


注意
单击 此处 下载完整的示例代码
使用 MVDR 波束形成进行语音增强¶
作者: 赵恒宁
1. 概述¶
这是一个关于如何使用 TorchAudio 应用最小方差无失真响应 (MVDR) 波束形成来增强语音的教程。
步骤
通过将干净语音/噪声的幅度除以混合语音的幅度来生成理想比率掩码 (IRM)。
使用
torchaudio.transforms.PSD()估计功率谱密度 (PSD) 矩阵。使用 MVDR 模块(
torchaudio.transforms.SoudenMVDR()和torchaudio.transforms.RTFMVDR())估计增强后的语音。对两种方法(
torchaudio.functional.rtf_evd()和torchaudio.functional.rtf_power())进行基准测试,以计算参考麦克风的相对传输函数 (RTF) 矩阵。
import torch
import torchaudio
import torchaudio.functional as F
print(torch.__version__)
print(torchaudio.__version__)
import matplotlib.pyplot as plt
from IPython.display import Audio
2.10.0.dev20251013+cu126
2.8.0a0+1d65bbe
2. 准备¶
2.1. 导入包
from torchaudio.utils import _download_asset
2.2. 下载音频数据¶
多通道音频示例选自 ConferencingSpeech 数据集。
原始文件名是
SSB07200001\#noise-sound-bible-0038\#7.86_6.16_3.00_3.14_4.84_134.5285_191.7899_0.4735\#15217\#25.16333303751458\#0.2101221178590021.wav
该文件是用以下方式生成的:
SSB07200001.wav来自 AISHELL-3 (Apache License v.2.0)noise-sound-bible-0038.wav来自 MUSAN (Attribution 4.0 International — CC BY 4.0)
SAMPLE_RATE = 16000
SAMPLE_CLEAN = _download_asset("tutorial-assets/mvdr/clean_speech.wav")
SAMPLE_NOISE = _download_asset("tutorial-assets/mvdr/noise.wav")
12.8%
25.6%
38.4%
51.2%
64.0%
76.8%
89.6%
100.0%
6.4%
12.8%
19.2%
25.6%
32.0%
38.4%
44.8%
51.2%
57.6%
64.0%
70.4%
76.8%
83.2%
89.6%
96.0%
100.0%
2.3. 辅助函数¶
def plot_spectrogram(stft, title="Spectrogram"):
magnitude = stft.abs()
spectrogram = 20 * torch.log10(magnitude + 1e-8).numpy()
figure, axis = plt.subplots(1, 1)
img = axis.imshow(spectrogram, cmap="viridis", vmin=-100, vmax=0, origin="lower", aspect="auto")
axis.set_title(title)
plt.colorbar(img, ax=axis)
def plot_mask(mask, title="Mask"):
mask = mask.numpy()
figure, axis = plt.subplots(1, 1)
img = axis.imshow(mask, cmap="viridis", origin="lower", aspect="auto")
axis.set_title(title)
plt.colorbar(img, ax=axis)
def si_snr(estimate, reference, epsilon=1e-8):
estimate = estimate - estimate.mean()
reference = reference - reference.mean()
reference_pow = reference.pow(2).mean(axis=1, keepdim=True)
mix_pow = (estimate * reference).mean(axis=1, keepdim=True)
scale = mix_pow / (reference_pow + epsilon)
reference = scale * reference
error = estimate - reference
reference_pow = reference.pow(2)
error_pow = error.pow(2)
reference_pow = reference_pow.mean(axis=1)
error_pow = error_pow.mean(axis=1)
si_snr = 10 * torch.log10(reference_pow) - 10 * torch.log10(error_pow)
return si_snr.item()
def generate_mixture(waveform_clean, waveform_noise, target_snr):
power_clean_signal = waveform_clean.pow(2).mean()
power_noise_signal = waveform_noise.pow(2).mean()
current_snr = 10 * torch.log10(power_clean_signal / power_noise_signal)
waveform_noise *= 10 ** (-(target_snr - current_snr) / 20)
return waveform_clean + waveform_noise
# If you have mir_eval installed, you can use it to evaluate the separation quality of the estimated sources.
# You can also evaluate the intelligibility of the speech with the Short-Time Objective Intelligibility (STOI) metric
# available in the `pystoi` package, or the Perceptual Evaluation of Speech Quality (PESQ) metric available in the `pesq` package.
