torch.nested#
创建于: 2022年03月02日 | 最后更新于: 2025年06月14日
引言#
警告
PyTorch 中嵌套张量的 API 处于原型阶段,将在不久的将来发生变化。
嵌套张量允许将形状不规则的数据包含在内,并将其作为一个单一的张量进行操作。此类数据在底层以高效的打包表示形式存储,同时暴露标准的 PyTorch 张量接口以应用操作。
嵌套张量的一个常见应用是表示各种领域中存在的变长序列数据的批次,例如不同的句子长度、图像大小以及音频/视频片段长度。传统上,此类数据是通过将序列填充到批次内的最大长度,对填充后的形式执行计算,然后进行掩码以移除填充来处理的。这效率低下且容易出错,嵌套张量的出现旨在解决这些问题。
调用嵌套张量操作的 API 与常规 torch.Tensor 的 API 没有区别,允许与现有模型无缝集成,主要区别在于 输入的构造。
由于这是一项原型功能,支持的操作集是有限的,但正在不断增长。我们欢迎提交 issue、功能请求和贡献。有关贡献的更多信息可以在 此 Readme 中找到。
构造#
注意
PyTorch 中存在两种形式的嵌套张量,它们在构造时指定的布局上有所区别。布局可以是 torch.strided 或 torch.jagged。我们建议尽可能利用 torch.jagged 布局。虽然它目前只支持一个不规则维度,但它具有更好的操作覆盖率,正在积极开发中,并且与 torch.compile 集成良好。这些文档遵循此建议,并在全文中简称具有 torch.jagged 布局的嵌套张量为“NJTs”。
构造很简单,涉及将张量列表传递给 torch.nested.nested_tensor 构造函数。具有 torch.jagged 布局的嵌套张量(又名“NJT”)支持单个不规则维度。此构造函数将根据下方 data_layout 部分所述的布局,将输入张量复制到一个打包的、连续的内存块中。
>>> a, b = torch.arange(3), torch.arange(5) + 3
>>> a
tensor([0, 1, 2])
>>> b
tensor([3, 4, 5, 6, 7])
>>> nt = torch.nested.nested_tensor([a, b], layout=torch.jagged)
>>> print([component for component in nt])
[tensor([0, 1, 2]), tensor([3, 4, 5, 6, 7])]
列表中的每个张量必须具有相同的维数,但形状沿单个维度可以不同。如果输入组件的维度不匹配,构造函数将抛出错误。
>>> a = torch.randn(50, 128) # 2D tensor
>>> b = torch.randn(2, 50, 128) # 3D tensor
>>> nt = torch.nested.nested_tensor([a, b], layout=torch.jagged)
...
RuntimeError: When constructing a nested tensor, all tensors in list must have the same dim
在构造期间,可以通过常规关键字参数选择 dtype、device 以及是否需要梯度。
>>> nt = torch.nested.nested_tensor([a, b], layout=torch.jagged, dtype=torch.float32, device="cuda", requires_grad=True)
>>> print([component for component in nt])
[tensor([0., 1., 2.], device='cuda:0',
grad_fn=<UnbindBackwardAutogradNestedTensor0>), tensor([3., 4., 5., 6., 7.], device='cuda:0',
grad_fn=<UnbindBackwardAutogradNestedTensor0>)]
torch.nested.as_nested_tensor 可用于保留传递给构造函数的张量的 autograd 历史记录。当使用此构造函数时,梯度将通过嵌套张量流回原始组件。请注意,此构造函数仍会将输入组件复制到一个打包的、连续的内存块中。
>>> a = torch.randn(12, 512, requires_grad=True)
>>> b = torch.randn(23, 512, requires_grad=True)
>>> nt = torch.nested.as_nested_tensor([a, b], layout=torch.jagged, dtype=torch.float32)
>>> nt.sum().backward()
>>> a.grad
tensor([[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
...,
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.]])
>>> b.grad
tensor([[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
...,
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.]])
