


注意
点击这里下载完整的示例代码
振荡器和 ADSR 包络¶
作者:Moto Hira
警告
从 2.8 版本开始,我们正在重构 TorchAudio,以使其进入维护阶段。因此:
本教程中描述的 API 在 2.8 版本中已被弃用,并将在 2.9 版本中移除。
PyTorch 用于音频和视频的解码和编码功能正在被整合到 TorchCodec 中。
请参阅 https://github.com/pytorch/audio/issues/3902 获取更多信息。
本教程展示了如何使用 oscillator_bank() 和 adsr_envelope() 合成各种波形。
import torch
import torchaudio
print(torch.__version__)
print(torchaudio.__version__)
2.8.0+cu126
2.8.0
try:
from torchaudio.prototype.functional import adsr_envelope, oscillator_bank
except ModuleNotFoundError:
print(
"Failed to import prototype DSP features. "
"Please install torchaudio nightly builds. "
"Please refer to https://pytorch.ac.cn/get-started/locally "
"for instructions to install a nightly build."
)
raise
import math
import matplotlib.pyplot as plt
from IPython.display import Audio
PI = torch.pi
PI2 = 2 * torch.pi
振荡器组¶
正弦振荡器从给定的振幅和频率生成正弦波形。
其中相位 \(\theta_t\) 通过积分瞬时频率 \(f_t\) 得到。
注意
为什么要积分频率?瞬时频率表示给定时间点的振荡速度。因此,积分瞬时频率得到振荡相位的位移,因为从头开始。在离散时间信号处理中,积分变为累积。在 PyTorch 中,可以使用 torch.cumsum() 计算累积。
torchaudio.prototype.functional.oscillator_bank() 从振幅包络和瞬时频率生成一组正弦波形。
简单的正弦波¶
让我们从一个简单的例子开始。
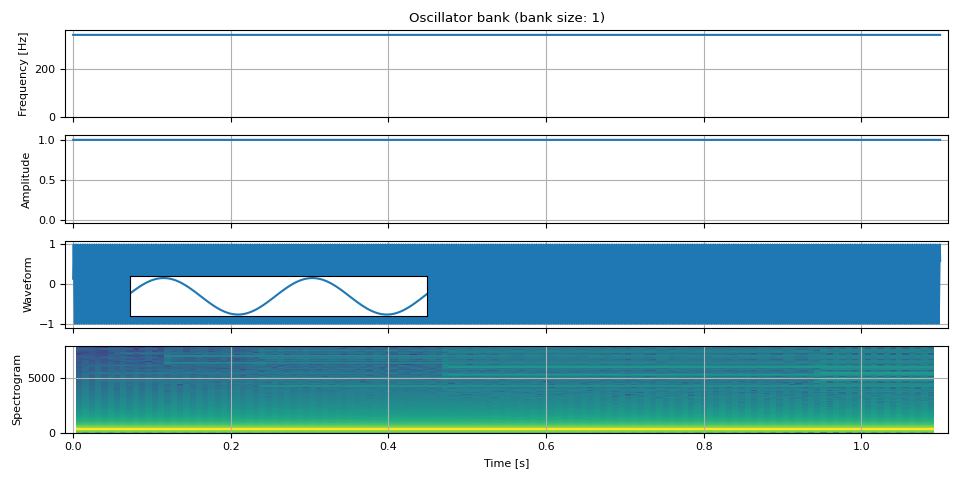
首先,我们生成一个在任何地方都具有恒定频率和振幅的正弦波,即一个规则的正弦波。
我们定义一些常量和辅助函数,我们将在本教程的其余部分使用它们。
F0 = 344.0 # fundamental frequency
DURATION = 1.1 # [seconds]
SAMPLE_RATE = 16_000 # [Hz]
NUM_FRAMES = int(DURATION * SAMPLE_RATE)
def show(freq, amp, waveform, sample_rate, zoom=None, vol=0.3):
t = (torch.arange(waveform.size(0)) / sample_rate).numpy()
fig, axes = plt.subplots(4, 1, sharex=True)
axes[0].plot(t, freq.numpy())
axes[0].set(title=f"Oscillator bank (bank size: {amp.size(-1)})", ylabel="Frequency [Hz]", ylim=[-0.03, None])
axes[1].plot(t, amp.numpy())
axes[1].set(ylabel="Amplitude", ylim=[-0.03 if torch.all(amp >= 0.0) else None, None])
axes[2].plot(t, waveform.numpy())
axes[2].set(ylabel="Waveform")
