Dynamo 概述#
创建于: 2025年6月13日 | 最后更新于: 2025年6月13日
在阅读本节之前,请先阅读 torch.compiler。
TorchDynamo(或简称 Dynamo)是一个 Python 级别的即时(JIT)编译器,旨在加速未修改的 PyTorch 程序。Dynamo 挂钩到 CPython 的帧评估 API(PEP 523),在 Python 字节码执行前动态修改它。它重写 Python 字节码,将一系列 PyTorch 操作提取到一个 FX Graph 中,然后使用可定制的后端进行编译。它通过字节码分析创建这个 FX Graph,并旨在将 Python 执行与编译后的后端结合起来,以获得最佳的双重优势——可用性和性能。
Dynamo 使通过单行装饰器 `torch._dynamo.optimize()`(为方便起见由 `torch.compile()` 包装)轻松尝试不同的编译器后端来加速 PyTorch 代码。
下图演示了 PyTorch 在有和没有 `torch.compile` 的情况下是如何工作的
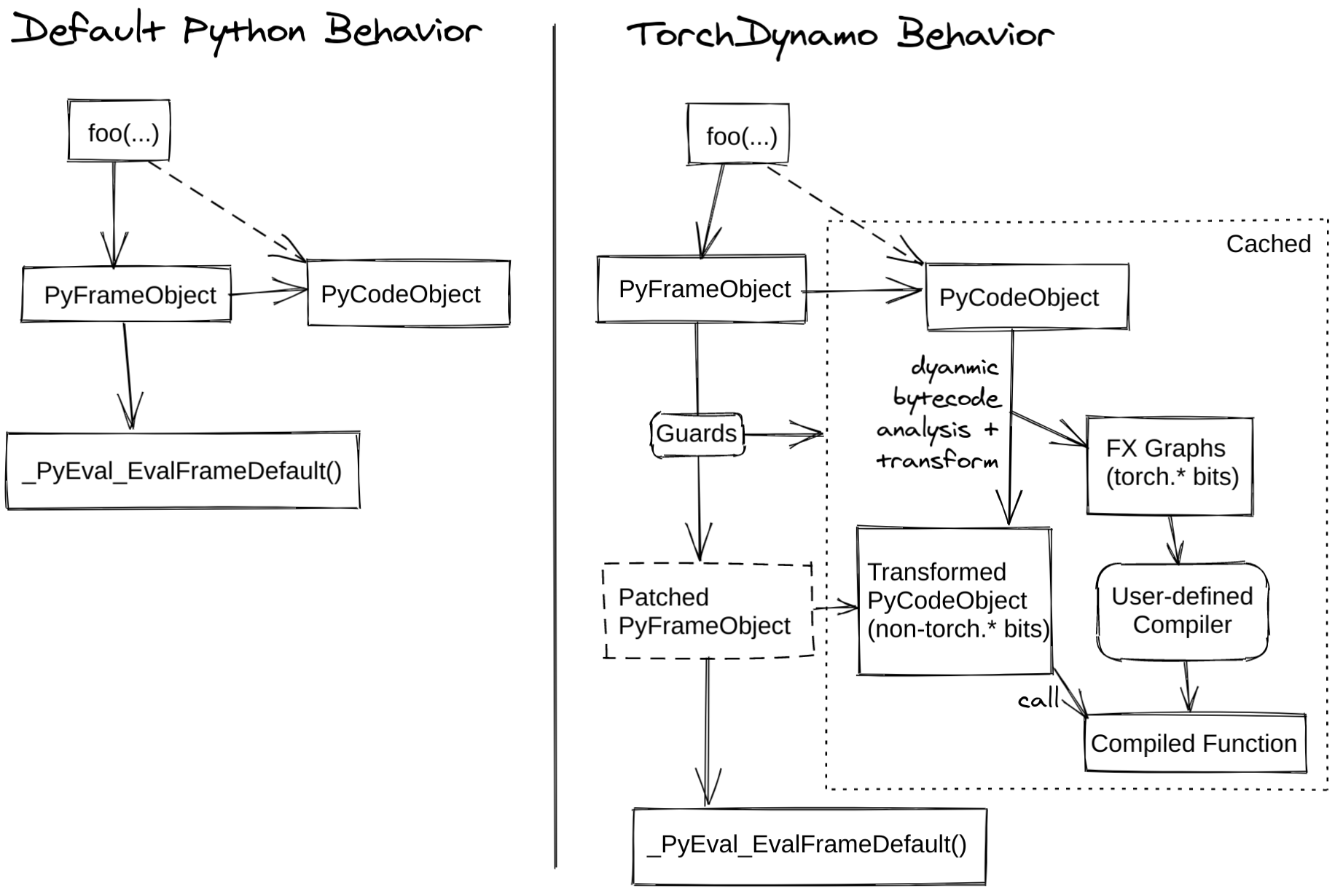
`TorchInductor` 是 `Dynamo Graph` 支持的后端之一,它将图转换为用于 GPU 的 Triton 或用于 CPU 的 C++/OpenMP。我们有一个 训练性能仪表盘,提供了不同训练后端的性能比较。您可以在 PyTorch dev-discuss 上的 TorchInductor 帖子 中阅读更多内容。
有关深入的概述,请阅读以下章节,观看深度解析视频,并查看 dev-discuss 主题。
Dynamo 内部结构#
作者:Jason Ansel 和 Kaichao You
本节将介绍 Dynamo 的一些内部结构,并演示 Dynamo 的工作原理。
什么是 guard?#
Dynamo 实时运行,并根据动态属性对图进行特化。下面是一个使用 Dynamo 的基本示例。可以使用 `torchdynamo.optimize` 装饰函数或方法来启用 Dynamo 优化。
from typing import List
import torch
from torch import _dynamo as torchdynamo
def my_compiler(gm: torch.fx.GraphModule, example_inputs: List[torch.Tensor]):
print("my_compiler() called with FX graph:")
gm.graph.print_tabular()
return gm.forward # return a python callable
@torchdynamo.optimize(my_compiler)
def toy_example(a, b):
x = a / (torch.abs(a) + 1)
if b.sum() < 0:
b = b * -1
return x * b
for _ in range(100):
toy_example(torch.randn(10), torch.randn(10))
例如,上面的第一个图具有以下 guards:
GUARDS:
hasattr(L['a'], '_dynamo_dynamic_indices') == False
hasattr(L['b'], '_dynamo_dynamic_indices') == False
utils_device.CURRENT_DEVICE == None
___skip_backend_check() or ___current_backend() == ___lookup_backend(140355900538256)
check_tensor(L['a'], Tensor, DispatchKeySet(CPU, BackendSelect, ADInplaceOrView, AutogradCPU), torch.float32, device=None, requires_grad=False, size=[10], stride=[1])