上述函数都创建了连续的 NJT,其中分配了一块内存来存储底层组件的打包形式(有关更多详细信息,请参见下方 data_layout 部分)。
还可以通过预先存在的填充密集张量创建非连续的 NJT 视图,从而避免内存分配和复制。 torch.nested.narrow() 是实现此目的的工具。
>>> padded = torch.randn(3, 5, 4)
>>> seq_lens = torch.tensor([3, 2, 5], dtype=torch.int64)
>>> nt = torch.nested.narrow(padded, dim=1, start=0, length=seq_lens, layout=torch.jagged)
>>> nt.shape
torch.Size([3, j1, 4])
>>> nt.is_contiguous()
False
请注意,嵌套张量充当原始填充密集张量的视图,引用相同的内存而不进行复制/分配。非连续 NJT 的操作支持略有限制,因此如果您遇到支持差距,始终可以使用 contiguous() 转换为连续 NJT。
数据布局和形状#
为了提高效率,嵌套张量通常将它们的张量组件打包到一个连续的内存块中,并维护附加的元数据来指定批次项的边界。对于 torch.jagged 布局,连续的内存块存储在 values 组件中,offsets 组件用于区分不规则维度的批次项边界。
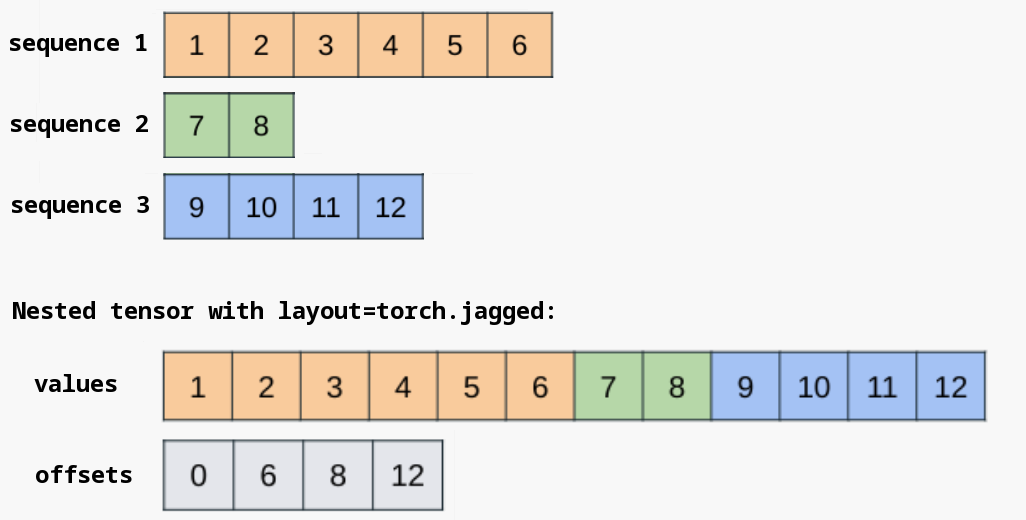
必要时可以直接访问底层的 NJT 组件。
>>> a = torch.randn(50, 128) # text 1
>>> b = torch.randn(32, 128) # text 2
>>> nt = torch.nested.nested_tensor([a, b], layout=torch.jagged, dtype=torch.float32)
>>> nt.values().shape # note the "packing" of the ragged dimension; no padding needed
torch.Size([82, 128])
>>> nt.offsets()
tensor([ 0, 50, 82])
直接从不规则的 values 和 offsets 成分构造 NJT 也可能有用;torch.nested.nested_tensor_from_jagged() 构造函数用于此目的。
>>> values = torch.randn(82, 128)
>>> offsets = torch.tensor([0, 50, 82], dtype=torch.int64)
>>> nt = torch.nested.nested_tensor_from_jagged(values=values, offsets=offsets)
NJT 具有明确定义的形状,其维度比其组件的维度大 1。不规则维度的底层结构由一个符号值表示(下方示例中的 j1)。
>>> a = torch.randn(50, 128)
>>> b = torch.randn(32, 128)
>>> nt = torch.nested.nested_tensor([a, b], layout=torch.jagged, dtype=torch.float32)
>>> nt.dim()
3
>>> nt.shape
torch.Size([2, j1, 128])
NJT 必须具有相同的不规则结构才能相互兼容。例如,要运行涉及两个 NJT 的二元运算,不规则结构必须匹配(即它们在形状中必须具有相同的 不规则形状符号)。在细节上,每个符号对应一个精确的 offsets 张量,因此两个 NJT 必须拥有相同的 offsets 张量才能相互兼容。
>>> a = torch.randn(50, 128)
>>> b = torch.randn(32, 128)
>>> nt1 = torch.nested.nested_tensor([a, b], layout=torch.jagged, dtype=torch.float32)
>>> nt2 = torch.nested.nested_tensor([a, b], layout=torch.jagged, dtype=torch.float32)
>>> nt1.offsets() is nt2.offsets()
False
>>> nt3 = nt1 + nt2
RuntimeError: cannot call binary pointwise function add.Tensor with inputs of shapes (2, j2, 128) and (2, j3, 128)