def evaluate(estimate, reference):
from pesq import pesq
from pystoi import stoi
import mir_eval
si_snr_score = si_snr(estimate, reference)
(
sdr,
_,
_,
_,
) = mir_eval.separation.bss_eval_sources(reference.numpy(), estimate.numpy(), False)
pesq_mix = pesq(SAMPLE_RATE, estimate[0].numpy(), reference[0].numpy(), "wb")
stoi_mix = stoi(reference[0].numpy(), estimate[0].numpy(), SAMPLE_RATE, extended=False)
print(f"SDR score: {sdr[0]}")
print(f"Si-SNR score: {si_snr_score}")
print(f"PESQ score: {pesq_mix}")
print(f"STOI score: {stoi_mix}")
3. 生成理想比率掩码 (IRM)¶
3.1. 加载音频数据¶
waveform_clean, sr = torchaudio.load(SAMPLE_CLEAN)
waveform_noise, sr2 = torchaudio.load(SAMPLE_NOISE)
assert sr == sr2 == SAMPLE_RATE
# The mixture waveform is a combination of clean and noise waveforms with a desired SNR.
target_snr = 3
waveform_mix = generate_mixture(waveform_clean, waveform_noise, target_snr)
注意:为提高计算鲁棒性,建议将波形表示为双精度浮点数(torch.float64 或 torch.double)值。
3.2. 计算 STFT 系数¶
N_FFT = 1024
