TorchDynamo API 用于细粒度跟踪#
创建日期:2023 年 7 月 28 日 | 最后更新日期:2025 年 6 月 16 日
注意
本文档中,torch.compiler.compile 和 torch.compile 可互换使用。这两个版本在您的代码中都有效。
torch.compile 对整个用户模型执行 TorchDynamo 跟踪。但是,模型代码中可能有一小部分无法被 torch.compiler 处理。在这种情况下,您可能希望禁用对该特定部分的编译器,同时对模型的其余部分进行编译。本节介绍用于定义您希望跳过编译的代码部分以及相关用例的现有 API。
您可以使用下表列出的 API 来定义可以禁用编译的代码部分。
API |
描述 |
何时使用? |
|---|---|---|
|
禁用装饰函数及其递归调用的函数中的 Dynamo。 |
非常适合用于解决用户问题,如果模型的一小部分无法使用 |
|
禁止将标记的操作符包含在 TorchDynamo 图中。TorchDynamo 会导致图中断,并在急切(不编译)模式下运行操作符。这适用于操作符,而 |
此 API 非常适合用于调试和解决自定义操作符(如 |
|
注释的可调用对象将按原样进入 TorchDynamo 图。例如,对于 TorchDynamo 来说,它是一个黑盒。请注意,AOT Autograd 会对其进行跟踪,因此 |
此 API 对于模型中具有已知 TorchDynamo 难以支持的特性(如 hook 或 |
|
添加图中断。图中断之前的代码和之后的代码都会经过 TorchDynamo。 |
**很少用于部署** - 如果您认为需要此功能,则很可能需要 |
|
指示图是否作为 torch.compile() 或 torch.export() 的一部分执行/跟踪。 |
|
|
指示图是否通过 TorchDynamo 进行跟踪。它比 torch.compiler.is_compiling() 标志更严格,因为它仅在 TorchDynamo 被使用时设置为 True。 |
|
|
指示图是否通过 export 进行跟踪。它比 torch.compiler.is_compiling() 标志更严格,因为它仅在 torch.export 被使用时设置为 True。 |
torch.compiler.disable#
torch.compiler.disable 会禁用装饰函数帧及其从该装饰函数帧递归调用的所有函数帧的编译。
TorchDynamo 会拦截每个 Python 函数帧的执行。因此,假设您有一个代码结构(下图所示),其中函数 fn 调用函数 a_fn 和 b_fn。并且 a_fn 调用 aa_fn 和 ab_fn。当您使用 PyTorch 急切模式而不是 torch.compile 时,这些函数帧会按原样运行。使用 torch.compile 时,TorchDynamo 会拦截其中每个函数帧(以绿色表示)。
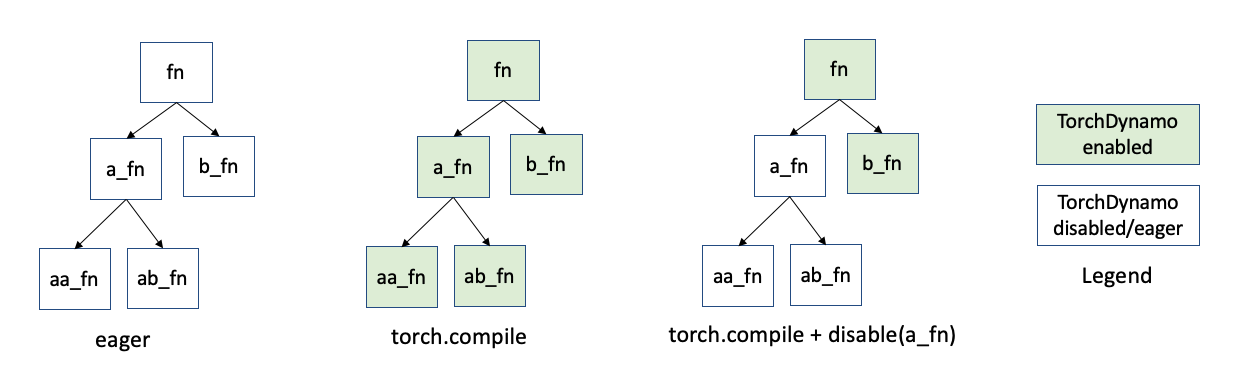
假设函数 a_fn 在 torch.compile 中出现问题。而这是模型的一个非关键部分。您可以在函数 a_fn 上使用 compiler.disable。如上所示,TorchDynamo 将停止检查源自 a_fn 调用的帧(白色表示原始 Python 行为)。
要跳过编译,您可以将有问题的函数用 @torch.compiler.disable 进行装饰。
如果您不想更改源代码,也可以使用非装饰器语法。但是,我们建议您尽可能避免这种风格。在这种情况下,您必须注意原始函数的所有用户都使用了已修补的版本。
torch._dynamo.disallow_in_graph#
torch._dynamo.disallow_in_graph 会禁止将某个操作符包含在 TorchDynamo 提取的图中,而不是禁止函数。请注意,这适用于操作符,而不是像 _dynamo.disable 那样的一般函数。
假设您使用 PyTorch 编译模型。TorchDynamo 能够提取图,但随后您发现下游编译器出现故障。例如,缺少元内核,或者某个操作符的 Autograd 分派键设置不正确。然后,您可以将该操作符标记为 disallow_in_graph,TorchDynamo 将导致图中断,并使用 PyTorch 急切模式运行该操作符。
需要注意的是,您必须找到相应的 Dynamo 级操作符,而不是 ATen 级操作符。有关更多信息,请参阅文档的局限性部分。
警告
torch._dynamo.disallow_in_graph 是一个全局标志。如果您正在比较不同的后端编译器,则在切换到其他编译器时,可能需要为被禁止的操作符调用 allow_in_graph。
torch.compiler.allow_in_graph#
torch.compiler.allow_in_graph 在相关函数帧具有一些已知难以支持的 TorchDynamo 特性(如 hook 和 autograd.Function)时非常有用,并且您确信下游 PyTorch 组件(如 AOTAutograd)可以安全地跟踪被装饰的函数。当一个函数被 allow_in_graph 装饰时,TorchDynamo 会将其视为黑盒,并按原样将其放入生成的图中。
警告
allow_in_graph 会完全跳过被装饰函数上的 TorchDynamo,省略所有 TorchDynamo 安全检查,包括图中断、处理闭包等。请谨慎使用 allow_in_graph。PyTorch 下游组件(如 AOTAutograd)依赖 TorchDynamo 来处理复杂的 Python 特性,但 allow_in_graph 会绕过 TorchDynamo。使用 allow_in_graph 可能会导致正确性问题和难以调试的问题。
局限性#
所有现有 API 都在 TorchDynamo 级别应用。因此,这些 API 只能看到 TorchDynamo 看到的内容。这可能导致令人困惑的情况。
例如,torch._dynamo.disallow_in_graph 不适用于 ATen 操作符,因为它们对 AOT Autograd 可见。例如,torch._dynamo.disallow_in_graph(torch.ops.aten.add) 在上面的示例中将不起作用。