在上面的示例中,即使两个 NJT 的概念形状相同,它们也不共享对同一 offsets 张量的引用,因此它们的形状不同,并且不兼容。我们认识到这种行为是不直观的,并且正在努力为嵌套张量的 beta 版本放宽此限制。有关解决方法,请参阅本文档的 故障排除 部分。
除了 offsets 元数据外,NJT 还可以计算并缓存其组件的最小和最大序列长度,这对于调用特定内核(例如 SDPA)可能很有用。目前没有公共 API 来访问这些,但对于 beta 版本来说,这种情况将会改变。
支持的操作#
本节包含您可能觉得有用的常见嵌套张量操作列表。它并不详尽,因为 PyTorch 中有数千种操作。虽然今天嵌套张量支持其中的一个可观子集,但全面支持是一项艰巨的任务。嵌套张量的理想状态是完全支持非嵌套张量可用的所有 PyTorch 操作。为了帮助我们实现这一目标,请考虑
查看嵌套张量组件#
unbind() 允许您检索嵌套张量组件的视图。
>>> import torch
>>> a = torch.randn(2, 3)
>>> b = torch.randn(3, 3)
>>> nt = torch.nested.nested_tensor([a, b], layout=torch.jagged)
>>> nt.unbind()
(tensor([[-0.9916, -0.3363, -0.2799],
[-2.3520, -0.5896, -0.4374]]), tensor([[-2.0969, -1.0104, 1.4841],
[ 2.0952, 0.2973, 0.2516],
[ 0.9035, 1.3623, 0.2026]]))
>>> nt.unbind()[0] is not a
True
>>> nt.unbind()[0].mul_(3)
tensor([[ 3.6858, -3.7030, -4.4525],
[-2.3481, 2.0236, 0.1975]])
>>> nt.unbind()
(tensor([[-2.9747, -1.0089, -0.8396],
[-7.0561, -1.7688, -1.3122]]), tensor([[-2.0969, -1.0104, 1.4841],
[ 2.0952, 0.2973, 0.2516],
[ 0.9035, 1.3623, 0.2026]]))
请注意,nt.unbind()[0] 不是副本,而是底层内存的切片,它代表嵌套张量的第一个条目或组件。
转换为/从填充张量#
torch.nested.to_padded_tensor() 将 NJT 转换为具有指定填充值的填充密集张量。不规则维度将被填充到最大序列长度的大小。
>>> import torch
>>> a = torch.randn(2, 3)
>>> b = torch.randn(6, 3)
>>> nt = torch.nested.nested_tensor([a, b], layout=torch.jagged)
>>> padded = torch.nested.to_padded_tensor(nt, padding=4.2)
>>> padded
tensor([[[ 1.6107, 0.5723, 0.3913],
[ 0.0700, -0.4954, 1.8663],
[ 4.2000, 4.2000, 4.2000],
[ 4.2000, 4.2000, 4.2000],
[ 4.2000, 4.2000, 4.2000],
[ 4.2000, 4.2000, 4.2000]],
[[-0.0479, -0.7610, -0.3484],
[ 1.1345, 1.0556, 0.3634],
[-1.7122, -0.5921, 0.0540],
[-0.5506, 0.7608, 2.0606],
[ 1.5658, -1.1934, 0.3041],
[ 0.1483, -1.1284, 0.6957]]])
这可以作为一种解决方法来处理 NJT 支持的差距,但理想情况下,应尽可能避免此类转换,以获得最佳内存使用和性能,因为更高效的嵌套张量布局不会具体化填充。
反向转换可以使用 torch.nested.narrow() 完成,它将不规则结构应用于给定的密集张量以生成 NJT。请注意,默认情况下,此操作不会复制底层数据,因此输出的 NJT 通常是非连续的。如果需要连续的 NJT,明确调用 contiguous() 可能会有用。
>>> padded = torch.randn(3, 5, 4)
>>> seq_lens = torch.tensor([3, 2, 5], dtype=torch.int64)
>>> nt = torch.nested.narrow(padded, dim=1, length=seq_lens, layout=torch.jagged)