N_HOP = 256
stft = torchaudio.transforms.Spectrogram(
n_fft=N_FFT,
hop_length=N_HOP,
power=None,
)
istft = torchaudio.transforms.InverseSpectrogram(n_fft=N_FFT, hop_length=N_HOP)
stft_mix = stft(waveform_mix)
stft_clean = stft(waveform_clean)
stft_noise = stft(waveform_noise)
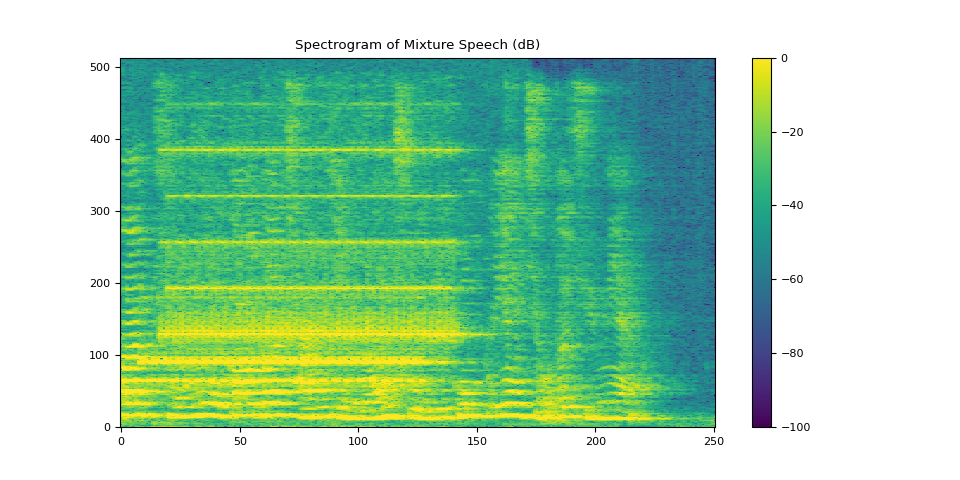
3.2.1. 可视化混合语音¶
plot_spectrogram(stft_mix[0], "Spectrogram of Mixture Speech (dB)")
Audio(waveform_mix[0], rate=SAMPLE_RATE)
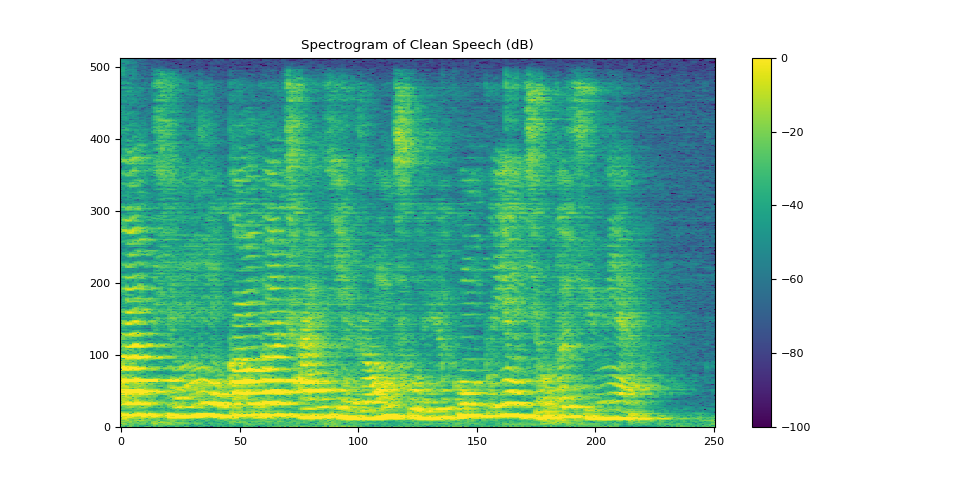
3.2.2. 可视化干净语音¶
plot_spectrogram(stft_clean[0], "Spectrogram of Clean Speech (dB)")
Audio(waveform_clean[0], rate=SAMPLE_RATE)
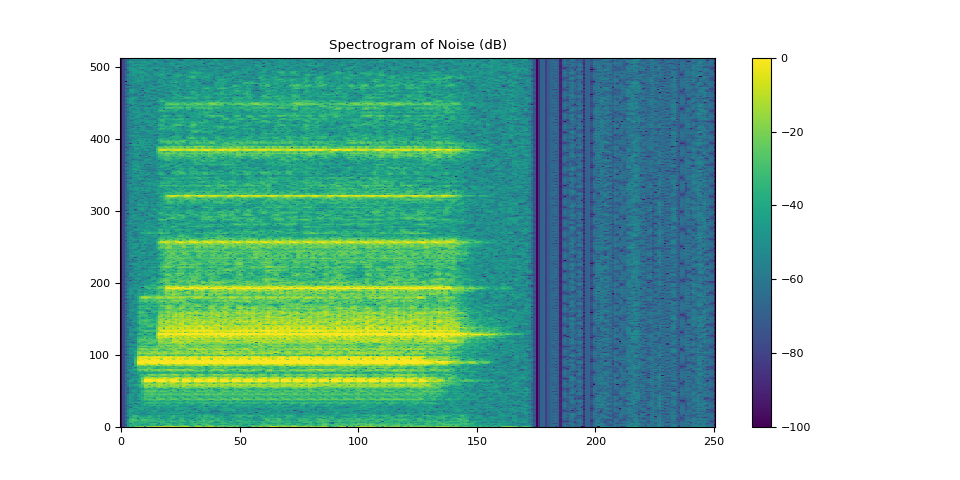
3.2.3. 可视化噪声¶
plot_spectrogram(stft_noise[0], "Spectrogram of Noise (dB)")
Audio(waveform_noise[0], rate=SAMPLE_RATE)
3.3. 定义参考麦克风¶
出于演示目的,我们选择麦克风阵列中的第一个麦克风作为参考通道。参考通道的选择可能取决于麦克风阵列的设计。
您也可以应用一个端到端的神经网络,该网络可以估计参考通道和 PSD 矩阵,然后通过 MVDR 模块获得增强后的 STFT 系数。
3.4. 计算 IRM¶
def get_irms(stft_clean, stft_noise):
mag_clean = stft_clean.abs() ** 2
