


注意
转到末尾 下载完整的示例代码。
可视化梯度#
作者: Justin Silver
本教程解释了如何在神经网络的任何层提取和可视化梯度。通过检查信息如何从网络末端流向我们想要优化的参数,我们可以调试训练过程中出现的梯度消失或爆炸等问题。
开始之前,请确保您理解张量及其操作方法。对autograd 的工作原理有基本了解也会很有帮助。
设置#
首先,请确保已安装 PyTorch,然后导入必要的库。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import matplotlib.pyplot as plt
接下来,我们将创建一个用于 MNIST 数据集的网络,其架构类似于批量归一化论文中描述的。
为了说明梯度可视化的重要性,我们将实例化一个带有批量归一化 (BatchNorm) 的网络版本和一个不带批量归一化的版本。批量归一化是一种非常有效的解决梯度消失/爆炸的技术,我们将通过实验来验证这一点。
我们使用的模型具有可配置数量的重复全连接层,这些层在 nn.Linear、norm_layer 和 nn.Sigmoid 之间交替。如果启用了批量归一化,则 norm_layer 将使用 BatchNorm1d,否则将使用 Identity 变换。
def fc_layer(in_size, out_size, norm_layer):
"""Return a stack of linear->norm->sigmoid layers"""
return nn.Sequential(nn.Linear(in_size, out_size), norm_layer(out_size), nn.Sigmoid())
class Net(nn.Module):
"""Define a network that has num_layers of linear->norm->sigmoid transformations"""
def __init__(self, in_size=28*28, hidden_size=128,
out_size=10, num_layers=3, batchnorm=False):
super().__init__()
if batchnorm is False:
norm_layer = nn.Identity
else:
norm_layer = nn.BatchNorm1d
layers = []
layers.append(fc_layer(in_size, hidden_size, norm_layer))
for i in range(num_layers-1):
layers.append(fc_layer(hidden_size, hidden_size, norm_layer))
layers.append(nn.Linear(hidden_size, out_size))
self.layers = nn.Sequential(*layers)
def forward(self, x):
x = torch.flatten(x, 1)
return self.layers(x)
接下来,我们设置一些模拟数据,实例化两个模型版本,并初始化优化器。
# set up dummy data
x = torch.randn(10, 28, 28)
y = torch.randint(10, (10, ))
# init model
model_bn = Net(batchnorm=True, num_layers=3)
model_nobn = Net(batchnorm=False, num_layers=3)
model_bn.train()
model_nobn.train()
optimizer_bn = optim.SGD(model_bn.parameters(), lr=0.01, momentum=0.9)
optimizer_nobn = optim.SGD(model_nobn.parameters(), lr=0.01, momentum=0.9)
我们可以通过探测其中一个内部层来验证批量归一化仅应用于其中一个模型。
print(model_bn.layers[0])
print(model_nobn.layers[0])
Sequential(
(0): Linear(in_features=784, out_features=128, bias=True)
(1): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sigmoid()
)
Sequential(
(0): Linear(in_features=784, out_features=128, bias=True)
(1): Identity()
(2): Sigmoid()
)
注册钩子#
由于我们将模型的逻辑和状态封装在 nn.Module 中,如果我们想避免直接修改模块代码,就需要另一种方法来访问中间梯度。这可以通过注册钩子来完成。
警告
与在张量本身上使用 retain_grad() 相比,更推荐使用附加在输出张量上的反向传播钩子。另一种方法是直接附加模块钩子(例如 register_full_backward_hook()),只要 nn.Module 实例不执行任何就地操作。有关更多信息,请参阅此 issue。
以下代码定义了我们的钩子,并为网络的层收集了描述性名称。
# note that wrapper functions are used for Python closure
# so that we can pass arguments.
def hook_forward(module_name, grads, hook_backward):
def hook(module, args, output):
"""Forward pass hook which attaches backward pass hooks to intermediate tensors"""
output.register_hook(hook_backward(module_name, grads))
return hook
def hook_backward(module_name, grads):
def hook(grad):
"""Backward pass hook which appends gradients"""
grads.append((module_name, grad))
return hook
def get_all_layers(model, hook_forward, hook_backward):
"""Register forward pass hook (which registers a backward hook) to model outputs
Returns:
- layers: a dict with keys as layer/module and values as layer/module names
e.g. layers[nn.Conv2d] = layer1.0.conv1
- grads: a list of tuples with module name and tensor output gradient
e.g. grads[0] == (layer1.0.conv1, tensor.Torch(...))