>>> nt.shape
torch.Size([3, j1, 4])
>>> nt = nt.contiguous()
>>> nt.shape
torch.Size([3, j2, 4])
形状操作#
嵌套张量支持广泛的形状操作,包括视图。
>>> a = torch.randn(2, 6)
>>> b = torch.randn(4, 6)
>>> nt = torch.nested.nested_tensor([a, b], layout=torch.jagged)
>>> nt.shape
torch.Size([2, j1, 6])
>>> nt.unsqueeze(-1).shape
torch.Size([2, j1, 6, 1])
>>> nt.unflatten(-1, [2, 3]).shape
torch.Size([2, j1, 2, 3])
>>> torch.cat([nt, nt], dim=2).shape
torch.Size([2, j1, 12])
>>> torch.stack([nt, nt], dim=2).shape
torch.Size([2, j1, 2, 6])
>>> nt.transpose(-1, -2).shape
torch.Size([2, 6, j1])
注意力机制#
由于变长序列是注意力机制的常见输入,嵌套张量支持重要的注意力算子 缩放点积注意力 (SDPA) 和 FlexAttention。有关 NJT 与 SDPA 用法的示例,请参见 此处;有关 NJT 与 FlexAttention 用法的示例,请参见 此处。
与 torch.compile 的用法#
NJT 被设计用于与 torch.compile() 结合使用以获得最佳性能,并且我们始终建议在可能的情况下使用 torch.compile() 配合 NJT 使用。NJT 可以直接使用,并且在作为编译函数的输入或模块,或在函数内部内联实例化时,都可以无缝工作,无需图中断。
注意
If you're not able to utilize ``torch.compile()`` for your use case, performance and memory
usage may still benefit from the use of NJTs, but it's not as clear-cut whether this will be
the case. It is important that the tensors being operated on are large enough so the
performance gains are not outweighed by the overhead of python tensor subclasses.
>>> import torch
>>> a = torch.randn(2, 3)
>>> b = torch.randn(4, 3)
>>> nt = torch.nested.nested_tensor([a, b], layout=torch.jagged)
>>> def f(x): return x.sin() + 1
...
>>> compiled_f = torch.compile(f, fullgraph=True)
>>> output = compiled_f(nt)
>>> output.shape
torch.Size([2, j1, 3])
>>> def g(values, offsets): return torch.nested.nested_tensor_from_jagged(values, offsets) * 2.
...
>>> compiled_g = torch.compile(g, fullgraph=True)
>>> output2 = compiled_g(nt.values(), nt.offsets())
>>> output2.shape
torch.Size([2, j1, 3])
请注意,NJT 支持 动态形状,以避免因不规则结构变化而引起的非必要重编译。
>>> a = torch.randn(2, 3)
>>> b = torch.randn(4, 3)
>>> c = torch.randn(5, 3)
>>> d = torch.randn(6, 3)
>>> nt1 = torch.nested.nested_tensor([a, b], layout=torch.jagged)
>>> nt2 = torch.nested.nested_tensor([c, d], layout=torch.jagged)
>>> def f(x): return x.sin() + 1
...