mag_noise = stft_noise.abs() ** 2
irm_speech = mag_clean / (mag_clean + mag_noise)
irm_noise = mag_noise / (mag_clean + mag_noise)
return irm_speech[REFERENCE_CHANNEL], irm_noise[REFERENCE_CHANNEL]
irm_speech, irm_noise = get_irms(stft_clean, stft_noise)
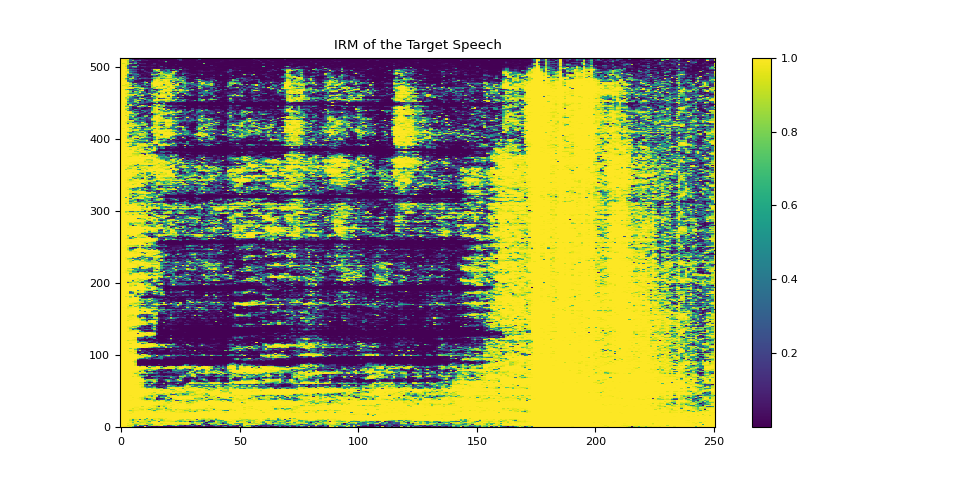
3.4.1. 可视化目标语音的 IRM¶
plot_mask(irm_speech, "IRM of the Target Speech")
3.4.2. 可视化噪声的 IRM¶
plot_mask(irm_noise, "IRM of the Noise")
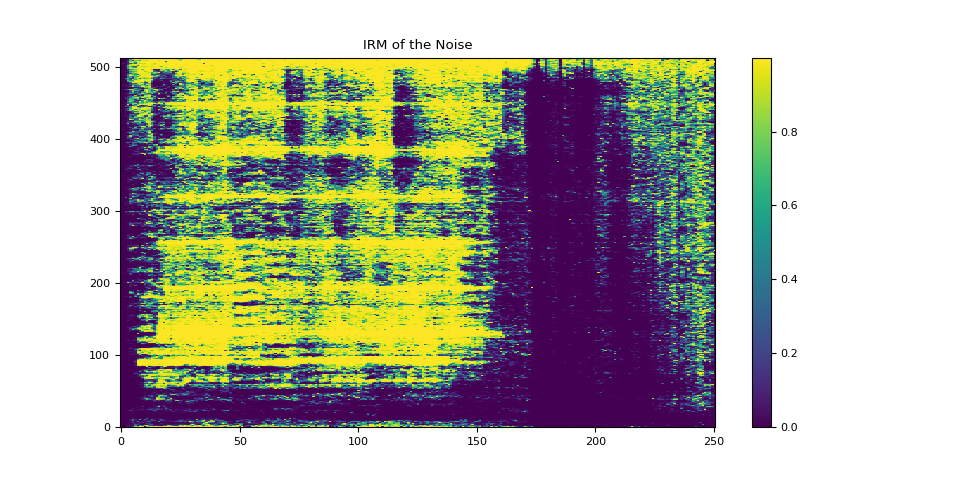
4. 计算 PSD 矩阵¶
torchaudio.transforms.PSD() 在给定混合语音的多通道复值 STFT 系数和时频掩码的情况下,计算时不变的 PSD 矩阵。
PSD 矩阵的形状为 (..., freq, channel, channel)。
psd_transform = torchaudio.transforms.PSD()
psd_speech = psd_transform(stft_mix, irm_speech)
psd_noise = psd_transform(stft_mix, irm_noise)
5. 使用 SoudenMVDR 进行波束形成¶
5.1. 应用波束形成¶
torchaudio.transforms.SoudenMVDR() 接受混合语音的多通道复值 STFT 系数、目标语音和噪声的 PSD 矩阵以及参考通道输入。
输出是增强语音的单通道复值 STFT 系数。然后,我们可以将此输出传递给 torchaudio.transforms.InverseSpectrogram() 模块来获得增强后的波形。