axes[3].specgram(waveform, Fs=sample_rate)
axes[3].set(ylabel="Spectrogram", xlabel="Time [s]", xlim=[-0.01, t[-1] + 0.01])
for i in range(4):
axes[i].grid(True)
pos = axes[2].get_position()
plt.tight_layout()
if zoom is not None:
ax = fig.add_axes([pos.x0 + 0.01, pos.y0 + 0.03, pos.width / 2.5, pos.height / 2.0])
ax.plot(t, waveform)
ax.set(xlim=zoom, xticks=[], yticks=[])
waveform /= waveform.abs().max()
return Audio(vol * waveform, rate=sample_rate, normalize=False)
现在我们合成具有恒定频率和振幅的音频
freq = torch.full((NUM_FRAMES, 1), F0)
amp = torch.ones((NUM_FRAMES, 1))
waveform = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
show(freq, amp, waveform, SAMPLE_RATE, zoom=(1 / F0, 3 / F0))
/pytorch/audio/examples/tutorials/oscillator_tutorial.py:150: UserWarning: torchaudio.prototype.functional._dsp.oscillator_bank has been deprecated. This deprecation is part of a large refactoring effort to transition TorchAudio into a maintenance phase. Please see https://github.com/pytorch/audio/issues/3902 for more information. It will be removed from the 2.9 release.
waveform = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
组合多个正弦波¶
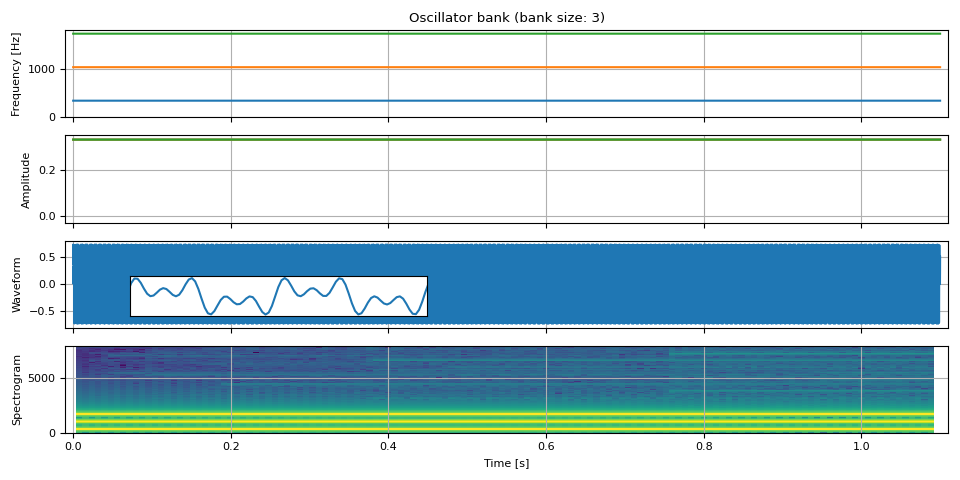
oscillator_bank() 可以组合任意数量的正弦波来生成波形。
freq = torch.empty((NUM_FRAMES, 3))
freq[:, 0] = F0
freq[:, 1] = 3 * F0
freq[:, 2] = 5 * F0
amp = torch.ones((NUM_FRAMES, 3)) / 3
waveform = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
show(freq, amp, waveform, SAMPLE_RATE, zoom=(1 / F0, 3 / F0))
/pytorch/audio/examples/tutorials/oscillator_tutorial.py:169: UserWarning: torchaudio.prototype.functional._dsp.oscillator_bank has been deprecated. This deprecation is part of a large refactoring effort to transition TorchAudio into a maintenance phase. Please see https://github.com/pytorch/audio/issues/3902 for more information. It will be removed from the 2.9 release.
