000 [01:10<01:09, 361.25it/s]
eval cumulative reward: 343.8970 (init: 82.8892), eval step-count: 36, average reward= 9.2990 (init= 9.0941), step count (max): 93, lr policy: 0.0002: 52%|█████▏ | 26000/50000 [01:13<01:06, 361.82it/s]
eval cumulative reward: 343.8970 (init: 82.8892), eval step-count: 36, average reward= 9.2913 (init= 9.0941), step count (max): 57, lr policy: 0.0001: 52%|█████▏ | 26000/50000 [01:13<01:06, 361.82it/s]
eval cumulative reward: 343.8970 (init: 82.8892), eval step-count: 36, average reward= 9.2913 (init= 9.0941), step count (max): 57, lr policy: 0.0001: 54%|█████▍ | 27000/50000 [01:15<01:04, 356.54it/s]
eval cumulative reward: 343.8970 (init: 82.8892), eval step-count: 36, average reward= 9.2905 (init= 9.0941), step count (max): 51, lr policy: 0.0001: 54%|█████▍ | 27000/50000 [01:15<01:04, 356.54it/s]
eval cumulative reward: 343.8970 (init: 82.8892), eval step-count: 36, average reward= 9.2905 (init= 9.0941), step count (max): 51, lr policy: 0.0001: 56%|█████▌ | 28000/50000 [01:18<01:01, 358.12it/s]
eval cumulative reward: 343.8970 (init: 82.8892), eval step-count: 36, average reward= 9.2960 (init= 9.0941), step count (max): 66, lr policy: 0.0001: 56%|█████▌ | 28000/50000 [01:18<01:01, 358.12it/s]
eval cumulative reward: 343.8970 (init: 82.8892), eval step-count: 36, average reward= 9.2960 (init= 9.0941), step count (max): 66, lr policy: 0.0001: 58%|█████▊ | 29000/50000 [01:21<00:58, 358.96it/s]
eval cumulative reward: 343.8970 (init: 82.8892), eval step-count: 36, average reward= 9.2957 (init= 9.0941), step count (max): 85, lr policy: 0.0001: 58%|█████▊ | 29000/50000 [01:21<00:58, 358.96it/s]
eval cumulative reward: 343.8970 (init: 82.8892), eval step-count: 36, average reward= 9.2957 (init= 9.0941), step count (max): 85, lr policy: 0.0001: 60%|██████ | 30000/50000 [01:24<00:55, 359.97it/s]
eval cumulative reward: 343.8970 (init: 82.8892), eval step-count: 36, average reward= 9.3115 (init= 9.0941), step count (max): 72, lr policy: 0.0001: 60%|██████ | 30000/50000 [01:24<00:55, 359.97it/s]
eval cumulative reward: 343.8970 (init: 82.8892), eval step-count: 36, average reward= 9.3115 (init= 9.0941), step count (max): 72, lr policy: 0.0001: 62%|██████▏ | 31000/50000 [01:27<00:52, 360.61it/s]
eval cumulative reward: 512.9731 (init: 82.8892), eval step-count: 54, average reward= 9.2996 (init= 9.0941), step count (max): 75, lr policy: 0.0001: 62%|██████▏ | 31000/50000 [01:27<00:52, 360.61it/s]
eval cumulative reward: 512.9731 (init: 82.8892), eval step-count: 54, average reward= 9.2996 (init= 9.0941), step count (max): 75, lr policy: 0.0001: 64%|██████▍ | 32000/50000 [01:29<00:50, 357.88it/s]