"""
layers = dict()
grads = []
for name, layer in model.named_modules():
# skip Sequential and/or wrapper modules
if any(layer.children()) is False:
layers[layer] = name
layer.register_forward_hook(hook_forward(name, grads, hook_backward))
return layers, grads
# register hooks
layers_bn, grads_bn = get_all_layers(model_bn, hook_forward, hook_backward)
layers_nobn, grads_nobn = get_all_layers(model_nobn, hook_forward, hook_backward)
训练与可视化#
现在,让我们训练模型几个 epoch。
epochs = 10
for epoch in range(epochs):
# important to clear, because we append to
# outputs everytime we do a forward pass
grads_bn.clear()
grads_nobn.clear()
optimizer_bn.zero_grad()
optimizer_nobn.zero_grad()
y_pred_bn = model_bn(x)
y_pred_nobn = model_nobn(x)
loss_bn = F.cross_entropy(y_pred_bn, y)
loss_nobn = F.cross_entropy(y_pred_nobn, y)
loss_bn.backward()
loss_nobn.backward()
optimizer_bn.step()
optimizer_nobn.step()
运行前向和反向传播后,所有中间张量的梯度应该都存在于 grads_bn 和 grads_nobn 中。我们计算每个梯度矩阵的平均绝对值,以便比较这两个模型。
def get_grads(grads):
layer_idx = []
avg_grads = []
for idx, (name, grad) in enumerate(grads):
if grad is not None:
avg_grad = grad.abs().mean()
avg_grads.append(avg_grad)
# idx is backwards since we appended in backward pass
layer_idx.append(len(grads) - 1 - idx)
return layer_idx, avg_grads
layer_idx_bn, avg_grads_bn = get_grads(grads_bn)
layer_idx_nobn, avg_grads_nobn = get_grads(grads_nobn)
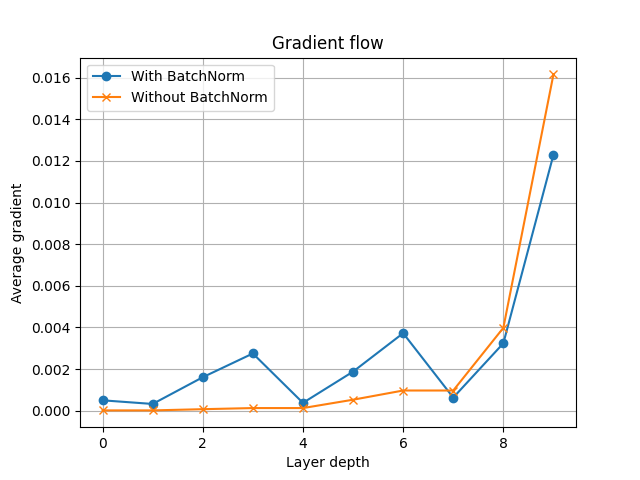
计算了平均梯度后,我们现在可以绘制它们,并查看值随网络深度的变化。请注意,当我们不应用批量归一化时,中间层的梯度值会很快变为零。然而,批量归一化模型在其中间层保持非零梯度。
fig, ax = plt.subplots()
ax.plot(layer_idx_bn, avg_grads_bn, label="With BatchNorm", marker="o")
ax.plot(layer_idx_nobn, avg_grads_nobn, label="Without BatchNorm", marker="x")
ax.set_xlabel("Layer depth")
ax.set_ylabel("Average gradient")
ax.set_title("Gradient flow")
ax.grid(True)
ax.legend()
plt.show()
结论#
在本教程中,我们演示了如何可视化封装在 nn.Module 类中的神经网络的梯度流。我们定性地展示了批量归一化如何帮助缓解深度神经网络中出现的梯度消失问题。
如果您想了解更多关于 PyTorch 的 autograd 系统如何工作的信息,请访问下面的参考文献。如果您对此教程有任何反馈(改进、拼写错误等),请使用PyTorch 论坛和/或issue tracker与我们联系。
(可选) 附加练习#
尝试增加模型中层的数量(
num_layers),看看这对梯度流图有什么影响。如何修改代码来可视化平均激活而不是平均梯度?(*提示:在 hook_forward() 函数中,我们可以访问原始张量输出*)
还有哪些其他方法可以处理梯度消失和爆炸问题?
参考文献#
脚本总运行时间: (0 分钟 0.288 秒)