waveform = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
随时间变化的频率¶
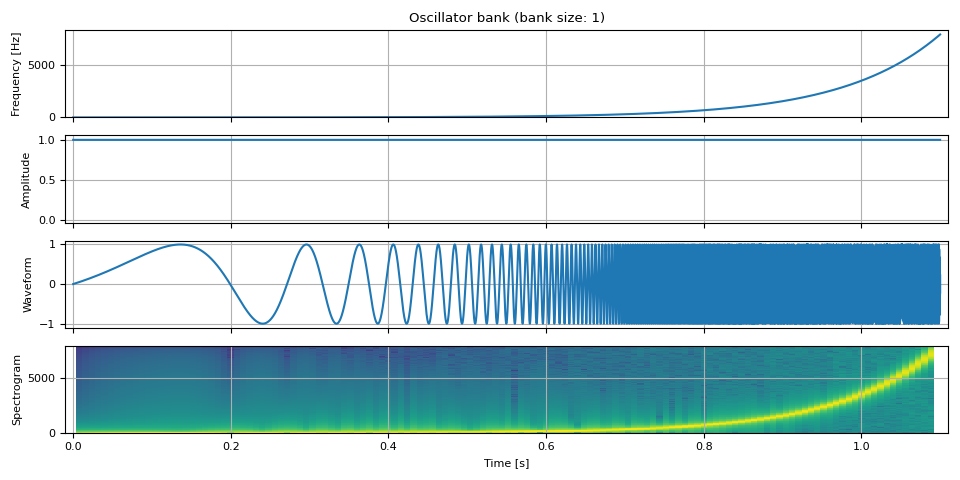
让我们改变频率随时间的变化。 在这里,我们以对数刻度将频率从零更改为奈奎斯特频率(采样率的一半),以便容易看到波形的变化。
nyquist_freq = SAMPLE_RATE / 2
freq = torch.logspace(0, math.log(0.99 * nyquist_freq, 10), NUM_FRAMES).unsqueeze(-1)
amp = torch.ones((NUM_FRAMES, 1))
waveform = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
show(freq, amp, waveform, SAMPLE_RATE, vol=0.2)
/pytorch/audio/examples/tutorials/oscillator_tutorial.py:187: UserWarning: torchaudio.prototype.functional._dsp.oscillator_bank has been deprecated. This deprecation is part of a large refactoring effort to transition TorchAudio into a maintenance phase. Please see https://github.com/pytorch/audio/issues/3902 for more information. It will be removed from the 2.9 release.
waveform = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
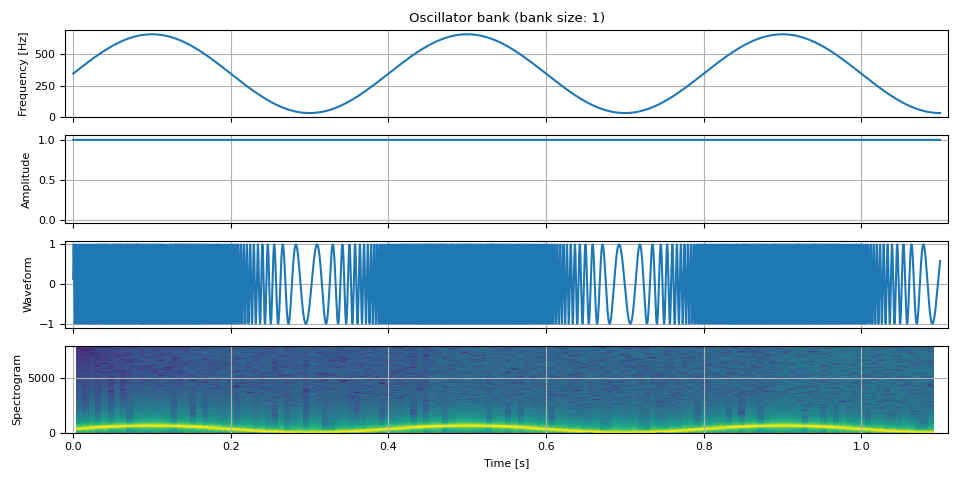
我们还可以振荡频率。
fm = 2.5 # rate at which the frequency oscillates
f_dev = 0.9 * F0 # the degree of frequency oscillation
freq = F0 + f_dev * torch.sin(torch.linspace(0, fm * PI2 * DURATION, NUM_FRAMES))
freq = freq.unsqueeze(-1)
amp = torch.ones((NUM_FRAMES, 1))
waveform = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
show(freq, amp, waveform, SAMPLE_RATE)
/pytorch/audio/examples/tutorials/oscillator_tutorial.py:204: UserWarning: torchaudio.prototype.functional._dsp.oscillator_bank has been deprecated. This deprecation is part of a large refactoring effort to transition TorchAudio into a maintenance phase. Please see https://github.com/pytorch/audio/issues/3902 for more information. It will be removed from the 2.9 release.