check_tensor(L['b'], Tensor, DispatchKeySet(CPU, BackendSelect, ADInplaceOrView, AutogradCPU), torch.float32, device=None, requires_grad=False, size=[10], stride=[1])
如果任何一个 guard 失败,图将被重新捕获和重新编译。其中有趣的 guard 是 `check_tensor`,它会检查以下 `torch.Tensor` 属性:
张量的 Python 类(张量子类化等)
dtype
device
requires_grad
dispatch_key(应用了线程局部包含/排除)
ndim
sizes*
strides*
完整的特化模式允许后端编译器假定一个完全静态的图。不幸的是,大多数后端都需要这样。返回动态形状的运算符在非动态形状模式下会触发图中断。
Dynamo 在做什么?#
如果您想更好地理解 Dynamo 在做什么,可以运行您的代码:
TORCH_LOGS="+dynamo,guards,bytecode"
如果您不熟悉 Python 字节码,可以添加一个反编译器钩子,将字节码反编译为人类可读的源代码。一个可用的工具是 depyf。如果您尚未安装 `depyf`,请运行 `pip install depyf`。然后在运行任何代码之前,添加以下代码来安装反编译钩子:
import depyf
depyf.install()
这段代码会触发有用的(但很啰嗦的)打印输出。
例如,`toy_example` 中第一个图的打印输出是:
__compiled_fn_0 <eval_with_key>.1
opcode name target args kwargs
------------- ------- ------------------------------------------------------ ---------------- --------
placeholder a a () {}
placeholder b b () {}
call_function abs_1 <built-in method abs of type object at 0x7f9ca082f8a0> (a,) {}
call_function add <built-in function add> (abs_1, 1) {}
call_function truediv <built-in function truediv> (a, add) {}
call_method sum_1 sum (b,) {}
call_function lt <built-in function lt> (sum_1, 0) {}
output output output ((truediv, lt),) {}
ORIGINAL BYTECODE toy_example example.py line 12
14 0 LOAD_FAST 0 (a)
2 LOAD_GLOBAL 0 (torch)
4 LOAD_METHOD 1 (abs)
6 LOAD_FAST 0 (a)
8 CALL_METHOD 1
10 LOAD_CONST 1 (1)
12 BINARY_ADD
14 BINARY_TRUE_DIVIDE
16 STORE_FAST 2 (x)
15 18 LOAD_FAST 1 (b)
20 LOAD_METHOD 2 (sum)
22 CALL_METHOD 0
24 LOAD_CONST 2 (0)
26 COMPARE_OP 0 (<)
28 POP_JUMP_IF_FALSE 19 (to 38)
16 30 LOAD_FAST 1 (b)
