Elastic Agent#
创建于: May 04, 2021 | 最后更新于: Jun 07, 2025
Server#
Elastic Agent 是 torchelastic 的控制平面。
它是一个启动和管理底层工作进程的进程。Agent 负责
与分布式 PyTorch 协同工作:工作进程以所有必要信息启动,以便成功且轻松地调用
torch.distributed.init_process_group()。容错:监控工作进程,并在检测到工作进程失败或不健康时,终止所有工作进程并重新启动所有进程。
弹性:响应成员资格变化并使用新成员重新启动工作进程。
最简单的 Agent 是按节点部署的,并与本地进程协同工作。更高级的 Agent 可以远程启动和管理工作进程。Agent 可以是完全去中心化的,基于它所管理的进程进行决策。也可以是协调的,与其他 Agent(管理同一作业中工作进程的 Agent)通信以做出集体决策。
下图是管理本地工作进程组的 Agent 的示意图。
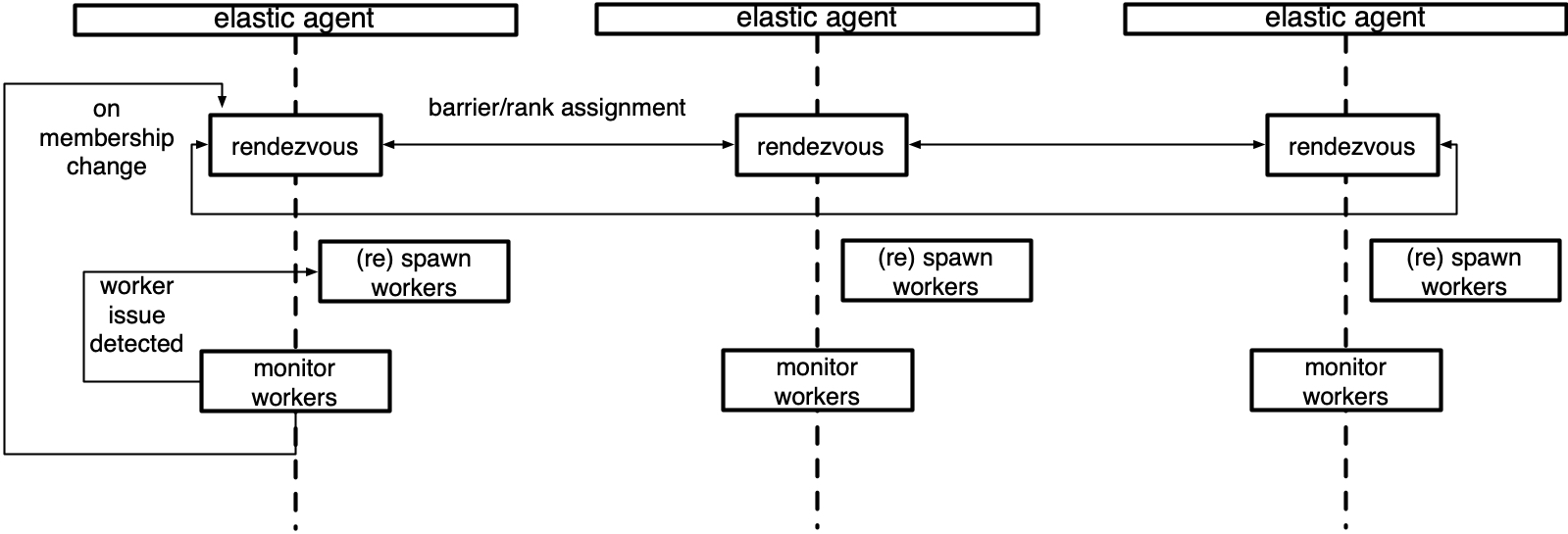
Concepts#
本节描述了与理解 agent 在 torchelastic 中的作用相关的高层类和概念。
- class torch.distributed.elastic.agent.server.ElasticAgent[source]#
负责管理一个或多个工作进程的 Agent 进程。
工作进程被假定为标准的分布式 PyTorch 脚本。当工作进程由 Agent 创建时,Agent 提供必要的信息,以便工作进程能够正确地初始化一个 PyTorch 进程组。
确切的部署拓扑和 Agent 与工作进程的比例取决于 Agent 的具体实现和用户的作业放置偏好。例如,要在 GPU 上运行具有 8 个训练器的分布式训练作业(每个 GPU 一个),可以
使用 8 个 x 单 GPU 实例,每个实例放置一个 Agent,管理每个 Agent 的 1 个工作进程。
使用 4 个 x 双 GPU 实例,每个实例放置一个 Agent,管理每个 Agent 的 2 个工作进程。
使用 2 个 x 四 GPU 实例,每个实例放置一个 Agent,管理每个 Agent 的 4 个工作进程。
使用 1 个 x 8 GPU 实例,每个实例放置一个 Agent,管理每个 Agent 的 8 个工作进程。
用法
group_result = agent.run() if group_result.is_failed(): # workers failed failure = group_result.failures[0] logger.exception("worker 0 failed with exit code : %s", failure.exit_code) else: return group_result.return_values[0] # return rank 0's results
- class torch.distributed.elastic.agent.server.WorkerSpec(role, local_world_size, rdzv_handler, fn=None, entrypoint=None, args=(), max_restarts=3, monitor_interval=0.1, master_port=None, master_addr=None, local_addr=None, event_log_handler='null', numa_options=None)[source]#
关于特定类型工作进程的蓝图信息。
对于给定的角色,必须只有一个 WorkerSpec。WorkerSpec 预计在所有节点(机器)上都是同质的,即每个节点运行相同数量的特定 Spec 的工作进程。
- 参数
role (str) – 用户定义的 Spec 工作进程的角色
local_world_size (int) – 要运行的本地工作进程数量
args (tuple) – 传递给
entrypoint的参数rdzv_handler (RendezvousHandler) – 处理此组工作进程的 rdzv
max_restarts (int) – 工作进程的最大重试次数
monitor_interval (float) – 每
n秒监控一次工作进程的状态master_port (Optional[int]) – rank 0 上 c10d 存储的固定端口,如果未指定,则选择一个随机的可用端口
master_addr (Optional[str]) – rank 0 上 c10d 存储的固定 master_addr,如果未指定,则选择 Agent rank 0 的主机名
redirects – 将标准流重定向到文件,通过传递映射选择性地重定向特定本地 rank 的流