waveform = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
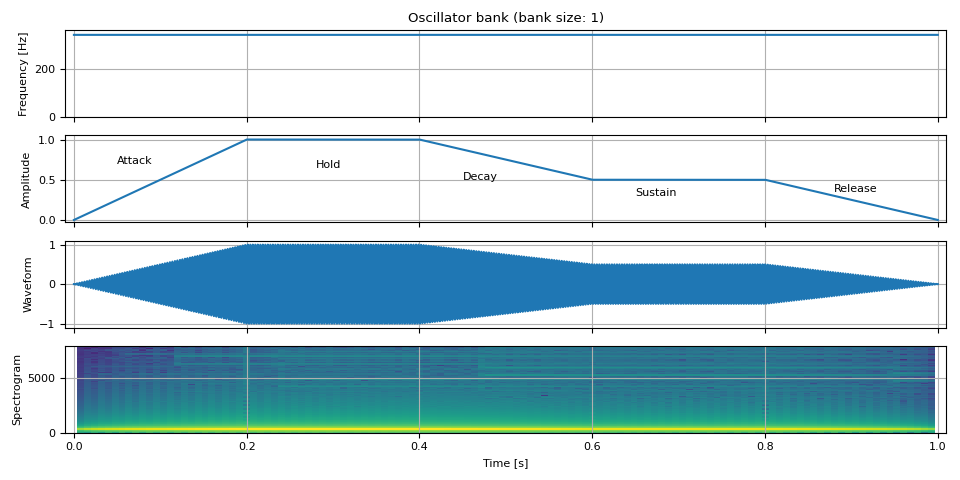
ADSR 包络¶
接下来,我们改变振幅随时间的变化。 用于对振幅建模的常见技术是 ADSR 包络。
ADSR 代表 Attack (起音), Decay (衰减), Sustain (持续), 和 Release (释放)。
起音 (Attack) 是从零到达最高电平所需的时间。
衰减 (Decay) 是从最高电平到达持续电平所需的时间。
持续 (Sustain) 是电平保持不变的电平。
释放 (Release) 是从持续电平降至零所需的时间。
ADSR 模型有很多变体,此外,一些模型还具有以下属性
保持 (Hold):起音后电平保持在最高电平的时间。
非线性衰减/释放:衰减和释放采用非线性变化。
adsr_envelope 支持保持和多项式衰减。
freq = torch.full((SAMPLE_RATE, 1), F0)
amp = adsr_envelope(
SAMPLE_RATE,
attack=0.2,
hold=0.2,
decay=0.2,
sustain=0.5,
release=0.2,
n_decay=1,
)
amp = amp.unsqueeze(-1)
waveform = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
audio = show(freq, amp, waveform, SAMPLE_RATE)
ax = plt.gcf().axes[1]
ax.annotate("Attack", xy=(0.05, 0.7))
ax.annotate("Hold", xy=(0.28, 0.65))
ax.annotate("Decay", xy=(0.45, 0.5))
ax.annotate("Sustain", xy=(0.65, 0.3))
ax.annotate("Release", xy=(0.88, 0.35))
audio
/pytorch/audio/examples/tutorials/oscillator_tutorial.py:236: UserWarning: torchaudio.prototype.functional._dsp.adsr_envelope has been deprecated. This deprecation is part of a large refactoring effort to transition TorchAudio into a maintenance phase. Please see https://github.com/pytorch/audio/issues/3902 for more information. It will be removed from the 2.9 release.
amp = adsr_envelope(
/pytorch/audio/examples/tutorials/oscillator_tutorial.py:247: UserWarning: torchaudio.prototype.functional._dsp.oscillator_bank has been deprecated. This deprecation is part of a large refactoring effort to transition TorchAudio into a maintenance phase. Please see https://github.com/pytorch/audio/issues/3902 for more information. It will be removed from the 2.9 release.