eval cumulative reward: 512.9731 (init: 82.8892), eval step-count: 54, average reward= 9.3046 (init= 9.0941), step count (max): 137, lr policy: 0.0001: 64%|██████▍ | 32000/50000 [01:29<00:50, 357.88it/s]
eval cumulative reward: 512.9731 (init: 82.8892), eval step-count: 54, average reward= 9.3046 (init= 9.0941), step count (max): 137, lr policy: 0.0001: 66%|██████▌ | 33000/50000 [01:32<00:48, 353.91it/s]
eval cumulative reward: 512.9731 (init: 82.8892), eval step-count: 54, average reward= 9.3000 (init= 9.0941), step count (max): 76, lr policy: 0.0001: 66%|██████▌ | 33000/50000 [01:32<00:48, 353.91it/s]
eval cumulative reward: 512.9731 (init: 82.8892), eval step-count: 54, average reward= 9.3000 (init= 9.0941), step count (max): 76, lr policy: 0.0001: 68%|██████▊ | 34000/50000 [01:35<00:44, 356.73it/s]
eval cumulative reward: 512.9731 (init: 82.8892), eval step-count: 54, average reward= 9.2978 (init= 9.0941), step count (max): 105, lr policy: 0.0001: 68%|██████▊ | 34000/50000 [01:35<00:44, 356.73it/s]
eval cumulative reward: 512.9731 (init: 82.8892), eval step-count: 54, average reward= 9.2978 (init= 9.0941), step count (max): 105, lr policy: 0.0001: 70%|███████ | 35000/50000 [01:38<00:41, 358.22it/s]
eval cumulative reward: 512.9731 (init: 82.8892), eval step-count: 54, average reward= 9.3078 (init= 9.0941), step count (max): 95, lr policy: 0.0001: 70%|███████ | 35000/50000 [01:38<00:41, 358.22it/s]
eval cumulative reward: 512.9731 (init: 82.8892), eval step-count: 54, average reward= 9.3078 (init= 9.0941), step count (max): 95, lr policy: 0.0001: 72%|███████▏ | 36000/50000 [01:41<00:38, 359.68it/s]
eval cumulative reward: 512.9731 (init: 82.8892), eval step-count: 54, average reward= 9.3004 (init= 9.0941), step count (max): 65, lr policy: 0.0001: 72%|███████▏ | 36000/50000 [01:41<00:38, 359.68it/s]
eval cumulative reward: 512.9731 (init: 82.8892), eval step-count: 54, average reward= 9.3004 (init= 9.0941), step count (max): 65, lr policy: 0.0001: 74%|███████▍ | 37000/50000 [01:43<00:36, 359.95it/s]
eval cumulative reward: 512.9731 (init: 82.8892), eval step-count: 54, average reward= 9.3121 (init= 9.0941), step count (max): 105, lr policy: 0.0001: 74%|███████▍ | 37000/50000 [01:43<00:36, 359.95it/s]
eval cumulative reward: 512.9731 (init: 82.8892), eval step-count: 54, average reward= 9.3121 (init= 9.0941), step count (max): 105, lr policy: 0.0001: 76%|███████▌ | 38000/50000 [01:46<00:33, 360.34it/s]
eval cumulative reward: 512.9731 (init: 82.8892), eval step-count: 54, average reward= 9.3048 (init= 9.0941), step count (max): 95, lr policy: 0.0000: 76%|███████▌ | 38000/50000 [01:46<00:33, 360.34it/s]
eval cumulative reward: 512.9731 (init: 82.8892), eval step-count: 54, average reward= 9.3048 (init= 9.0941), step count (max): 95, lr policy: 0.0000: 78%|███████▊ | 39000/50000 [01:49<00:30, 361.20it/s]
