SequentialLR#
- class torch.optim.lr_scheduler.SequentialLR(optimizer, schedulers, milestones, last_epoch=-1)[source]#
包含一个调度器列表,这些调度器将在优化过程中按顺序调用。
具体来说,调度器将根据里程碑点进行调用,这些里程碑点应提供每个调度器在给定 epoch 被调用时的确切间隔。
- 参数
示例
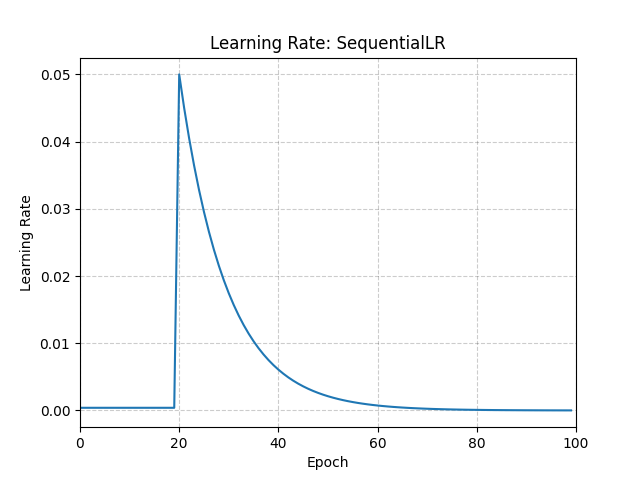
>>> # Assuming optimizer uses lr = 0.05 for all groups >>> # lr = 0.005 if epoch == 0 >>> # lr = 0.005 if epoch == 1 >>> # lr = 0.005 if epoch == 2 >>> # ... >>> # lr = 0.05 if epoch == 20 >>> # lr = 0.045 if epoch == 21 >>> # lr = 0.0405 if epoch == 22 >>> scheduler1 = ConstantLR(optimizer, factor=0.1, total_iters=20) >>> scheduler2 = ExponentialLR(optimizer, gamma=0.9) >>> scheduler = SequentialLR( ... optimizer, ... schedulers=[scheduler1, scheduler2], ... milestones=[20], ... ) >>> for epoch in range(100): >>> train(...) >>> validate(...) >>> scheduler.step()
- load_state_dict(state_dict)[source]#
加载调度器的状态。
- 参数
state_dict (dict) – 调度器状态。应该是一个从调用
state_dict()返回的对象。