waveform = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
现在让我们看一下 ADSR 包络如何用于创建不同声音的一些示例。
以下示例的灵感来自这篇文章。
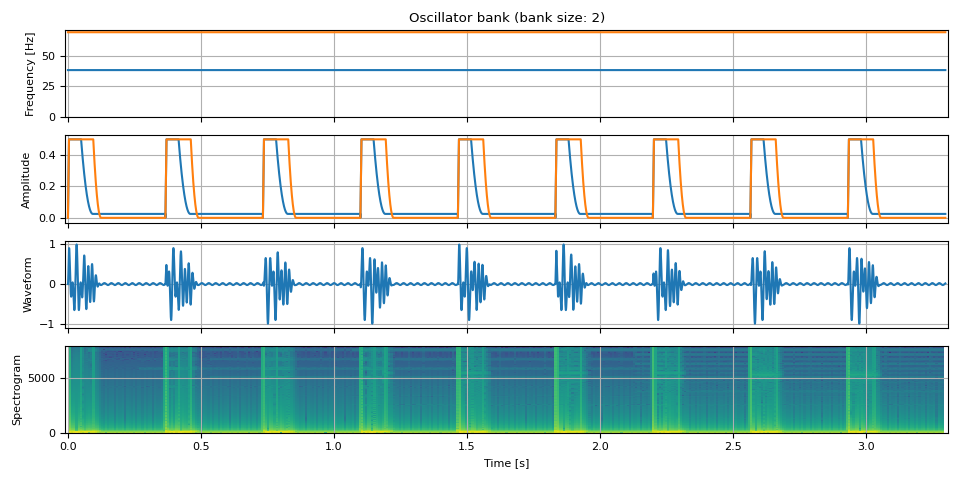
鼓点¶
unit = NUM_FRAMES // 3
repeat = 9
freq = torch.empty((unit * repeat, 2))
freq[:, 0] = F0 / 9
freq[:, 1] = F0 / 5
amp = torch.stack(
(
adsr_envelope(unit, attack=0.01, hold=0.125, decay=0.12, sustain=0.05, release=0),
adsr_envelope(unit, attack=0.01, hold=0.25, decay=0.08, sustain=0, release=0),
),
dim=-1,
)
amp = amp.repeat(repeat, 1) / 2
bass = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
show(freq, amp, bass, SAMPLE_RATE, vol=0.5)
/pytorch/audio/examples/tutorials/oscillator_tutorial.py:281: UserWarning: torchaudio.prototype.functional._dsp.adsr_envelope has been deprecated. This deprecation is part of a large refactoring effort to transition TorchAudio into a maintenance phase. Please see https://github.com/pytorch/audio/issues/3902 for more information. It will be removed from the 2.9 release.
adsr_envelope(unit, attack=0.01, hold=0.125, decay=0.12, sustain=0.05, release=0),
/pytorch/audio/examples/tutorials/oscillator_tutorial.py:282: UserWarning: torchaudio.prototype.functional._dsp.adsr_envelope has been deprecated. This deprecation is part of a large refactoring effort to transition TorchAudio into a maintenance phase. Please see https://github.com/pytorch/audio/issues/3902 for more information. It will be removed from the 2.9 release.
adsr_envelope(unit, attack=0.01, hold=0.25, decay=0.08, sustain=0, release=0),
/pytorch/audio/examples/tutorials/oscillator_tutorial.py:288: UserWarning: torchaudio.prototype.functional._dsp.oscillator_bank has been deprecated. This deprecation is part of a large refactoring effort to transition TorchAudio into a maintenance phase. Please see https://github.com/pytorch/audio/issues/3902 for more information. It will be removed from the 2.9 release.
bass = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
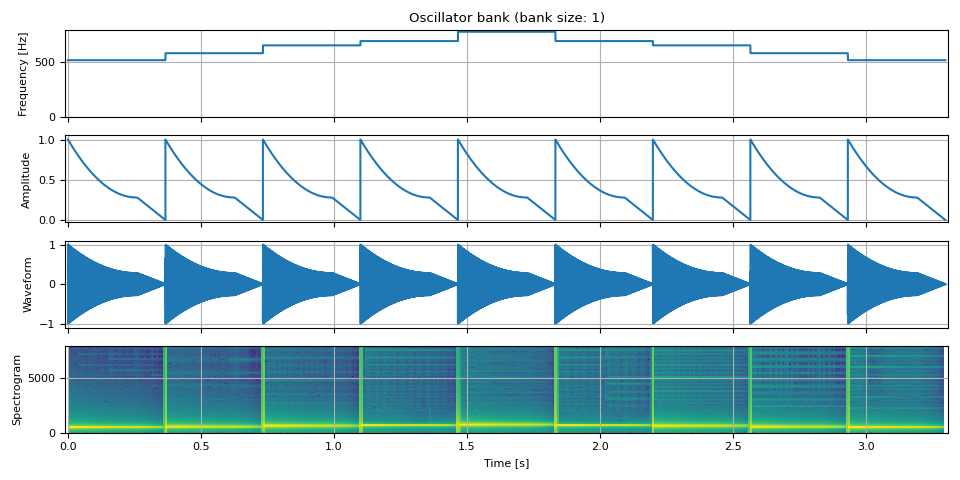
拨弦¶
tones = [
513.74, # do
576.65, # re
647.27, # mi
685.76, # fa
769.74, # so
685.76, # fa
647.27, # mi
576.65, # re
513.74, # do
]
freq = torch.cat([torch.full((unit, 1), tone) for tone in tones], dim=0)
amp = adsr_envelope(unit, attack=0, decay=0.7, sustain=0.28, release=0.29)
amp = amp.repeat(9).unsqueeze(-1)
doremi = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
show(freq, amp, doremi, SAMPLE_RATE)
/pytorch/audio/examples/tutorials/oscillator_tutorial.py:310: UserWarning: torchaudio.prototype.functional._dsp.adsr_envelope has been deprecated. This deprecation is part of a large refactoring effort to transition TorchAudio into a maintenance phase. Please see https://github.com/pytorch/audio/issues/3902 for more information. It will be removed from the 2.9 release.