>>> compiled_f = torch.compile(f, fullgraph=True)
>>> output1 = compiled_f(nt1)
>>> output2 = compiled_f(nt2) # NB: No recompile needed even though ragged structure differs
如果您在使用 NJT + torch.compile 时遇到问题或遇到晦涩难懂的错误,请提交 PyTorch issue。在 torch.compile 中对子类进行全面支持是一项长期工作,目前可能还有一些不完善之处。
故障排除#
本节包含在使用嵌套张量时可能遇到的常见错误,以及这些错误的根本原因和建议的解决方法。
未实现的算子#
随着嵌套张量操作支持的增长,此错误变得越来越少见,但考虑到 PyTorch 中存在数千种操作,今天仍有可能遇到它。
NotImplementedError: aten.view_as_real.default
错误很简单;我们还没有为这个特定操作添加操作支持。如果您愿意,可以 自己贡献 一个实现,或者直接 请求 我们在未来的 PyTorch 版本中添加对该操作的支持。
不规则结构不兼容#
RuntimeError: cannot call binary pointwise function add.Tensor with inputs of shapes (2, j2, 128) and (2, j3, 128)
当调用一个对多个具有不兼容不规则结构的 NJT 进行操作的算子时,会发生此错误。目前,要求输入的 NJT 具有完全相同的 offsets 成分,才能具有相同的符号不规则结构符号(例如 j1)。
作为此情况的解决方法,可以直接从 values 和 offsets 成分构造 NJT。当两个 NJT 都引用相同的 offsets 成分时,它们被认为具有相同的不规则结构,因此兼容。
>>> a = torch.randn(50, 128)
>>> b = torch.randn(32, 128)
>>> nt1 = torch.nested.nested_tensor([a, b], layout=torch.jagged, dtype=torch.float32)
>>> nt2 = torch.nested.nested_tensor_from_jagged(values=torch.randn(82, 128), offsets=nt1.offsets())
>>> nt3 = nt1 + nt2
>>> nt3.shape
torch.Size([2, j1, 128])
torch.compile 中的数据相关操作#
torch._dynamo.exc.Unsupported: data dependent operator: aten._local_scalar_dense.default; to enable, set torch._dynamo.config.capture_scalar_outputs = True
调用在 torch.compile 中执行数据相关操作的算子时会发生此错误;这通常发生在需要检查 NJT 的 offsets 的值的算子上,以确定输出形状。例如
>>> a = torch.randn(50, 128)
>>> b = torch.randn(32, 128)
>>> nt = torch.nested.nested_tensor([a, b], layout=torch.jagged, dtype=torch.float32)
>>> def f(nt): return nt.chunk(2, dim=0)[0]
...
>>> compiled_f = torch.compile(f, fullgraph=True)
>>> output = compiled_f(nt)
在此示例中,对 NJT 的批次维度调用 chunk() 需要检查 NJT 的 offsets 数据,以区分打包的不规则维度中的批次项边界。作为解决方法,可以设置几个 torch.compile 标志
>>> torch._dynamo.config.capture_dynamic_output_shape_ops = True
>>> torch._dynamo.config.capture_scalar_outputs = True
在设置了这些标志后,如果仍然看到数据相关算子错误,请提交 PyTorch issue。 torch.compile() 的这一领域仍在大力开发中,NJT 支持的某些方面可能尚不完善。
贡献#
如果您想为嵌套张量的开发做出贡献,最有效的方式之一是为当前不支持的 PyTorch 操作添加嵌套张量支持。这个过程通常包括几个简单的步骤:
确定要添加的操作名称;这应该是类似于
aten.view_as_real.default的名称。此操作的签名可以在aten/src/ATen/native/native_functions.yaml中找到。在
torch/nested/_internal/ops.py中注册操作实现,遵循那里为其他操作建立的模式。使用native_functions.yaml中的签名进行模式验证。
实现操作的最常见方法是解开 NJT 到其组件,对底层 values 缓冲区重新调度操作,并将相关的 NJT 元数据(包括 offsets)传播到新的输出 NJT。如果操作的输出预期具有与输入不同的形状,则必须计算新的 offsets 等元数据。
当操作应用于批次维度或不规则维度时,这些技巧可以帮助快速获得可行的实现:
对于非批次wise 操作,基于
unbind()的回退应该有效。对于不规则维度的操作,可以考虑转换为填充密集张量,并选择一个不会负面影响输出的填充值,运行操作,然后转换回 NJT。在
torch.compile中,这些转换可以被融合,以避免具体化填充的中间结果。
构造和转换函数的详细文档#
- torch.nested.nested_tensor(tensor_list, *, dtype=None, layout=None, device=None, requires_grad=False, pin_memory=False)[source]#
从
tensor_list(一个张量列表)构造一个没有 autograd 历史记录的嵌套张量(也称为“叶张量”,请参阅 Autograd 机制)。- 参数