32 LOAD_CONST 3 (-1)
34 BINARY_MULTIPLY
36 STORE_FAST 1 (b)
17 >> 38 LOAD_FAST 2 (x)
40 LOAD_FAST 1 (b)
42 BINARY_MULTIPLY
44 RETURN_VALUE
MODIFIED BYTECODE toy_example example.py line 12
12 0 LOAD_GLOBAL 3 (__compiled_fn_0)
2 LOAD_FAST 0 (a)
4 LOAD_FAST 1 (b)
6 CALL_FUNCTION 2
8 UNPACK_SEQUENCE 2
10 STORE_FAST 2 (x)
12 POP_JUMP_IF_FALSE 12 (to 24)
14 LOAD_GLOBAL 4 (__resume_at_30_1)
16 LOAD_FAST 1 (b)
18 LOAD_FAST 2 (x)
20 CALL_FUNCTION 2
22 RETURN_VALUE
>> 24 LOAD_GLOBAL 5 (__resume_at_38_2)
26 LOAD_FAST 1 (b)
28 LOAD_FAST 2 (x)
30 CALL_FUNCTION 2
32 RETURN_VALUE
possible source code:
def toy_example(a, b):
__temp_1 = __compiled_fn_0(a, b)
x = __temp_1[0]
if __temp_1[1]:
return __resume_at_30_1(b, x)
return __resume_at_38_2(b, x)
If you find the decompiled code is wrong,please submit an issue at https://github.com/youkaichao/depyf/issues.
顶部是 FX 图。接下来是函数的原始字节码,然后是 Dynamo 生成的修改后的字节码,以及用于参考的反编译源代码。最后是上面介绍的 guards。
在修改后的字节码中,`__compiled_fn_0` 是 `my_compiler()`(编译后的图)的返回值。`__resume_at_30_1` 和 `__resume_at_38_2` 都是生成的继续函数,用于在图中断后恢复执行(在字节码偏移量 30 和 38 处)。这些函数中的每一个都采用以下形式:
__resume_at_<offset>:
... restore stack state if needed ...
JUMP_ABSOLUTE <offset> into toy_example
... original bytecode of toy_example ...
通过生成这个 `resume_at` 函数,我们强制函数剩余部分在一个新的 Python 帧中执行,该帧会递归地触发 Dynamo 在执行第一次到达该点时重新开始捕获。
如何检查 Dynamo 生成的构件?#
要检查 Dynamo 生成的构件,有一个 API `torch._dynamo.eval_frame._debug_get_cache_entry_list`,它可以从函数的 `__code__` 对象中检索编译后的代码和 guards。一个编译后的函数可以有多个缓存条目,每个缓存条目包含一个用于检查 guards 的生成函数,以及一个 `types.CodeType` 对象,用于在满足 guarding 条件时执行代码。
from torch._dynamo.eval_frame import _debug_get_cache_entry_list, innermost_fn
cache_entries = _debug_get_cache_entry_list(innermost_fn(toy_example))
cache_entry = cache_entries[0]