mvdr_transform = torchaudio.transforms.SoudenMVDR()
stft_souden = mvdr_transform(stft_mix, psd_speech, psd_noise, reference_channel=REFERENCE_CHANNEL)
waveform_souden = istft(stft_souden, length=waveform_mix.shape[-1])
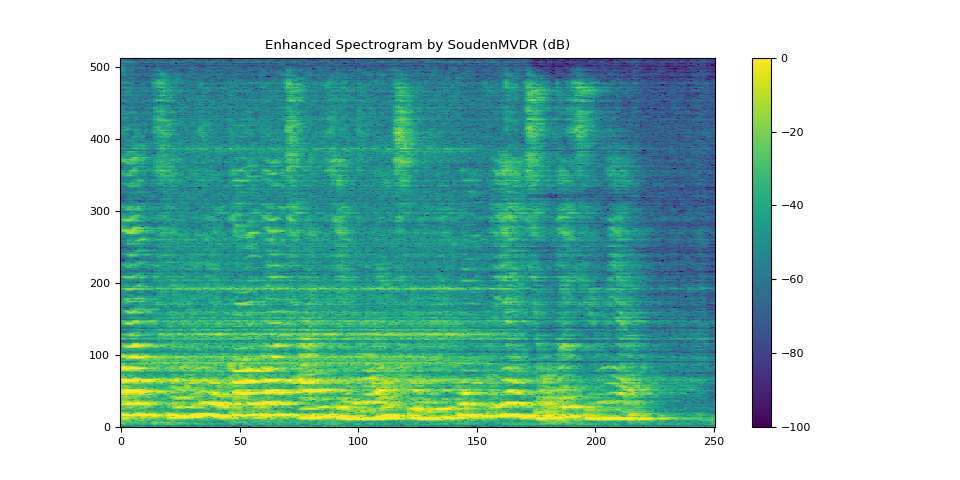
5.2. SoudenMVDR 的结果¶
plot_spectrogram(stft_souden, "Enhanced Spectrogram by SoudenMVDR (dB)")
waveform_souden = waveform_souden.reshape(1, -1)
Audio(waveform_souden, rate=SAMPLE_RATE)
6. 使用 RTFMVDR 进行波束形成¶
6.1. 计算 RTF¶
TorchAudio 提供了两种计算目标语音 RTF 矩阵的方法:
torchaudio.functional.rtf_evd(),它对目标语音的 PSD 矩阵进行特征值分解以获得 RTF 矩阵。torchaudio.functional.rtf_power(),它应用幂次迭代法。您可以使用参数n_iter指定迭代次数。
rtf_evd = F.rtf_evd(psd_speech)
rtf_power = F.rtf_power(psd_speech, psd_noise, reference_channel=REFERENCE_CHANNEL)
6.2. 应用波束形成¶
torchaudio.transforms.RTFMVDR() 接受混合语音的多通道复值 STFT 系数、目标语音的 RTF 矩阵、噪声的 PSD 矩阵以及参考通道输入。
输出是增强语音的单通道复值 STFT 系数。然后,我们可以将此输出传递给 torchaudio.transforms.InverseSpectrogram() 模块来获得增强后的波形。
mvdr_transform = torchaudio.transforms.RTFMVDR()