tensor_list (List[array_like]) – 一个张量列表,或任何可以传递给 torch.tensor 的内容,
维度。 (列表中的每个元素具有相同的) –
- 关键字参数
dtype (
torch.dtype, optional) – 返回的嵌套张量的期望类型。默认值:如果为 None,则与列表中的最左边张量具有相同的torch.dtype。layout (
torch.layout, optional) – 返回的嵌套张量的期望布局。仅支持 strided 和 jagged 布局。默认值:如果为 None,则为 strided 布局。device (
torch.device, optional) – 返回的嵌套张量的期望设备。默认值:如果为 None,则与列表中的最左边张量具有相同的torch.devicerequires_grad (bool, optional) – 如果 autograd 应该记录返回的嵌套张量上的操作。默认值:
False。pin_memory (bool, optional) – 如果设置,返回的嵌套张量将被分配到固定内存中。仅适用于 CPU 张量。默认值:
False。
- 返回类型
示例
>>> a = torch.arange(3, dtype=torch.float, requires_grad=True) >>> b = torch.arange(5, dtype=torch.float, requires_grad=True) >>> nt = torch.nested.nested_tensor([a, b], requires_grad=True) >>> nt.is_leaf True
- torch.nested.nested_tensor_from_jagged(values, offsets=None, lengths=None, jagged_dim=None, min_seqlen=None, max_seqlen=None)[source]#
从给定的不规则组件构造一个不规则布局的嵌套张量。不规则布局包含一个必需的 values 缓冲区,其中不规则维度被打包成单个维度。offsets/lengths 元数据决定了该维度如何被分割成批次元素,并期望它们被分配在与 values 缓冲区相同的设备上。
- 期望的元数据格式
offsets: 位于打包维度内的索引,将打包维度分割成大小不等的批次元素。例如:[0, 2, 3, 6] 表示一个大小为 6 的打包不规则维度应被概念上分割成长度为 [2, 1, 3] 的批次元素。请注意,为了方便内核(即 shape batch_size + 1)操作,需要开始和结束偏移量。
lengths: 批次元素的长度,shape == batch_size。例如:[2, 1, 3] 表示一个大小为 6 的打包不规则维度应被概念上分割成长度为 [2, 1, 3] 的批次元素。
请注意,同时提供 offsets 和 lengths 会很有用。这描述了一个带有“空隙”的嵌套张量,其中 offsets 指示每个批次项的起始位置,而 length 指定元素的总数(参见下面的示例)。
返回的不规则布局嵌套张量将是输入 values 张量的视图。
- 参数
values (
torch.Tensor) – 底层缓冲区,形状为 (sum_B(*), D_1, …, D_N)。不规则维度被打包成单个维度,使用 offsets/lengths 元数据区分批次元素。offsets (optional
torch.Tensor) – 不规则维度的偏移量,形状为 B + 1。lengths (optional
torch.Tensor) – 批次元素的长度,形状为 B。jagged_dim (optional python:int) – 指示 values 中哪个维度是不规则打包维度。必须大于等于 1,因为批次维度(dim=0)不能是不规则的。如果为 None,则设置为 dim=1(即批次维度之后的第一个维度)。默认值:None
min_seqlen (optional python:int) – 如果设置,则使用指定的值作为返回嵌套张量的缓存最小序列长度。这可以作为一种有用的替代方案来按需计算此值,可能避免 GPU -> CPU 同步。默认值:None
max_seqlen (optional python:int) – 如果设置,则使用指定的值作为返回嵌套张量的缓存最大序列长度。这可以作为一种有用的替代方案来按需计算此值,可能避免 GPU -> CPU 同步。默认值:None
- 返回类型
示例
>>> values = torch.randn(12, 5) >>> offsets = torch.tensor([0, 3, 5, 6, 10, 12]) >>> nt = nested_tensor_from_jagged(values, offsets) >>> # 3D shape with the middle dimension jagged >>> nt.shape torch.Size([5, j2, 5]) >>> # Length of each item in the batch: >>> offsets.diff() tensor([3, 2, 1, 4, 2]) >>> values = torch.randn(6, 5) >>> offsets = torch.tensor([0, 2, 3, 6]) >>> lengths = torch.tensor([1, 1, 2]) >>> # NT with holes >>> nt = nested_tensor_from_jagged(values, offsets, lengths) >>> a, b, c = nt.unbind() >>> # Batch item 1 consists of indices [0, 1) >>> torch.equal(a, values[0:1, :]) True >>> # Batch item 2 consists of indices [2, 3) >>> torch.equal(b, values[2:3, :]) True >>> # Batch item 3 consists of indices [3, 5) >>> torch.equal(c, values[3:5, :]) True
