远程引用协议#
创建于:2019年11月20日 | 最后更新于:2025年04月27日
本文档描述了远程引用协议的设计细节,并回顾了不同场景下的消息流。请确保您熟悉 分布式 RPC 框架 后再继续阅读。
背景#
RRef 是 Remote REFerence 的缩写。它是一个指向本地或远程工作器上对象的引用,并在后台透明地处理引用计数。从概念上讲,它可以被视为一个分布式共享指针。应用程序可以通过调用 remote() 来创建 RRef。每个 RRef 由 remote() 调用的被调用方工作器(即所有者)拥有,并且可以被多个用户使用。所有者存储真实数据并跟踪全局引用计数。每个 RRef 都可以通过一个全局唯一的 RRefId 来标识,该 ID 在 remote() 调用发起方处创建时分配。
在所有者工作器上,只有一个 OwnerRRef 实例,其中包含真实数据,而在用户工作器上,可以根据需要创建任意数量的 UserRRef,并且 UserRRef 不持有数据。在所有者上的所有使用都将使用全局唯一的 RRefId 来检索唯一的 OwnerRRef 实例。当 UserRRef 用作 rpc_sync()、rpc_async() 或 remote() 调用中的参数或返回值时,将会创建一个 UserRRef,并且所有者将收到通知以更新引用计数。当全局上没有任何 UserRRef 实例并且所有者上也没有对 OwnerRRef 的引用时,OwnerRRef 及其数据将被删除。
假设#
RRef 协议的设计基于以下假设。
短暂的网络故障:RRef 设计通过重试消息来处理短暂的网络故障。它无法处理节点崩溃或永久性网络分区。当发生这些事件时,应用程序应关闭所有工作器,回滚到之前的检查点,然后恢复训练。
非幂等的 UDF:我们假设提供给
rpc_sync()、rpc_async()或remote()的用户函数 (UDF) 不是幂等的,因此不能重试。但是,内部 RRef 控制消息是幂等的,并在消息失败时重试。消息乱序投递:我们不假设任何节点对之间的消息投递顺序,因为发送方和接收方都使用了多个线程。消息的处理顺序没有保证。
RRef 生命周期#
该协议的目标是在适当的时候删除 OwnerRRef。删除 OwnerRRef 的合适时机是当没有活动的 UserRRef 实例,并且用户代码也不持有对 OwnerRRef 的引用时。棘手的部分是如何确定是否存在任何活动的 UserRRef 实例。
设计推理#
用户可以在三种情况下获得 UserRRef:
从所有者那里收到
UserRRef。从另一个用户那里收到
UserRRef。创建一个由另一个工作器拥有的新
UserRRef。
情况 1 最简单,所有者将 RRef 传递给用户,其中所有者调用 rpc_sync()、rpc_async() 或 remote() 并将其 RRef 作为参数。在这种情况下,用户端将创建一个新的 UserRRef。由于所有者是调用者,它可以轻松更新其在 OwnerRRef 上的本地引用计数。
唯一的要求是任何 UserRRef 在销毁时必须通知所有者。因此,我们需要第一个保证:
G1. 当任何 UserRRef 被删除时,所有者将收到通知。
由于消息可能延迟或乱序到达,我们需要另一个保证,以确保删除消息不会过早处理。如果 A 向 B 发送一条涉及 RRef 的消息,我们将 A 上的 RRef 称为(父 RRef),将 B 上的 RRef 称为(子 RRef)。
G2. 父 RRef 在被所有者确认子 RRef 之前不会被删除。
在情况 2 和 3 中,所有者可能只对 RRef 分叉图有部分或完全不知情。例如,RRef 可能在一个用户上创建,在所有者收到任何 RPC 调用之前,创建者用户可能已经与其他用户共享了 RRef,并且这些用户可能进一步共享 RRef。一个不变的规则是,任何 RRef 的分叉图始终是一棵树,因为分叉 RRef 总是会在被调用方(除非被调用方是所有者)上创建一个新的 UserRRef 实例,因此每个 RRef 都有一个唯一的父级。
所有者对树中任何 UserRRef 的视图有三个阶段:
1) unknown -> 2) known -> 3) deleted.
