AOTInductor 调试指南#
创建于:2025年8月14日 | 最后更新于:2025年8月14日
如果您在使用 AOT Inductor 时遇到 CUDA 非法内存访问 (IMA) 错误,本指南将提供一个系统性的方法来调试此类错误。AOT Inductor 是 PT2 堆栈的一部分,类似于 torch.compile,但它会生成可以在 C++ 环境中运行的编译产物。CUDA 非法内存错误可能不会确定性地发生,甚至有时会短暂出现。
总的来说,调试 CUDA IMA 错误有三个主要步骤:
健全性检查:在深入调试之前,使用基本的调试标志来捕获常见问题。
精确定位 CUDA IMA:使错误具有确定性,并识别出有问题的内核。
识别有问题的内核:使用中间值调试来检查内核的输入和输出。
第一步:健全性检查#
在可靠复现错误之前,请尝试使用一些现有的调试标志。
AOTI_RUNTIME_CHECK_INPUTS=1
TORCHINDUCTOR_NAN_ASSERTS=1
这些标志在编译时(更准确地说,是在代码生成时)生效。
AOTI_RUNTIME_CHECK_INPUTS=1检查输入是否满足编译时使用的相同 guard 集合。有关更多详细信息,请参阅 torch.compile 故障排除。TORCHINDUCTOR_NAN_ASSERTS=1在 Inductor 的每个内核前后添加代码生成,以检查 NaN。
第二步:精确定位 CUDA IMA#
一个难题是 CUDA IMA 错误可能不会确定性地发生。它们可能发生在不同的位置,有时甚至根本不发生(尽管这仅仅意味着数值上存在潜在的错误)。使用以下两个标志,我们可以确定性地触发错误:
PYTORCH_NO_CUDA_MEMORY_CACHING=1
CUDA_LAUNCH_BLOCKING=1
这些标志在运行时生效。
PYTORCH_NO_CUDA_MEMORY_CACHING=1禁用 PyTorch 的缓存分配器,该分配器会分配比实际需要更多的缓冲区以减少缓冲区分配次数。这通常是 CUDA 非法内存访问错误表现不确定的原因。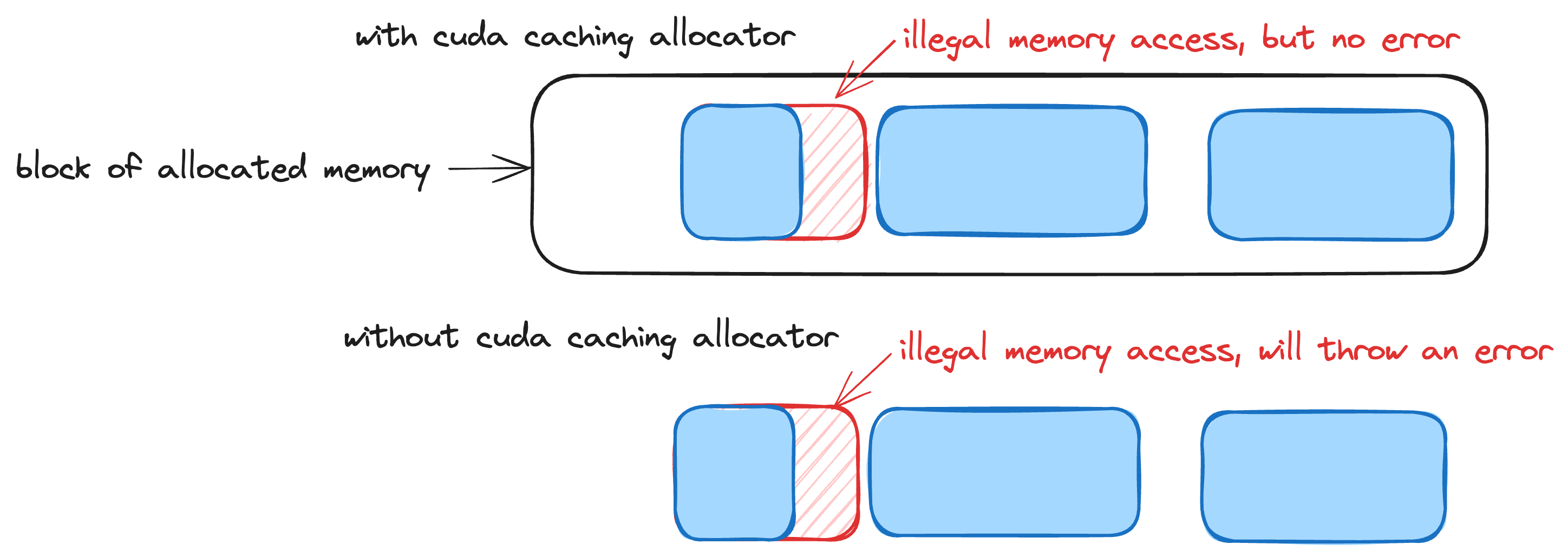 图:PyTorch 的缓存分配器如何掩盖 CUDA 非法内存访问错误
图:PyTorch 的缓存分配器如何掩盖 CUDA 非法内存访问错误CUDA_LAUNCH_BLOCKING=1强制内核一次一个地启动。如果没有这个标志,我们可能会收到著名的“CUDA 内核错误可能在其他 API 调用处异步报告”警告,因为内核是异步启动的。
第三步:使用中间值调试器识别有问题的内核#
AOTI 中间值调试器可以帮助精确定位有问题的内核,并获取该内核输入和输出的信息。
首先,使用
AOT_INDUCTOR_DEBUG_INTERMEDIATE_VALUE_PRINTER=3
此标志在编译时生效,并在运行时逐个打印内核。结合之前的标志,这将让我们知道在错误发生前启动的是哪个内核。
然而,需要注意的是,仅仅因为错误发生在某个内核中,并不意味着该内核本身有问题。例如,可能是一个较早的内核有问题,产生了错误的输出。因此,下一步自然是检查该有问题的内核的输入。
AOT_INDUCTOR_FILTERED_KERNELS_TO_PRINT="triton_poi_fused_add_ge_logical_and_logical_or_lt_231,_add_position_embeddings_kernel_5" AOT_INDUCTOR_DEBUG_INTERMEDIATE_VALUE_PRINTER=2
用于过滤内核打印的环境变量包含您要检查的内核名称。如果内核的输入不符合预期,则您需要检查生成错误输入的那个内核。
附加调试工具#
日志记录和跟踪#
tlparse / TORCH_TRACE:提供完整的输出代码供检查,并记录使用的 guard 集合。有关更多详细信息,请参阅 tlparse / TORCH_TRACE。
TORCH_LOGS:使用
TORCH_LOGS="+inductor,output_code"来查看更多 PT2 内部日志。有关更多详细信息,请参阅 TORCH_LOGS。TORCH_SHOW_CPP_STACKTRACES:设置
TORCH_SHOW_CPP_STACKTRACES=1以可能看到更多的堆栈跟踪。
