MultiplicativeLR#
- class torch.optim.lr_scheduler.MultiplicativeLR(optimizer, lr_lambda, last_epoch=-1)[源代码]#
将每个参数组的学习率乘以指定函数中给出的因子。
当 last_epoch=-1 时,将初始学习率设置为 lr。
- 参数
示例
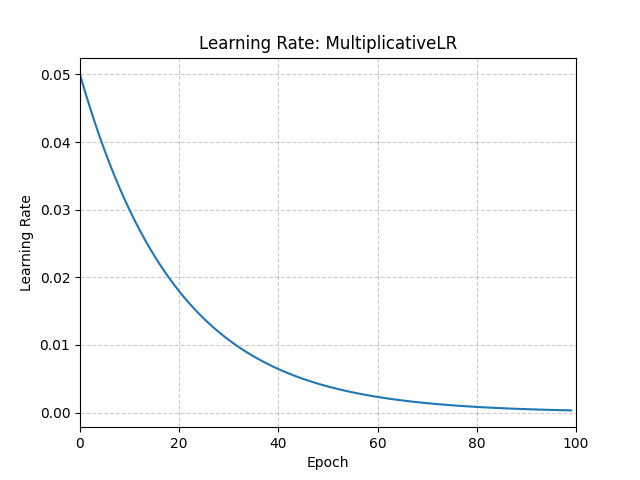
>>> lmbda = lambda epoch: 0.95 >>> scheduler = MultiplicativeLR(optimizer, lr_lambda=lmbda) >>> for epoch in range(100): >>> train(...) >>> validate(...) >>> scheduler.step()
- load_state_dict(state_dict)[源代码]#
加载调度器的状态。
- 参数
state_dict (dict) – scheduler 状态。应该是调用
state_dict()返回的对象。