所有者对整个树的视图不断变化。当所有者认为没有活动的 UserRRef 实例时,它会删除其 OwnerRRef 实例,即当 OwnerRRef 被删除时,所有 UserRRef 实例可能已经被实际删除,也可能是未知的。危险的情况是某些分叉未知而其他分叉已被删除。
G2 默认保证了任何父 UserRRef 在所有者知道其所有子 UserRRef 实例之前不会被删除。但是,子 UserRRef 在所有者知道其父 UserRRef 之前可能已被删除。
考虑以下示例,其中 OwnerRRef 分叉到 A,然后 A 分叉到 Y,Y 分叉到 Z。
OwnerRRef -> A -> Y -> Z
如果 Z 的所有消息,包括删除消息,都在 Y 的消息之前被所有者处理。所有者将在知道 Y 存在之前就得知 Z 被删除。尽管如此,这并不会导致任何问题。因为,至少 Y 的一个祖先(A)会保持活动状态,它将阻止所有者删除 OwnerRRef。更具体地说,如果所有者不知道 Y,则由于 G2,A 不会被删除,并且所有者知道 A,因为它就是 A 的父级。
如果 RRef 是在用户上创建的,情况会稍微复杂一些。
OwnerRRef
^
|
A -> Y -> Z
如果 Z 对 UserRRef 调用 to_here(),那么在 Z 被删除时,所有者至少知道 A,因为否则 to_here() 将不会完成。如果 Z 没有调用 to_here(),则所有者可能在收到来自 A 和 Y 的任何消息之前就收到了 Z 的所有消息。在这种情况下,由于 OwnerRRef 的真实数据尚未创建,因此也没有什么可以删除的。这与 Z 完全不存在的情况相同。因此,仍然是可以的。
实现#
G1 通过在 UserRRef 析构函数中发送删除消息来实现。为了提供 G2,父 UserRRef 在被分叉时被放入一个上下文中,并由新的 ForkId 索引。父 UserRRef 仅在收到子节点的确认消息 (ACK) 后才从上下文中移除,而子节点仅在得到所有者的确认后才会发送 ACK。
协议场景#
现在让我们在四种场景中讨论上述设计如何转化为协议。
用户将 RRef 作为返回值与所有者共享#
import torch
import torch.distributed.rpc as rpc
# on worker A
rref = rpc.remote('B', torch.add, args=(torch.ones(2), 1))
# say the rref has RRefId 100 and ForkId 1
rref.to_here()
在这种情况下,UserRRef 在用户工作器 A 上创建,然后与远程消息一起传递给所有者工作器 B,然后 B 创建 OwnerRRef。remote() 方法立即返回,这意味着 UserRRef 可以在所有者知晓之前被分叉/使用。
在所有者端,当收到 remote() 调用时,它将创建 OwnerRRef,并返回一个 ACK 来确认 {100, 1}(RRefId, ForkId)。只有在收到此 ACK 后,A 才能删除其 UserRRef。这涉及 G1 和 G2。G1 是显而易见的。对于 G2,OwnerRRef 是 UserRRef 的子级,并且 UserRRef 在收到所有者的 ACK 之前不会被删除。

上图显示了消息流,其中实线箭头包含用户函数,虚线箭头是内置消息。请注意,从 A 到 B 的前两条消息(remote() 和 to_here())可能以任何顺序到达 B,但最终的删除消息仅在以下情况发送:
B 确认
UserRRef {100, 1}(G2),并且Python GC 同意删除本地
UserRRef实例。这发生在 RRef 不再处于作用域并且可以被垃圾回收时。