tee – 将指定标准流(或多个流)复制到控制台 + 文件,通过传递映射选择性地为特定本地 rank 进行复制,该选项优先于
redirects设置。event_log_handler (str) – 事件日志处理程序在 elastic/events/handlers.py 中注册的名称。
- class torch.distributed.elastic.agent.server.WorkerState(value)[source]#
WorkerGroup的状态。WorkerGroup 中的工作进程作为一个整体改变状态。如果 WorkerGroup 中的单个工作进程失败,则整个组被视为失败。
UNKNOWN - agent lost track of worker group state, unrecoverable INIT - worker group object created not yet started HEALTHY - workers running and healthy UNHEALTHY - workers running and unhealthy STOPPED - workers stopped (interrupted) by the agent SUCCEEDED - workers finished running (exit 0) FAILED - workers failed to successfully finish (exit !0)
工作进程组从初始
INIT状态开始,然后进展到HEALTHY或UNHEALTHY状态,最终达到终止状态SUCCEEDED或FAILED。工作进程组可以被 Agent 中断并暂时置于
STOPPED状态。处于STOPPED状态的工作进程将在不久的将来由 Agent 重新安排启动。将工作进程置于STOPPED状态的一些例子包括:工作进程组失败 | 检测到不健康
检测到成员资格变化
当对工作进程组执行操作(启动、停止、rdzv、重试等)失败,并且导致操作部分应用于工作进程组时,状态将为
UNKNOWN。通常这发生在 Agent 状态变更事件期间未捕获/未处理的异常。Agent 不期望恢复处于UNKNOWN状态的工作进程组,最好是自行终止,让作业管理器重新尝试该节点。
- class torch.distributed.elastic.agent.server.Worker(local_rank, global_rank=-1, role_rank=-1, world_size=-1, role_world_size=-1)[source]#
一个工作进程实例。
将此与
WorkerSpec进行对比,后者代表工作进程的规范。一个Worker是从一个WorkerSpec创建的。Worker之于WorkerSpec就像对象之于类。工作进程的
id由ElasticAgent的特定实现来解释。对于本地 Agent,它可能是工作进程的pid (int),对于远程 Agent,它可能被编码为host:port (string)。
Implementations#
以下是 torchelastic 提供的 Agent 实现。
- class torch.distributed.elastic.agent.server.local_elastic_agent.LocalElasticAgent(spec, logs_specs, start_method='spawn', exit_barrier_timeout=300, log_line_prefix_template=None)[source]#
一个
torchelastic.agent.server.ElasticAgent的实现,该实现处理主机本地工作进程。此 Agent 按主机部署,并配置为生成
n个工作进程。在使用 GPU 时,n映射到主机上可用的 GPU 数量。本地 Agent 不与其他主机上的本地 Agent 通信,即使工作进程可能进行跨主机通信。工作进程 ID 被解释为本地进程。Agent 将所有工作进程作为一个单元启动和停止。
传递给工作进程函数的工作进程函数和参数必须与 Python 的 multiprocessing 兼容。要将 multiprocessing 数据结构传递给工作进程,您可以创建与指定
start_method相同的 multiprocessing 上下文中的数据结构,并将其作为函数参数传递。exit_barrier_timeout指定等待其他 Agent 完成的时间(以秒为单位)。这充当了处理工作进程不同时完成的情况的安全网,以防止 Agent 将过早完成的工作进程视为缩减事件。强烈建议用户代码处理确保工作进程同步终止,而不是依赖 exit_barrier_timeout。如果 Agent 进程中定义了环境变量