# compute the enhanced speech based on F.rtf_evd
stft_rtf_evd = mvdr_transform(stft_mix, rtf_evd, psd_noise, reference_channel=REFERENCE_CHANNEL)
waveform_rtf_evd = istft(stft_rtf_evd, length=waveform_mix.shape[-1])
# compute the enhanced speech based on F.rtf_power
stft_rtf_power = mvdr_transform(stft_mix, rtf_power, psd_noise, reference_channel=REFERENCE_CHANNEL)
waveform_rtf_power = istft(stft_rtf_power, length=waveform_mix.shape[-1])
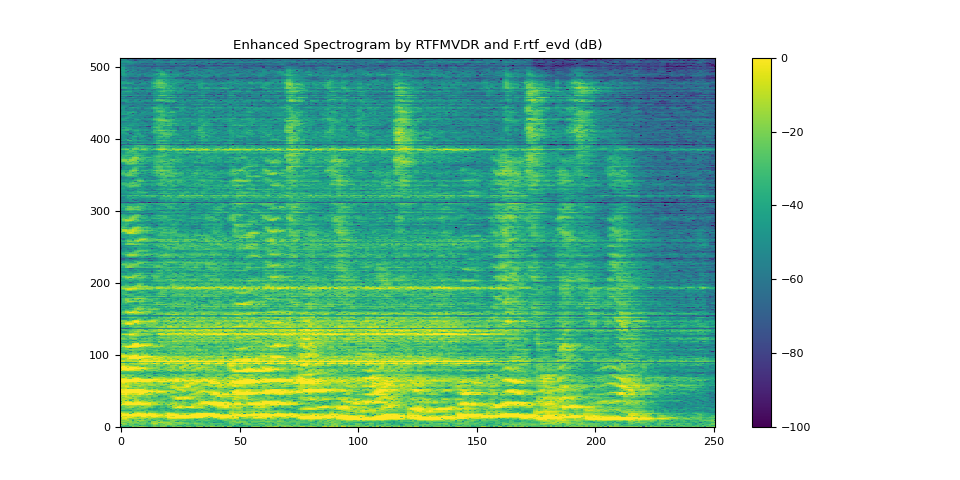
6.3. 使用 rtf_evd 进行 RTFMVDR 的结果¶
plot_spectrogram(stft_rtf_evd, "Enhanced Spectrogram by RTFMVDR and F.rtf_evd (dB)")
waveform_rtf_evd = waveform_rtf_evd.reshape(1, -1)
Audio(waveform_rtf_evd, rate=SAMPLE_RATE)
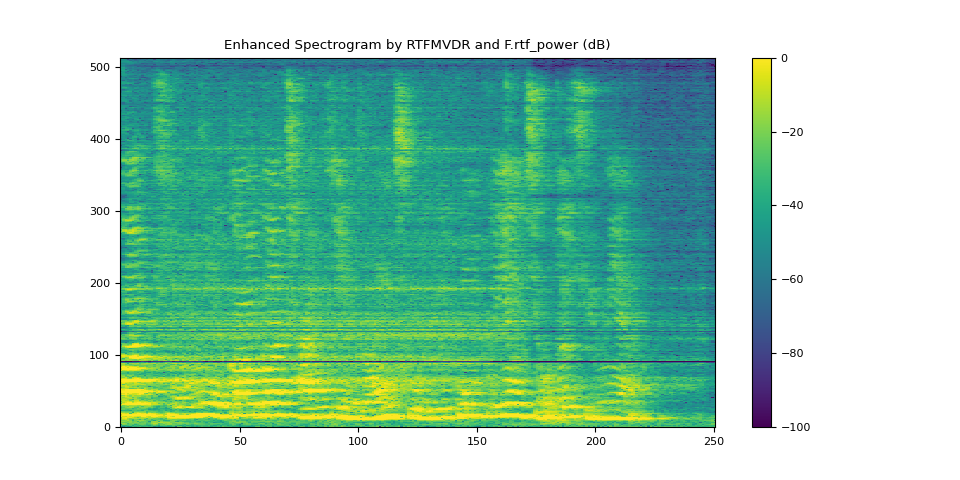
6.4. 使用 rtf_power 进行 RTFMVDR 的结果¶
plot_spectrogram(stft_rtf_power, "Enhanced Spectrogram by RTFMVDR and F.rtf_power (dB)")
waveform_rtf_power = waveform_rtf_power.reshape(1, -1)
Audio(waveform_rtf_power, rate=SAMPLE_RATE)
脚本总运行时间: ( 0 分 1.653 秒)