guard, code = cache_entry.check_fn, cache_entry.code
# the guard takes the local variables of an input frame, and tells whether a re-compilation should be triggered.
import dis
dis.dis(guard)
dis.dis(code)
如果您了解 Python 字节码,就能理解上面的输出。
对于 guard 函数,无需检查字节码。我们可以直接访问其 guarding 条件:
for code_part in guard.code_parts:
print(code_part)
输出是:
___guarded_code.valid
___check_global_state()
hasattr(L['a'], '_dynamo_dynamic_indices') == False
hasattr(L['b'], '_dynamo_dynamic_indices') == False
utils_device.CURRENT_DEVICE == None
___skip_backend_check() or ___current_backend() == ___lookup_backend(140215810860528)
___check_tensors(L['a'], L['b'], tensor_check_names=tensor_check_names)
只有当所有条件都满足时,guard 函数才返回 true,并且执行编译后的代码。
对于编译后的代码,我们无法直接访问其源代码,只能对其进行反编译。
from depyf import decompile
print(decompile(code))
输出是:
def toy_example(a, b):
__temp_1 = __compiled_fn_0(a, b)
x = __temp_1[0]
if __temp_1[1]:
return __resume_at_30_1(b, x)
return __resume_at_38_2(b, x)
代码中引用的某些名称是:
编译后的函数,存储在包含原始函数 `toy_example` 的模块的全局命名空间中。这些名称包括 `__compiled_fn_0` / `__resume_at_30_1` / `__resume_at_38_2`。
用于检查 guards 的闭包变量。名称可以从 `guard.__code__.co_freevars` 访问,值存储在 `guard.__closure__` 中。这些名称包括 `___guarded_code` / `___is_grad_enabled` / `___are_deterministic_algorithms_enabled` / `___is_torch_function_enabled` / `utils_device` / `___check_tensors` / `tensor_check_names`。
`guard` 函数的参数 `L`。这是一个字典,将 `toy_example` 的参数名映射到其值。这仅在函数调用时可用,此时会涉及帧评估 API。简而言之,`L` 是一个结构为 `{'a': value_a, 'b': value_b}` 的字典。因此,您可以看到代码使用 `L['a']` 来引用输入变量 `a`。
在编译后的 `toy_example` 代码中显示了图中断,我们必须使用 Python 解释器来选择以下图进行执行。