TORCHELASTIC_ENABLE_FILE_TIMER且其值为 1,则可以在`LocalElasticAgent`中启用基于命名管道的看门狗。另外,可以设置另一个环境变量`TORCHELASTIC_TIMER_FILE`,其中包含命名管道的唯一文件名。如果未设置环境变量`TORCHELASTIC_TIMER_FILE`,`LocalElasticAgent`将内部创建唯一文件名并将其设置为环境变量`TORCHELASTIC_TIMER_FILE`,并且此环境变量将被传播到工作进程,以便它们可以连接到`LocalElasticAgent`使用的相同命名管道。日志将写入指定的日志目录。默认情况下,每行日志将以
[${role_name}${local_rank}]:(例如[trainer0]: foobar)作为前缀。可以通过将 模板字符串 作为log_line_prefix_template参数传递来定制日志前缀。运行时会替换以下宏(标识符):${role_name}, ${local_rank}, ${rank}。例如,要将每行日志前缀为全局 rank 而非本地 rank,请设置log_line_prefix_template = "[${rank}]:。示例启动函数
def trainer(args) -> str: return "do train" def main(): start_method="spawn" shared_queue= multiprocessing.get_context(start_method).Queue() spec = WorkerSpec( role="trainer", local_world_size=nproc_per_process, entrypoint=trainer, args=("foobar",), ...<OTHER_PARAMS...>) agent = LocalElasticAgent(spec, start_method) results = agent.run() if results.is_failed(): print("trainer failed") else: print(f"rank 0 return value: {results.return_values[0]}") # prints -> rank 0 return value: do train
示例启动二进制文件
def main(): spec = WorkerSpec( role="trainer", local_world_size=nproc_per_process, entrypoint="/usr/local/bin/trainer", args=("--trainer-args", "foobar"), ...<OTHER_PARAMS...>) agent = LocalElasticAgent(spec) results = agent.run() if not results.is_failed(): print("binary launches do not have return values")
Extending the Agent#
要扩展 Agent,可以直接实现 ElasticAgent,但我们建议您改用 SimpleElasticAgent,它提供了大部分脚手架,只留下几个特定的抽象方法供您实现。
- class torch.distributed.elastic.agent.server.SimpleElasticAgent(spec, exit_barrier_timeout=300)[source]#
一个管理一个特定类型工作进程角色的
ElasticAgent。一个
ElasticAgent,它管理一个WorkerSpec的工作进程(WorkerGroup),例如一种特定类型的工作进程角色。- _assign_worker_ranks(store, group_rank, group_world_size, spec)[source]#
确定工作进程的正确 rank。
快速路径:当所有工作进程都具有相同的角色和 world size 时。我们计算全局 rank 为 group_rank * group_world_size + local_rank。并且 role_world_size 与 global_world_size 相同。此情况下不使用 TCP 存储。仅当用户设置环境变量 TORCH_ELASTIC_WORKER_IDENTICAL 为 1 时才启用此选项。
时间复杂度:每个工作进程 O(1),整体 O(1)
慢速路径:当工作进程具有不同的角色和 world size 时。我们使用以下算法
每个 Agent 将其配置(group_rank、group_world_size、num_workers)写入公共存储。
rank 0 Agent 从存储中读取所有 role_info 并确定每个 Agent 的工作进程 rank。