- torch.nested.as_nested_tensor(ts, dtype=None, device=None, layout=None)[source]#
构造一个保留 autograd 历史记录的嵌套张量,它来自一个张量或一个张量列表/元组。
如果传入嵌套张量,它将被直接返回,除非设备/dtype/布局不同。请注意,转换设备/dtype 将导致复制,而转换布局在此函数中目前不受支持。
如果传入非嵌套张量,它将被视为具有一致大小的组件批次。如果传入的设备/dtype 与输入的设备/dtype 不同,或者如果输入是非连续的,则会发生复制。否则,将直接使用输入的存储。
如果提供张量列表,在构造嵌套张量时,列表中的张量始终会被复制。
- 参数
ts (Tensor 或 List[Tensor] 或 Tuple[Tensor]) – 要视为嵌套张量的张量,或具有相同 ndim 的张量列表/元组
- 关键字参数
dtype (
torch.dtype, optional) – 返回的嵌套张量的期望类型。默认值:如果为 None,则与列表中的最左边张量具有相同的torch.dtype。device (
torch.device, optional) – 返回的嵌套张量的期望设备。默认值:如果为 None,则与列表中的最左边张量具有相同的torch.devicelayout (
torch.layout, optional) – 返回的嵌套张量的期望布局。仅支持 strided 和 jagged 布局。默认值:如果为 None,则为 strided 布局。
- 返回类型
示例
>>> a = torch.arange(3, dtype=torch.float, requires_grad=True) >>> b = torch.arange(5, dtype=torch.float, requires_grad=True) >>> nt = torch.nested.as_nested_tensor([a, b]) >>> nt.is_leaf False >>> fake_grad = torch.nested.nested_tensor([torch.ones_like(a), torch.zeros_like(b)]) >>> nt.backward(fake_grad) >>> a.grad tensor([1., 1., 1.]) >>> b.grad tensor([0., 0., 0., 0., 0.]) >>> c = torch.randn(3, 5, requires_grad=True) >>> nt2 = torch.nested.as_nested_tensor(c)
- torch.nested.to_padded_tensor(input, padding, output_size=None, out=None) Tensor#
通过填充
input嵌套张量返回一个新的(非嵌套)张量。前面的条目将用嵌套数据填充,而后面的条目将进行填充。警告
to_padded_tensor()始终复制底层数据,因为嵌套张量和非嵌套张量在内存布局上有所不同。- 参数
padding (float) – 后面条目的填充值。
- 关键字参数
示例
>>> nt = torch.nested.nested_tensor([torch.randn((2, 5)), torch.randn((3, 4))]) nested_tensor([ tensor([[ 1.6862, -1.1282, 1.1031, 0.0464, -1.3276], [-1.9967, -1.0054, 1.8972, 0.9174, -1.4995]]), tensor([[-1.8546, -0.7194, -0.2918, -0.1846], [ 0.2773, 0.8793, -0.5183, -0.6447], [ 1.8009, 1.8468, -0.9832, -1.5272]]) ]) >>> pt_infer = torch.nested.to_padded_tensor(nt, 0.0) tensor([[[ 1.6862, -1.1282, 1.1031, 0.0464, -1.3276], [-1.9967, -1.0054, 1.8972, 0.9174, -1.4995], [ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]], [[-1.8546, -0.7194, -0.2918, -0.1846, 0.0000], [ 0.2773, 0.8793, -0.5183, -0.6447, 0.0000], [ 1.8009, 1.8468, -0.9832, -1.5272, 0.0000]]]) >>> pt_large = torch.nested.to_padded_tensor(nt, 1.0, (2, 4, 6)) tensor([[[ 1.6862, -1.1282, 1.1031, 0.0464, -1.3276, 1.0000], [-1.9967, -1.0054, 1.8972, 0.9174, -1.4995, 1.0000], [ 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000], [ 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000]], [[-1.8546, -0.7194, -0.2918, -0.1846, 1.0000, 1.0000], [ 0.2773, 0.8793, -0.5183, -0.6447, 1.0000, 1.0000], [ 1.8009, 1.8468, -0.9832, -1.5272, 1.0000, 1.0000], [ 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000]]]) >>> pt_small = torch.nested.to_padded_tensor(nt, 2.0, (2, 2, 2)) RuntimeError: Value in output_size is less than NestedTensor padded size. Truncation is not supported.