eval cumulative reward: 512.9731 (init: 82.8892), eval step-count: 54, average reward= 9.3072 (init= 9.0941), step count (max): 94, lr policy: 0.0000: 78%|███████▊ | 39000/50000 [01:49<00:30, 361.20it/s]
eval cumulative reward: 512.9731 (init: 82.8892), eval step-count: 54, average reward= 9.3072 (init= 9.0941), step count (max): 94, lr policy: 0.0000: 80%|████████ | 40000/50000 [01:52<00:28, 356.76it/s]
eval cumulative reward: 512.9731 (init: 82.8892), eval step-count: 54, average reward= 9.3090 (init= 9.0941), step count (max): 76, lr policy: 0.0000: 80%|████████ | 40000/50000 [01:52<00:28, 356.76it/s]
eval cumulative reward: 512.9731 (init: 82.8892), eval step-count: 54, average reward= 9.3090 (init= 9.0941), step count (max): 76, lr policy: 0.0000: 82%|████████▏ | 41000/50000 [01:54<00:25, 358.52it/s]
eval cumulative reward: 718.6249 (init: 82.8892), eval step-count: 76, average reward= 9.3085 (init= 9.0941), step count (max): 88, lr policy: 0.0000: 82%|████████▏ | 41000/50000 [01:55<00:25, 358.52it/s]
eval cumulative reward: 718.6249 (init: 82.8892), eval step-count: 76, average reward= 9.3085 (init= 9.0941), step count (max): 88, lr policy: 0.0000: 84%|████████▍ | 42000/50000 [01:57<00:22, 355.16it/s]
eval cumulative reward: 718.6249 (init: 82.8892), eval step-count: 76, average reward= 9.3075 (init= 9.0941), step count (max): 75, lr policy: 0.0000: 84%|████████▍ | 42000/50000 [01:57<00:22, 355.16it/s]
eval cumulative reward: 718.6249 (init: 82.8892), eval step-count: 76, average reward= 9.3075 (init= 9.0941), step count (max): 75, lr policy: 0.0000: 86%|████████▌ | 43000/50000 [02:00<00:19, 357.56it/s]
eval cumulative reward: 718.6249 (init: 82.8892), eval step-count: 76, average reward= 9.3102 (init= 9.0941), step count (max): 96, lr policy: 0.0000: 86%|████████▌ | 43000/50000 [02:00<00:19, 357.56it/s]
eval cumulative reward: 718.6249 (init: 82.8892), eval step-count: 76, average reward= 9.3102 (init= 9.0941), step count (max): 96, lr policy: 0.0000: 88%|████████▊ | 44000/50000 [02:03<00:16, 358.51it/s]
eval cumulative reward: 718.6249 (init: 82.8892), eval step-count: 76, average reward= 9.3246 (init= 9.0941), step count (max): 163, lr policy: 0.0000: 88%|████████▊ | 44000/50000 [02:03<00:16, 358.51it/s]
eval cumulative reward: 718.6249 (init: 82.8892), eval step-count: 76, average reward= 9.3246 (init= 9.0941), step count (max): 163, lr policy: 0.0000: 90%|█████████ | 45000/50000 [02:06<00:13, 359.31it/s]
eval cumulative reward: 718.6249 (init: 82.8892), eval step-count: 76, average reward= 9.3108 (init= 9.0941), step count (max): 89, lr policy: 0.0000: 90%|█████████ | 45000/50000 [02:06<00:13, 359.31it/s]