确定全局 rank:工作进程的全局 rank 通过累加其前面的所有工作进程的 local_world_size 来计算。出于效率原因,每个工作进程被分配一个基础全局 rank,使其工作进程位于 [base_global_rank, base_global_rank + local_world_size) 范围内。
确定角色 rank:使用第 3 点中的算法确定角色 rank,但计算 rank 时是相对于角色名称的。
rank 0 Agent 将分配的 rank 写入存储。
每个 Agent 从存储中读取分配的 rank。
时间复杂度:每个工作进程 O(1),rank0 O(n),整体 O(n)
- _exit_barrier()[source]#
定义一个屏障,保持 Agent 进程存活直到所有工作进程完成。
等待
exit_barrier_timeout秒,直到所有 Agent 完成其本地工作进程的执行(无论成功与否)。这充当了处理用户脚本终止时间不同的安全措施。
- _initialize_workers(worker_group)[source]#
为 worker_group 启动一组新的工作进程。
本质上,这是一个 rendezvous,然后是一个
start_workers。调用者应首先调用_stop_workers()来停止正在运行的工作进程,然后再调用此方法。乐观地将刚启动的工作进程组的状态设置为
HEALTHY,并将实际的状态监控委托给_monitor_workers()方法。
- _rendezvous(worker_group)[source]#
为 worker spec 指定的工作进程运行 rendezvous。
为工作进程分配新的全局 rank 和 world size。更新工作进程组的 rendezvous 存储。
- abstract _shutdown(death_sig=Signals.SIGTERM)[source]#
清理 Agent 工作期间分配的任何资源。
- 参数
death_sig (Signals) – 发送给子进程的信号,默认为 SIGTERM
- class torch.distributed.elastic.agent.server.api.RunResult(state, return_values=<factory>, failures=<factory>)[source]#
返回工作进程执行的结果。
Run 结果遵循“全有或全无”策略,即当且仅当此 Agent 管理的所有本地工作进程都成功完成时,运行才算成功。
如果结果成功(例如
is_failed() = False),则return_values字段包含THIS Agent 管理的工作进程的输出(返回值),按其全局 rank 映射。也就是说result.return_values[0]是全局 rank 0 的返回值。注意
return_values仅在工作进程入口点是函数时才有意义。指定为二进制入口点的进程没有规范的返回值,并且return_values字段没有意义,可能为空。如果
is_failed()返回True,则failures字段包含失败信息,同样按失败工作进程的全局 rank 映射。return_values和failures中的键是互斥的,也就是说,工作进程的最终状态只能是成功或失败之一。被 Agent 根据 Agent 的重启策略有意终止的工作进程,在return_values或failures中均不表示。
Watchdog in the Agent#
如果 Agent 进程中定义了环境变量 TORCHELASTIC_ENABLE_FILE_TIMER 且其值为 1,则可以在 LocalElasticAgent 中启用基于命名管道的看门狗。另外,可以设置另一个环境变量 TORCHELASTIC_TIMER_FILE,其中包含命名管道的唯一文件名。如果未设置环境变量 TORCHELASTIC_TIMER_FILE,LocalElasticAgent 将内部创建唯一文件名并将其设置为环境变量 TORCHELASTIC_TIMER_FILE,并且此环境变量将被传播到工作进程,以便它们可以连接到 LocalElasticAgent 使用的相同命名管道。
Health Check Server#
如果 Agent 进程中定义了环境变量 TORCHELASTIC_HEALTH_CHECK_PORT,则可以在 LocalElasticAgent 中启用健康检查监控服务器。为健康检查服务器提供了接口,可以通过启动指定端口的 TCP/HTTP 服务器进行扩展。此外,健康检查服务器将具有检查看门狗是否存活的回调。
- class torch.distributed.elastic.agent.server.health_check_server.HealthCheckServer(alive_callback, port, timeout)[source]#
健康检查监控服务器的接口,可以通过在指定端口启动 TCP/HTTP 服务器来扩展。
- 参数