- torch.nested.masked_select(tensor, mask)[source]#
给定一个 strided 张量输入和一个 strided mask,构造一个嵌套张量,结果的不规则布局嵌套张量将保留 mask 等于 True 的值。mask 的维度被保留并用 offsets 表示,这与
masked_select()不同,后者将输出折叠到一维张量。Args: tensor (
torch.Tensor): 用于从其中构造不规则布局嵌套张量的 strided 张量。 mask (torch.Tensor): 应用于 tensor 输入的 strided mask 张量示例
>>> tensor = torch.randn(3, 3) >>> mask = torch.tensor([[False, False, True], [True, False, True], [False, False, True]]) >>> nt = torch.nested.masked_select(tensor, mask) >>> nt.shape torch.Size([3, j4]) >>> # Length of each item in the batch: >>> nt.offsets().diff() tensor([1, 2, 1]) >>> tensor = torch.randn(6, 5) >>> mask = torch.tensor([False]) >>> nt = torch.nested.masked_select(tensor, mask) >>> nt.shape torch.Size([6, j5]) >>> # Length of each item in the batch: >>> nt.offsets().diff() tensor([0, 0, 0, 0, 0, 0])
- 返回类型
- torch.nested.narrow(tensor, dim, start, length, layout=torch.strided)[source]#
从
tensor(一个 strided 张量)构造一个嵌套张量(可能是视图)。这遵循与 torch.Tensor.narrow 类似语义,其中在dim维度上,新的嵌套张量只显示区间 [start, start+length) 中的元素。由于嵌套表示允许每个“行”在该维度上具有不同的 start 和 length,因此start和length也可以是形状为 tensor.shape[0] 的张量。根据您为嵌套张量使用的布局,会有一些差异。如果使用 strided 布局,torch.narrow 将把窄化数据复制到一个具有 strided 布局的连续 NT 中,而 jagged 布局的 narrow() 将创建您原始 strided 张量的非连续视图。这种特定的表示形式对于表示 Transformer 模型中的 kv-caches 非常有用,因为专门的 SDPA 内核可以轻松处理该格式,从而提高性能。
- 参数
tensor (
torch.Tensor) – 一个 strided 张量,如果使用 jagged 布局,它将被用作嵌套张量的底层数据,或者对于 strided 布局将被复制。dim (int) – narrow 操作应用的维度。对于 jagged 布局仅支持 dim=1,而 strided 支持所有维度
start (Union[int,
torch.Tensor]) – narrow 操作的起始元素length (Union[int,
torch.Tensor]) – narrow 操作中包含的元素数量
- 关键字参数
layout (
torch.layout, optional) – 返回的嵌套张量的期望布局。仅支持 strided 和 jagged 布局。默认值:如果为 None,则为 strided 布局。- 返回类型
示例
>>> starts = torch.tensor([0, 1, 2, 3, 4], dtype=torch.int64) >>> lengths = torch.tensor([3, 2, 2, 1, 5], dtype=torch.int64) >>> narrow_base = torch.randn(5, 10, 20) >>> nt_narrowed = torch.nested.narrow(narrow_base, 1, starts, lengths, layout=torch.jagged) >>> nt_narrowed.is_contiguous() False