请注意,我们传递了一个简单的 `my_compiler` 函数作为后端编译器,因此子图代码 `__resume_at_38_2`、`__resume_at_30_1` 和 `__compiled_fn_0` 仍然是 Python 代码。这也可以进行检查(请忽略函数名,只使用函数签名和函数体代码)。
print("source code of __compiled_fn_0:")
print(innermost_fn(__compiled_fn_0).__self__.code)
print("=" * 60)
print("source code of __resume_at_30_1:")
print(decompile(__resume_at_30_1))
print("=" * 60)
print("source code of __resume_at_38_2:")
print(decompile(__resume_at_38_2))
source code of __compiled_fn_0:
def forward(self, L_a_ : torch.Tensor, L_b_ : torch.Tensor):
l_a_ = L_a_
l_b_ = L_b_
abs_1 = torch.abs(l_a_)
add = abs_1 + 1; abs_1 = None
truediv = l_a_ / add; l_a_ = add = None
sum_1 = l_b_.sum(); l_b_ = None
lt = sum_1 < 0; sum_1 = None
return (truediv, lt)
# To see more debug info, please use ``graph_module.print_readable()``
============================================================
source code of __resume_at_30_1:
def <resume in toy_example>(b, x):
b = b * -1
return x * b
============================================================
source code of __resume_at_38_2:
def <resume in toy_example>(b, x):
return x * b
但是,如果我们使用 `inductor` 等内置后端,子图代码将被编译成 GPU 的 CUDA 内核或 CPU 的 C++ 代码。
总而言之,编译后的代码在概念上等同于以下代码:
def compiled_example(a, b):
L = {'a': a, 'b': b}
for guard, code in get_cache_entries():
if guard(L):
return code(a, b)
recompile_and_add_another_cache_entry()
下图演示了 `torch.compile` 如何转换和优化用户编写的代码:它首先从用户编写的函数中提取计算图,将这些图编译成优化后的函数,然后将它们组装成一个新函数,该函数在功能上等同于用户编写的代码,但经过优化,具有良好的计算速度。
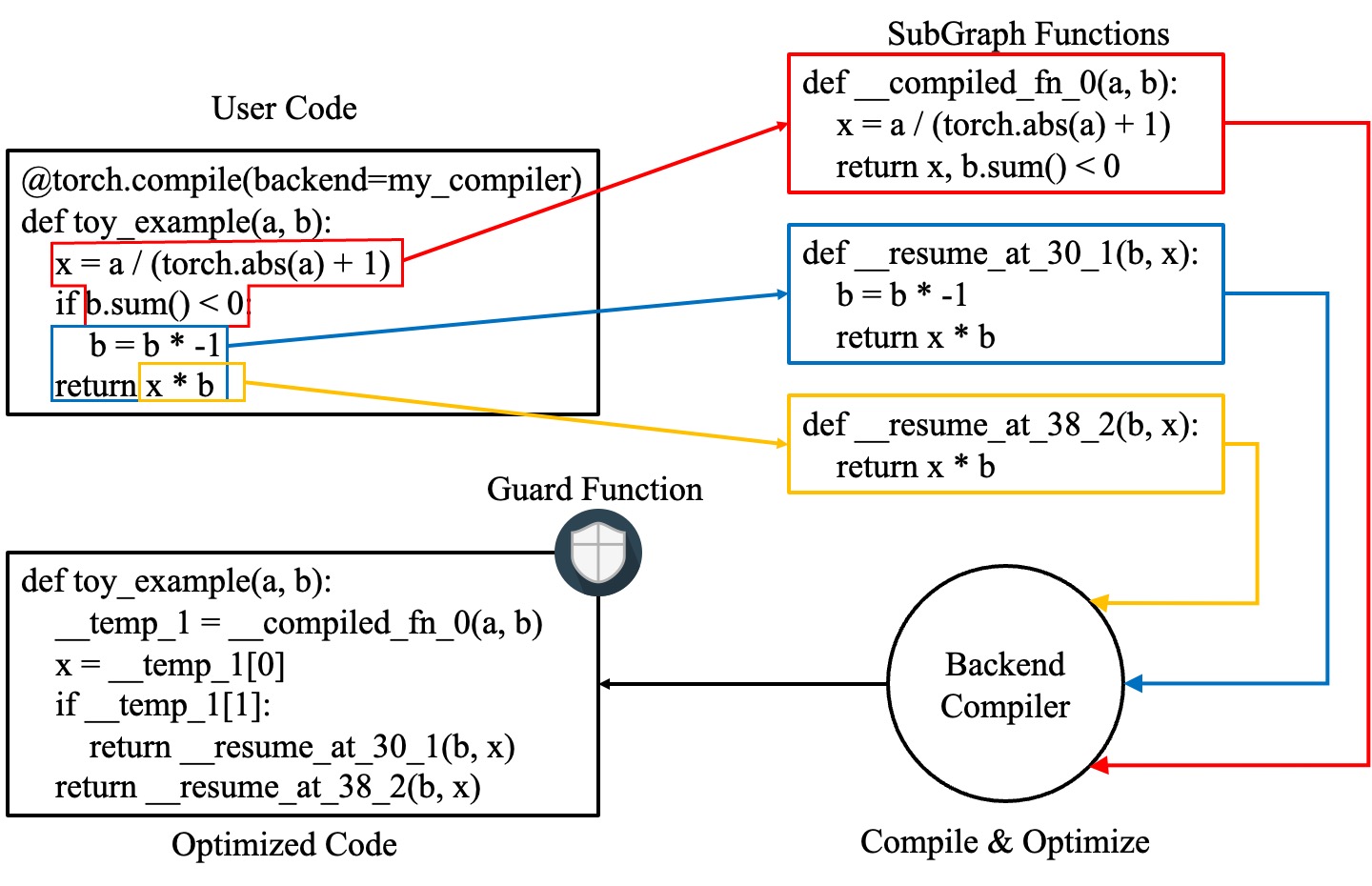
要详细了解所有这些的内部实现,请参阅 Dynamo Deep-Dive。