amp = adsr_envelope(unit, attack=0, decay=0.7, sustain=0.28, release=0.29)
/pytorch/audio/examples/tutorials/oscillator_tutorial.py:313: UserWarning: torchaudio.prototype.functional._dsp.oscillator_bank has been deprecated. This deprecation is part of a large refactoring effort to transition TorchAudio into a maintenance phase. Please see https://github.com/pytorch/audio/issues/3902 for more information. It will be removed from the 2.9 release.
doremi = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
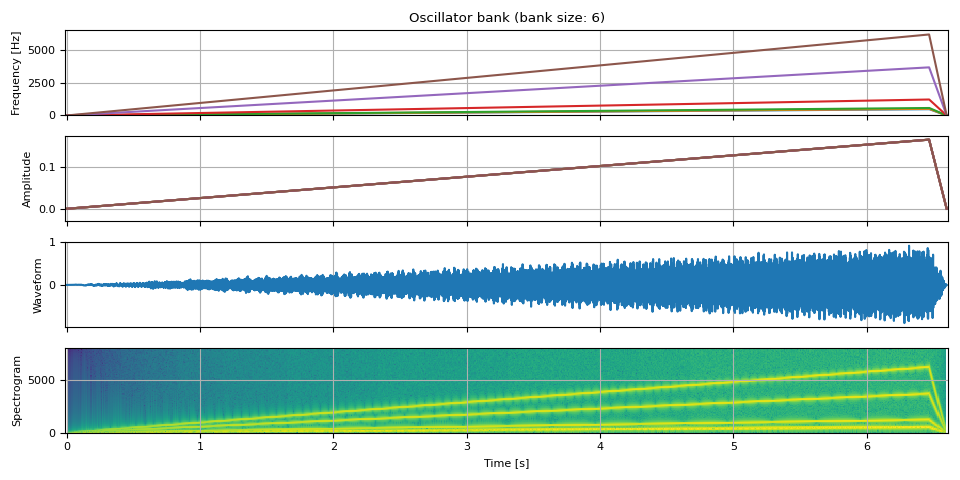
上升音¶
env = adsr_envelope(NUM_FRAMES * 6, attack=0.98, decay=0.0, sustain=1, release=0.02)
tones = [
484.90, # B4
513.74, # C5
576.65, # D5
1221.88, # D#6/Eb6
3661.50, # A#7/Bb7
6157.89, # G8
]
freq = torch.stack([f * env for f in tones], dim=-1)
amp = env.unsqueeze(-1).expand(freq.shape) / len(tones)
waveform = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
show(freq, amp, waveform, SAMPLE_RATE)
/pytorch/audio/examples/tutorials/oscillator_tutorial.py:322: UserWarning: torchaudio.prototype.functional._dsp.adsr_envelope has been deprecated. This deprecation is part of a large refactoring effort to transition TorchAudio into a maintenance phase. Please see https://github.com/pytorch/audio/issues/3902 for more information. It will be removed from the 2.9 release.
env = adsr_envelope(NUM_FRAMES * 6, attack=0.98, decay=0.0, sustain=1, release=0.02)
/pytorch/audio/examples/tutorials/oscillator_tutorial.py:336: UserWarning: torchaudio.prototype.functional._dsp.oscillator_bank has been deprecated. This deprecation is part of a large refactoring effort to transition TorchAudio into a maintenance phase. Please see https://github.com/pytorch/audio/issues/3902 for more information. It will be removed from the 2.9 release.
waveform = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
参考资料¶
脚本的总运行时间:(0 分钟 2.882 秒)