eval cumulative reward: 718.6249 (init: 82.8892), eval step-count: 76, average reward= 9.3108 (init= 9.0941), step count (max): 89, lr policy: 0.0000: 92%|█████████▏| 46000/50000 [02:08<00:11, 359.28it/s]
eval cumulative reward: 718.6249 (init: 82.8892), eval step-count: 76, average reward= 9.3064 (init= 9.0941), step count (max): 82, lr policy: 0.0000: 92%|█████████▏| 46000/50000 [02:08<00:11, 359.28it/s]
eval cumulative reward: 718.6249 (init: 82.8892), eval step-count: 76, average reward= 9.3064 (init= 9.0941), step count (max): 82, lr policy: 0.0000: 94%|█████████▍| 47000/50000 [02:11<00:08, 353.94it/s]
eval cumulative reward: 718.6249 (init: 82.8892), eval step-count: 76, average reward= 9.3119 (init= 9.0941), step count (max): 102, lr policy: 0.0000: 94%|█████████▍| 47000/50000 [02:11<00:08, 353.94it/s]
eval cumulative reward: 718.6249 (init: 82.8892), eval step-count: 76, average reward= 9.3119 (init= 9.0941), step count (max): 102, lr policy: 0.0000: 96%|█████████▌| 48000/50000 [02:14<00:05, 356.89it/s]
eval cumulative reward: 718.6249 (init: 82.8892), eval step-count: 76, average reward= 9.3227 (init= 9.0941), step count (max): 140, lr policy: 0.0000: 96%|█████████▌| 48000/50000 [02:14<00:05, 356.89it/s]
eval cumulative reward: 718.6249 (init: 82.8892), eval step-count: 76, average reward= 9.3227 (init= 9.0941), step count (max): 140, lr policy: 0.0000: 98%|█████████▊| 49000/50000 [02:17<00:02, 358.40it/s]
eval cumulative reward: 718.6249 (init: 82.8892), eval step-count: 76, average reward= 9.3111 (init= 9.0941), step count (max): 87, lr policy: 0.0000: 98%|█████████▊| 49000/50000 [02:17<00:02, 358.40it/s]
eval cumulative reward: 718.6249 (init: 82.8892), eval step-count: 76, average reward= 9.3111 (init= 9.0941), step count (max): 87, lr policy: 0.0000: 100%|██████████| 50000/50000 [02:20<00:00, 359.59it/s]
eval cumulative reward: 718.6249 (init: 82.8892), eval step-count: 76, average reward= 9.3161 (init= 9.0941), step count (max): 86, lr policy: 0.0000: 100%|██████████| 50000/50000 [02:20<00:00, 359.59it/s]
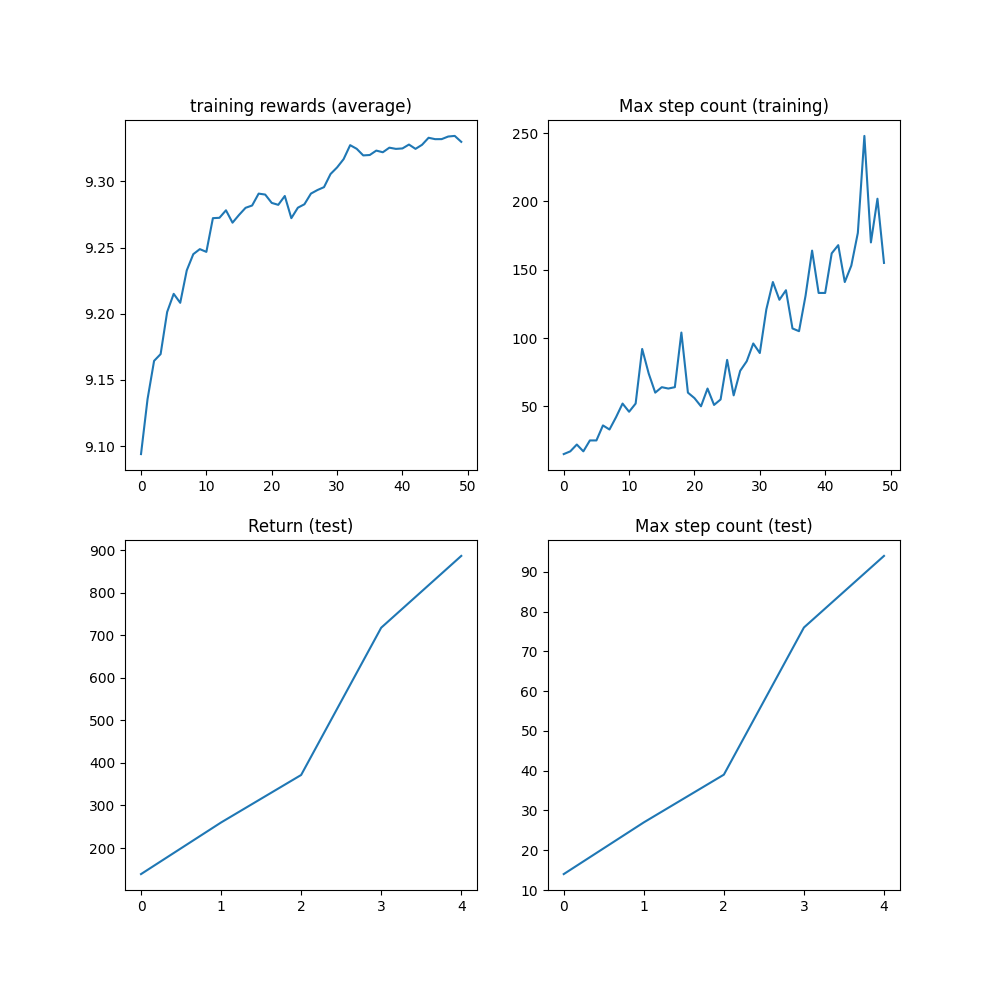
结果#
在达到 1M 步的上限之前,算法应该已经达到了 1000 步的最大步数,这是轨迹被截断之前的最大步数。
plt.figure(figsize=(10, 10))
plt.subplot(2, 2, 1)
plt.plot(logs["reward"])
plt.title("training rewards (average)")
plt.subplot(2, 2, 2)
plt.plot(logs["step_count"])
plt.title("Max step count (training)")
plt.subplot(2, 2, 3)
plt.plot(logs["eval reward (sum)"])
plt.title("Return (test)")
plt.subplot(2, 2, 4)
plt.plot(logs["eval step_count"])
plt.title("Max step count (test)")
plt.show()
结论和后续步骤#
在本教程中,我们学习了
如何使用
torchrl创建和自定义环境;如何编写模型和损失函数;
如何设置典型的训练循环。
如果您想进一步尝试本教程,可以进行以下修改
从效率的角度来看,我们可以并行运行多个模拟来加快数据收集。有关更多信息,请查看
ParallelEnv。从日志记录的角度来看,可以在请求渲染后向环境添加一个
torchrl.record.VideoRecorder变换,以获得倒立摆运行的可视化渲染。有关更多信息,请查看torchrl.record。
脚本总运行时间: (2 分 22.007 秒)