用户将 RRef 作为参数与所有者共享#
import torch
import torch.distributed.rpc as rpc
# on worker A and worker B
def func(rref):
pass
# on worker A
rref = rpc.remote('B', torch.add, args=(torch.ones(2), 1))
# say the rref has RRefId 100 and ForkId 1
rpc.rpc_async('B', func, args=(rref, ))
在这种情况下,在 A 上创建 UserRRef 后,A 在后续的 RPC 调用中将其作为参数传递给 B。A 将保持 UserRRef {100, 1} 存活,直到收到 B 的确认(G2,而不是 RPC 调用的返回值)。这是必要的,因为 A 不应在所有先前消息都已收到之前发送删除消息,否则,OwnerRRef 可能会在被使用之前被删除,因为我们不保证消息投递顺序。这是通过创建一个 RRef 的子 ForkId,并将其保存在一个映射中,直到收到所有者确认子 ForkId。下图显示了消息流。
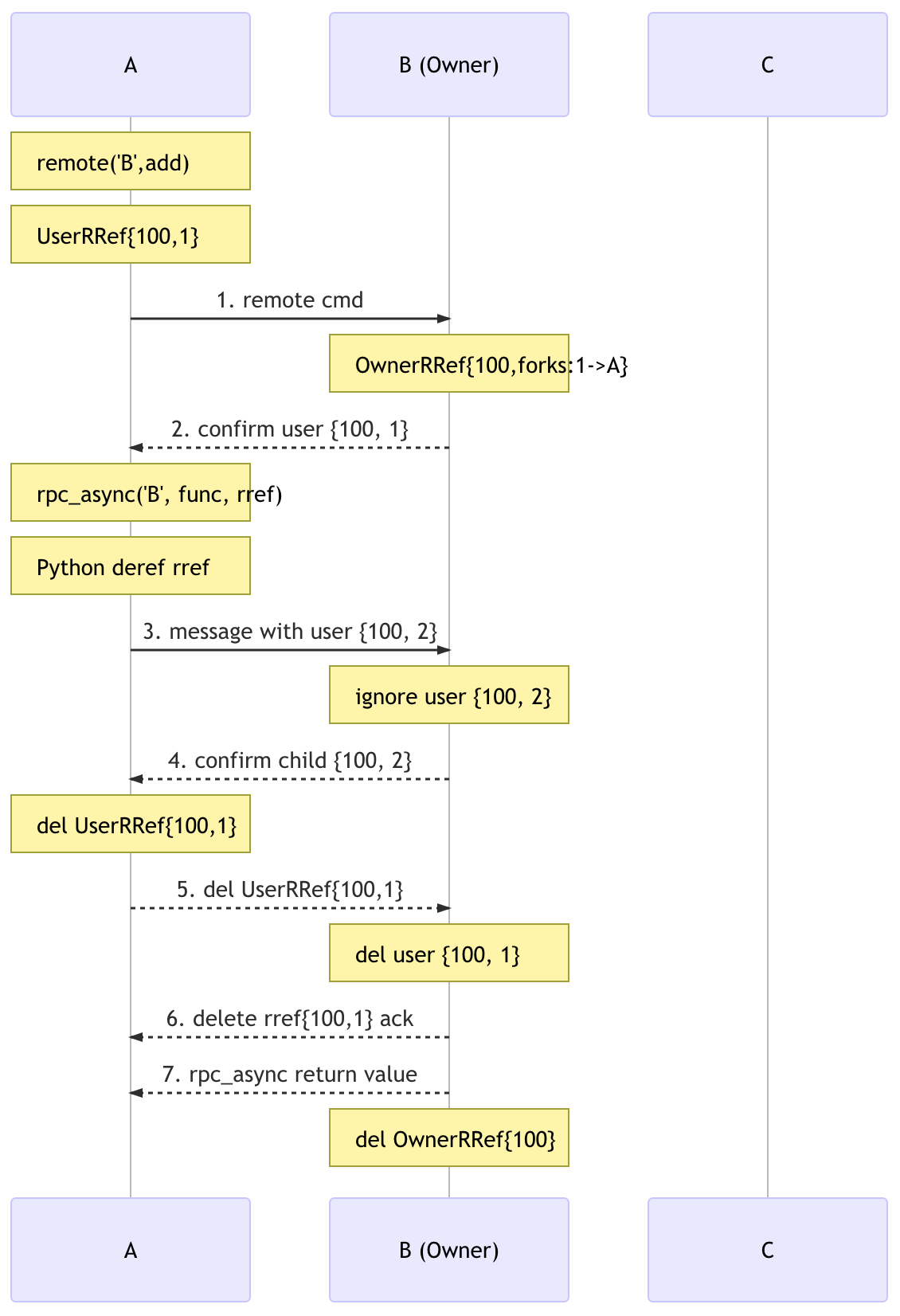
请注意,UserRRef 可以在 func 完成之前或甚至开始之前在 B 上被删除。但是这没关系,因为当 B 发送子 ForkId 的 ACK 时,它已经获取了 OwnerRRef 实例,这将防止它过早被删除。
所有者与用户共享 RRef#
从所有者到用户是最简单的情况,所有者可以在本地更新引用计数,并且不需要任何额外的控制消息来通知其他人。关于 G2,情况与父级立即收到所有者的 ACK 相同,因为父级就是所有者。
import torch
import torch.distributed.rpc as RRef, rpc
# on worker B and worker C
def func(rref):
pass
# on worker B, creating a local RRef
rref = RRef("data")
# say the rref has RRefId 100
dist.rpc_async('C', func, args=(rref, ))

上图显示了消息流。请注意,当 OwnerRRef 在 rpc_async 调用后退出作用域时,它不会被删除,因为内部有一个映射来保持其存活,如果存在任何已知的分叉,在这种情况下是 UserRRef {100, 1}。(G2)
用户之间共享 RRef#
这是最复杂的情况,其中调用方用户(父 UserRRef)、被调用方用户(子 UserRRef)以及所有者都需要参与。
import torch
import torch.distributed.rpc as rpc
# on worker A and worker C
def func(rref):
pass
# on worker A
rref = rpc.remote('B', torch.add, args=(torch.ones(2), 1))
# say the rref has RRefId 100 and ForkId 1
rpc.rpc_async('C', func, args=(rref, ))

当 C 从 A 接收到子 UserRRef 时,它会向所有者 B 发送一个分叉请求。稍后,当 B 确认 C 上的 UserRRef 时,C 将并行执行两个操作:1) 向 A 发送子 ACK,和 2) 运行用户提供的函数。在此期间,父级 (A) 将保持其 UserRRef {100, 1} 存活以实现 G2。
